































































 (1).jpg)





























































![Bilan 2024 : Les nouveautés Agorapulse pour booster votre stratégie sociale [Infographie]](https://www.agorapulse.com/fr/blog/wp-content/uploads/sites/3/2025/03/FR-New-Favorite-Agorapulse-Features-of-2024-Blogpost-Header-scaled.jpg?#)












































![Et si cette entreprise française qui sécurise les sites sensibles sécurisait aussi votre foyer ? [Sponso]](https://c0.lestechnophiles.com/www.numerama.com/wp-content/uploads/2025/04/installation-videosurveillance.jpg?resize=1600,900&key=b2482d73&watermark)








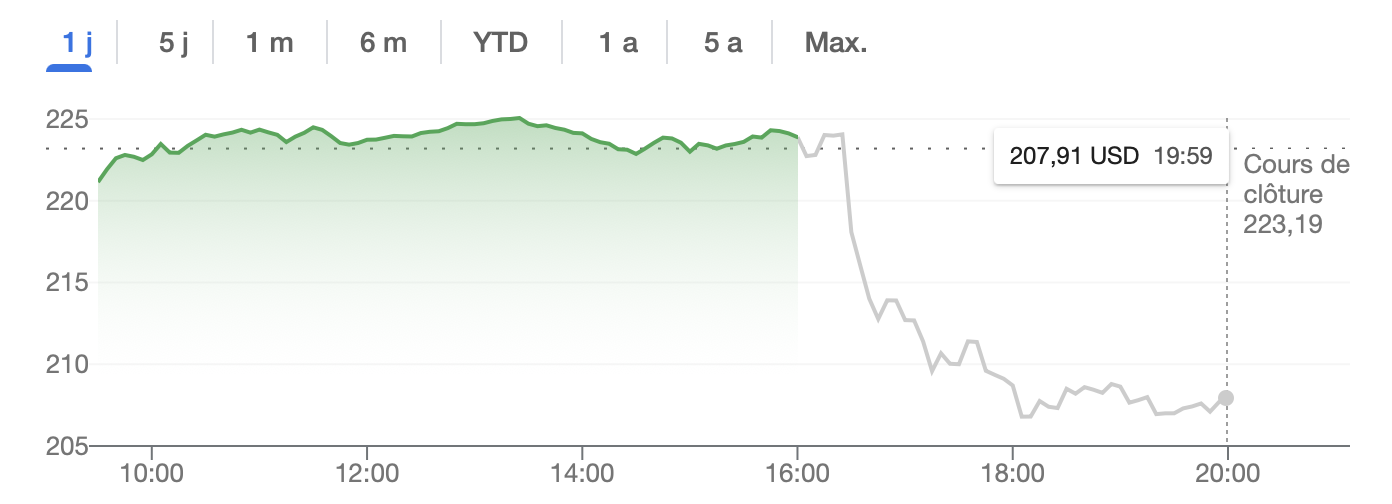
Wikimedia est submergé par le trafic des robots d'IA, les crawlers consommant 65 % des ressources, afin de collecter des données d'entraînement pour les modèles d'IA
Wikimedia est submergé par le trafic des robots d'IA, les crawlers consommant 65 % des ressources, afin de collecter des données d'entraînement pour les modèles d'IA.La fondation Wikimedia a annoncé que le scraping incessant de l'IA mettait à rude épreuve les serveurs de Wikipédia. Des robots automatisés à la recherche de données d'entraînement de modèles d'IA pour des LLM ont aspiré des téraoctets de données, augmentant de 50 % la bande passante utilisée par la fondation pour télécharger des contenus...

Wikimedia est submergé par le trafic des robots d'IA, les crawlers consommant 65 % des ressources, afin de collecter des données d'entraînement pour les modèles d'IA.
La fondation Wikimedia a annoncé que le scraping incessant de l'IA mettait à rude épreuve les serveurs de Wikipédia. Des robots automatisés à la recherche de données d'entraînement de modèles d'IA pour des LLM ont aspiré des téraoctets de données, augmentant de 50 % la bande passante utilisée par la fondation pour télécharger des contenus...
La fondation Wikimedia a annoncé que le scraping incessant de l'IA mettait à rude épreuve les serveurs de Wikipédia. Des robots automatisés à la recherche de données d'entraînement de modèles d'IA pour des LLM ont aspiré des téraoctets de données, augmentant de 50 % la bande passante utilisée par la fondation pour télécharger des contenus...
