





















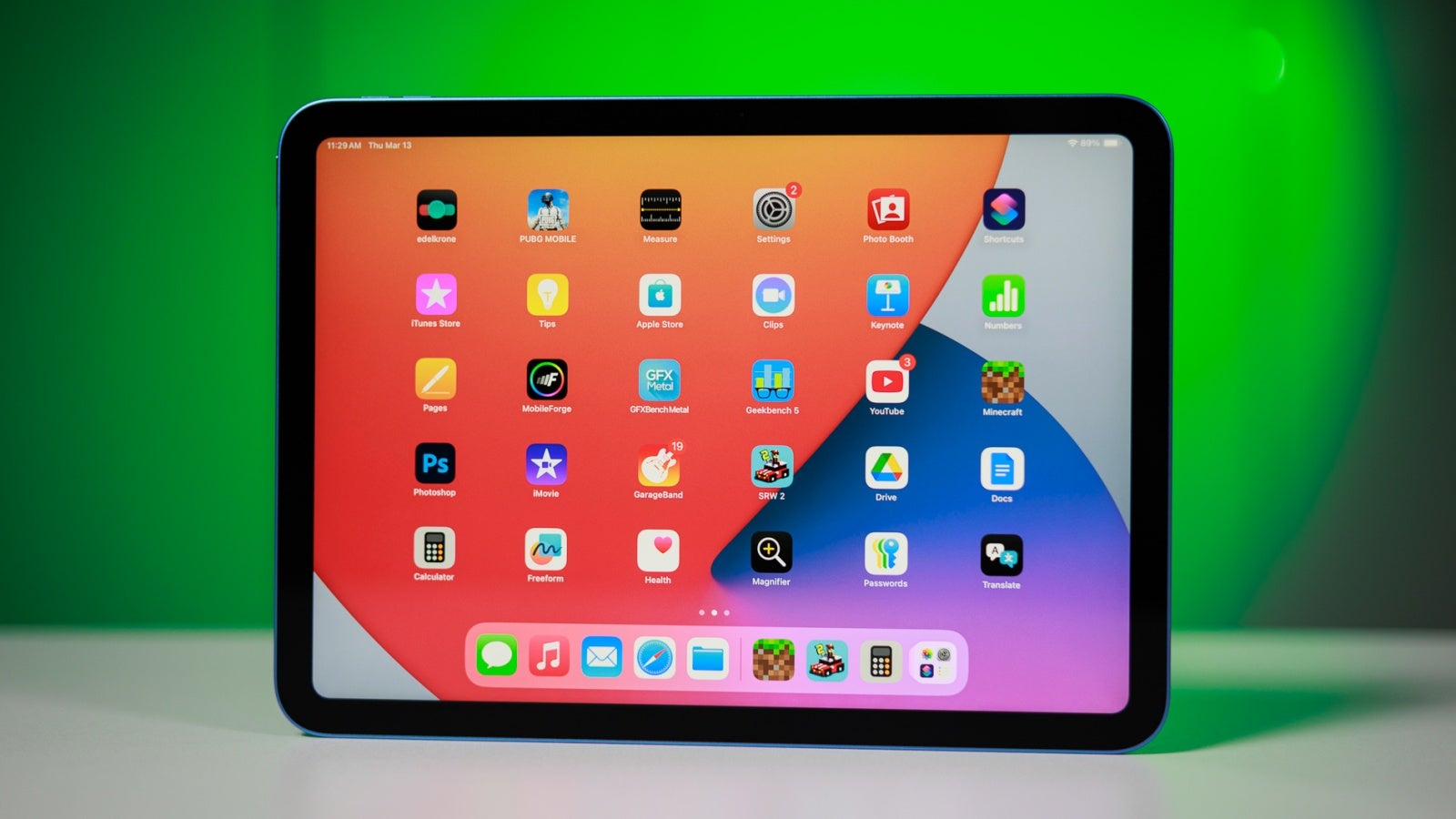













































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)








































































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)



































































































































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

Data Labeling for LLMs: The Key to Safer and More Effective AI Models
However, despite their impressive human-like intelligence, they are far from infallible, often producing incorrect, misleading, or even harmful outputs. This necessitates human oversight to ensure their safety and reliability. This article explores the role of data labeling for LLMs and how it bridges the gap between the potential of Gen AI models and their reliability… Continue reading Data Labeling for LLMs: The Key to Safer and More Effective AI Models The post Data Labeling for LLMs: The Key to Safer and More Effective AI Models appeared first on Cogitotech.

