


































































![[Dernière mise à jour à 20h15] Fortnite pour iOS n'est plus disponible en Europe en attendant sa validation par Apple aux États-Unis](https://cdn.mgig.fr/2025/05/mga-042cb0aa-w375-w1500-w750_accroche.jpg)

![Apple Pay et Plans ont quelques soucis ce soir [20h50 : c'est résolu]](https://cdn.mgig.fr/2025/05/mga-8bd08c97-w375-w1500-w750_accroche.jpg)







![J'ai vu le futur du solaire à Munich [VLOG]](https://lokan.fr/wp-content/uploads/2025/05/lokan-salon-solaire-munich-1280x853.jpeg)


































































































![Qu’est-ce que la stratégie 3-2-1-1-0 en cybersécurité ? [Sponso]](https://c0.lestechnophiles.com/www.numerama.com/wp-content/uploads/2025/05/banner-1920.jpg?resize=1600,900&key=c31aa8b0&watermark)








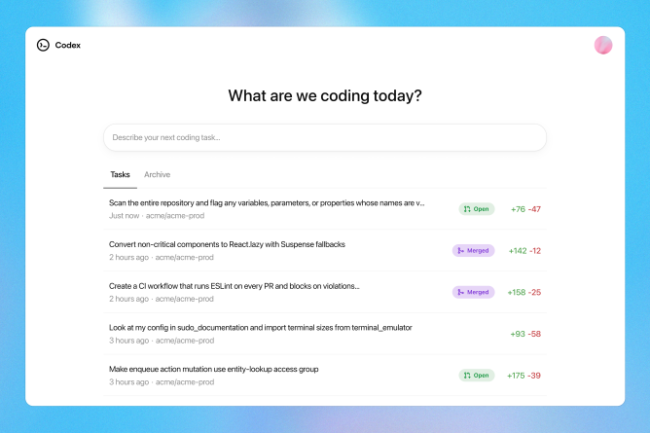
Show HN: KVSplit – Run 2-3x longer contexts on Apple Silicon
I discovered that in LLM inference, keys and values in the KV cache have very different quantization sensitivities. Keys need higher precision than values to maintain quality.I patched llama.cpp to enable different bit-widths for keys vs. values on Apple Silicon. The results are surprising:- K8V4 (8-bit keys, 4-bit values): 59% memory reduction with only 0.86% perplexity loss - K4V8 (4-bit keys, 8-bit values): 59% memory reduction but 6.06% perplexity loss - The configurations use the same number of bits, but K8V4 is 7× better for qualityThis means you can run LLMs with 2-3× longer context on the same Mac. Memory usage scales with sequence length, so savings compound as context grows.Implementation was straightforward: 1. Added --kvq-key and --kvq-val flags to llama.cpp 2. Applied existing quantization logic separately to K and V tensors 3. Validated with perplexity metrics across context lengths 4. Used Metal for acceleration (with -mlong-calls flag to avoid vectorization issues)Benchmarked on an M4 MacBook Pro running TinyLlama with 8K context windows. Compatible with Metal/MPS and optimized for Apple Silicon.GitHub: https://github.com/dipampaul17/KVSplit Comments URL: https://news.ycombinator.com/item?id=44009321 Points: 112 # Comments: 11
I discovered that in LLM inference, keys and values in the KV cache have very different quantization sensitivities. Keys need higher precision than values to maintain quality.
I patched llama.cpp to enable different bit-widths for keys vs. values on Apple Silicon. The results are surprising:
- K8V4 (8-bit keys, 4-bit values): 59% memory reduction with only 0.86% perplexity loss - K4V8 (4-bit keys, 8-bit values): 59% memory reduction but 6.06% perplexity loss - The configurations use the same number of bits, but K8V4 is 7× better for quality
This means you can run LLMs with 2-3× longer context on the same Mac. Memory usage scales with sequence length, so savings compound as context grows.
Implementation was straightforward: 1. Added --kvq-key and --kvq-val flags to llama.cpp 2. Applied existing quantization logic separately to K and V tensors 3. Validated with perplexity metrics across context lengths 4. Used Metal for acceleration (with -mlong-calls flag to avoid vectorization issues)
Benchmarked on an M4 MacBook Pro running TinyLlama with 8K context windows. Compatible with Metal/MPS and optimized for Apple Silicon.
GitHub: https://github.com/dipampaul17/KVSplit
Comments URL: https://news.ycombinator.com/item?id=44009321
Points: 112
# Comments: 11
