



































































![Sonos Abandons Streaming Device That Aimed to Rival Apple TV [Report]](https://www.iclarified.com/images/news/96703/96703/96703-640.jpg)
![HomePod With Display Delayed to Sync With iOS 19 Redesign [Kuo]](https://www.iclarified.com/images/news/96702/96702/96702-640.jpg)
![iPhone 17 Air to Measure 9.5mm Thick Including Camera Bar [Rumor]](https://www.iclarified.com/images/news/96699/96699/96699-640.jpg)





































































































_Andrii_Yalanskyi_Alamy.jpg?#)




























































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)














































































































































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
-Rainbow-Six-Siege-X---Official-Gameplay-Trailer-00-01-00.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
























































Graph database vs relational vs vector vs NoSQL
Graph Databases vs Relational Databases Relational databases store data in tables with predefined schemas and rely on joins to establish relationships, which can become inefficient for complex queries. As data volume and relationship complexity grow, relational databases require increasingly expensive joins, leading to slower queries and performance bottlenecks. Graph databases mitigate this by storing relationships as first-class entities, allowing direct traversal of connected nodes without the need for costly joins. This results in significantly faster queries and better scalability for complex, interconnected data. Graph Databases vs Vector Databases In vector databases, data is stored as high-dimensional vector embeddings, which are numerical representations generated by machine learning models to capture the features of data. When querying, the input is converted into a vector embedding, and similarity searches are performed between the query vector and stored embeddings using distance metrics like cosine similarity or Euclidean distance to retrieve the most relevant results. Most vector databases cannot explicitly capture relationships between data points, unlike graph databases. This means they struggle with queries that require understanding structured relationships, such as tracing multi-hop connections, identifying dependencies between entities, or performing path-based reasoning. While vector databases excel in finding similar items based on feature proximity, they are not designed for scenarios where relationship-driven insights, such as network analysis or hierarchical dependencies, are crucial. Modern graph databases, like FalkorDB, allow you to store vector embeddings along with nodes and relationships between nodes, thereby giving you the best of both worlds. Graph Databases vs NoSQL Databases Traditional NoSQL databases store data in JSON, key-value, column-family, or document formats, requiring developers to handle complex relationship queries programmatically since these databases are primarily designed for scalability and flexibility rather than structured relationships. While NoSQL databases excel at handling unstructured or semi-structured data and large-scale distributed storage, they often struggle with efficiently querying deeply connected data. Since graph databases also allow you to store metadata with nodes, you get the benefits that NoSQL databases offer, without sacrificing the ability to perform complex relationship queries.
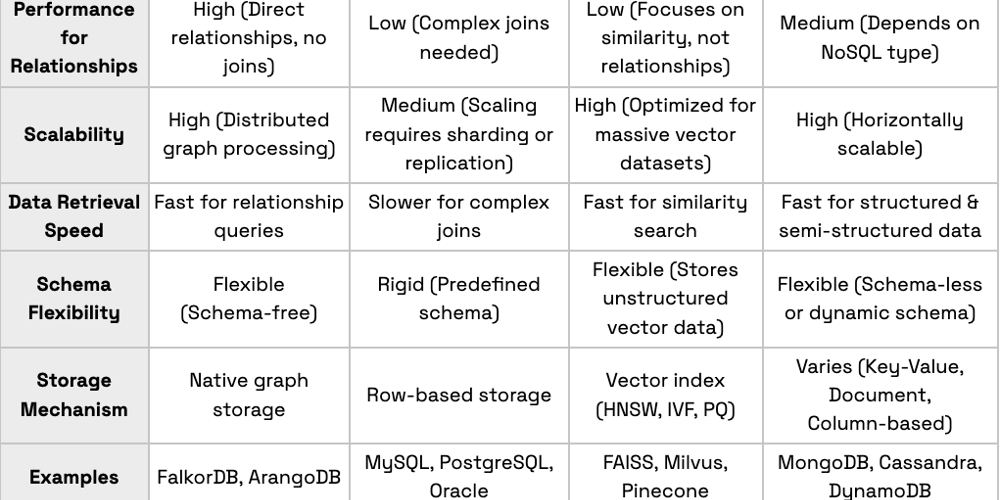
Graph Databases vs Relational Databases
Relational databases store data in tables with predefined schemas and rely on joins to establish relationships, which can become inefficient for complex queries. As data volume and relationship complexity grow, relational databases require increasingly expensive joins, leading to slower queries and performance bottlenecks. Graph databases mitigate this by storing relationships as first-class entities, allowing direct traversal of connected nodes without the need for costly joins. This results in significantly faster queries and better scalability for complex, interconnected data.
Graph Databases vs Vector Databases
In vector databases, data is stored as high-dimensional vector embeddings, which are numerical representations generated by machine learning models to capture the features of data. When querying, the input is converted into a vector embedding, and similarity searches are performed between the query vector and stored embeddings using distance metrics like cosine similarity or Euclidean distance to retrieve the most relevant results.
Most vector databases cannot explicitly capture relationships between data points, unlike graph databases. This means they struggle with queries that require understanding structured relationships, such as tracing multi-hop connections, identifying dependencies between entities, or performing path-based reasoning. While vector databases excel in finding similar items based on feature proximity, they are not designed for scenarios where relationship-driven insights, such as network analysis or hierarchical dependencies, are crucial.
Modern graph databases, like FalkorDB, allow you to store vector embeddings along with nodes and relationships between nodes, thereby giving you the best of both worlds.
Graph Databases vs NoSQL Databases
Traditional NoSQL databases store data in JSON, key-value, column-family, or document formats, requiring developers to handle complex relationship queries programmatically since these databases are primarily designed for scalability and flexibility rather than structured relationships. While NoSQL databases excel at handling unstructured or semi-structured data and large-scale distributed storage, they often struggle with efficiently querying deeply connected data.
Since graph databases also allow you to store metadata with nodes, you get the benefits that NoSQL databases offer, without sacrificing the ability to perform complex relationship queries.