However, despite their impressive human-like intelligence, they are far from infallible, often producing incorrect, misleading, or even harmful outputs. This necessitates human oversight to ensure their safety and reliability. This article explores the role of data labeling for LLMs and how it bridges the gap between the potential of Gen AI models and their reliability and applicability in real-world scenarios.
What is Data Labeling for LLMs or Generative AI?
Data labeling refers to the process of identifying raw data and adding labels to train a machine language model, enabling it to make accurate predictions based on the context. Labeled data serves as the ground truth for training, validating, and testing large language models.
The previous generation of large language models primarily relied on unsupervised or self-supervised learning, focusing on predicting the next token in a sequence. In contrast, the new generation of LLMs is fine-tuned with labeled data, aligning their outputs with human values and preferences or adapting them to specific tasks.
Once a foundation model is built, additional labeled training data is required to optimize model performance for specific tasks and use cases.
Importance of Data Labeling in Training LLMs
Pre-trained language models often exhibit gaps between desired outputs and real-world performance. Human labelers play a crucial role at various training stages in preparing AI models for practical applications. Rather than training the entire model from scratch, labeled data help optimize LLMs for human preferences and specific domains. Here is how various LLM training stages benefit from data annotation, improving performance, accuracy, and practical usability.
- Pre-training: While models are not directly trained on annotated data during the pre-training phase, labeled data can improve performance. Human annotators collect, curate, and clean training datasets, removing noise and errors to boost reliability.
- LLM Fine-tuning: Labeled data is critical to customizing foundation models for specific domains or use cases. Businesses can fine-tune LLMs with their proprietary data to optimize performance in targeted fields. For example, a general-purpose model can be tailored for the medical domain by training it on annotated clinical texts, images, medical research, electronic health records, and specialized terminology.
- Model Evaluation: To ensure their performance and reliability, large language models require objective and standardized evaluation. Manually labeled data serves as a ‘ground truth’, providing a benchmark for evaluating accuracy, helping it learn the right patterns, and making accurate predictions on new datasets.
Steps to Fine-Tune an LLM with Labeled Data
Here are the steps to refine LLMs using annotated data:
Supervised Fine-tuning (SFT)
SFT uses prompt-response pairs created by human annotators to train foundation models. These examples teach models to follow human-provided instructions, with training dataset containing instructions with desired responses.

Reinforcement Learning with Human Feedback (RLHF)
Supervised fine-tuning is limited by the amount of data humans can label. Therefore, instead of labeling every data point, it is wise to have annotators rank model outputs from best to the least desirable match based on correctness, helpfulness, and alignment with human preferences. Since RLHF involves humans only ranking responses, it accelerates data generation process, allowing models to be trained on much larger datasets. It then enables models to automatically score new responses without further human involvement.
Why Cogito Tech is the Right Platform for LLM Data Labeling
Cogito Tech’s human-in-the-loop data annotation solutions have supported leading generative AI models for years. We provide expert workforces to train, fine-tune, evaluate, and ensure the safety of foundation models and LLMs. From augmenting data to train a model to tailoring it for specific use cases, our comprehensive annotation services boost multimodal AI performance by covering text, image, audio, and video datasets. Cogito Tech’s LLM data labeling services include:
Pre-trained Model Fine-tuning: Cogito Tech’s brings diverse skills to create pairs, optimizing next-token predictors or pre-trained models to generate accurate and contextually relevant responses across various disciplines.
Creating Human Feedback Reward Model: Domain experts create a reward system to evaluate model response based on accuracy, appropriateness, and helpfulness. For example, human annotators evaluate the LLM-generated jokes for relevance, humor, and clarity. The dataset containing human-rated responses serve as the ‘ground truth’ for evaluating outputs.

Data Augmentation: We use SME-driven syntactic and semantic analysis to expand training data size and diversity. The team improves data quality using advanced techniques such as text perturbation, synthetic data generation, back translation. Multi-level validation ensures accurate paraphrasing and summarization.
Model Evaluation: We employ advanced evaluation methods like Likert scale ratings, A/B testing, and domain-specific review to offer unbiased feedback. Furthermore, ongoing monitoring and fine-tuning ensure consistent performance, enabling models to excel in real-world applications.
Final Words
Data labeling is the key to realizing the full potential of large language models in various ways. Meticulously curated and labeled data bridges the gap between AI models’ capabilities and their real-world applications, ensuring accuracy and alignment with human values. With a human-in-the-loop approach, Cogito Tech fine-tunes and evaluates models to ensure they are safer and more effective, performing with precision and trustworthiness.
The post Data Labeling for LLMs: The Key to Safer and More Effective AI Models appeared first on Cogitotech.