






























































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)




















































IAs erram dados de notícias em mais de 60% do tempo
Estudo da Columbia Journal Review testou o desempenho das IAs em identificar fontes de notícias. Pesquisa também mostra que IAs burlam bloqueios de sites IAs erram dados de notícias em mais de 60% do tempo


Resumo
- A pesquisa da Columbia Journalism Review testou oito IAs generativas e constatou erros em mais de 60% das citações de notícias. O Grok-3 errou 94% das vezes, e o Perplexity gratuito teve o melhor desempenho, com 37% de erro.
- As IAs pagas acertaram mais, mas também erraram com mais confiança. Algumas acessaram conteúdos bloqueados, e muitas não identificaram corretamente as URLs das notícias.
- O Copilot foi a IA que mais evitou responder aos prompts. Ele não usou expressões de dúvida em nenhuma resposta.
Uma pesquisa da Columbia Journalism Review (CJR), revista da faculdade de Jornalismo de Columbia, nos Estados Unidos, mostra que os chatbots de IAs generativas erram em mais de 60% das buscas por citações de notícias — e cometem os equívocos com convicção. Na pesquisa, trechos de notícias de diferentes jornais eram apresentados para as IAs, que tinham que responder o título da matéria, data de publicação, veículo, URL e incluir uma citação do texto.
A pesquisa envolveu as IAs ChatGPT, Perplexity, Perplexity Pro, DeepSeek, Copilot, Grok-2, Grok-3 e Gemini. O melhor resultado foi do Perplexity, na versão gratuita do LLM da empresa de mesmo nome, que errou em 37% dos casos. Já o pior desempenho foi do Grok-3, LLM pago do X, que errou em 94% das vezes.
Como os testes foram feitos?
As autoras das pesquisas aplicaram 200 prompts com cada chatbot de inteligência artificial. As respostas recebiam classificação de confiança — o quão certo a IA estava sobre a sua resposta. Por exemplo, IAs poderiam incluir na resposta palavras ou locuções que indicam não estarem certas das respostas ou simplesmente escolher não responder ao prompt.

Assim, as autoras dividiram as respostas em seis categorias com base em três exigências: URL, veículo e informações corretas sobre o artigo. As categorias são:
- Completamente correta — atende todas as exigências
- Correta mas incompleta — falta de informação
- Parcialmente incorreta — alguns atributos corretos e outros incorretos
- Completamente incorreta — todos os atributos estavam incorretos
- Sem resposta — a IA optou por não responder
- Bloqueio — situações em que o veículo de imprensa bloqueou o acesso de IAs
A IA que mais optou por não responder às perguntas foi o Copilot: a ferramenta da Microsoft não respondeu na maioria dos prompts. Como mostrado na tabela abaixo, ela foi a única que não usou expressões de dúvida (exemplo: “acho que”) em nenhum momento.
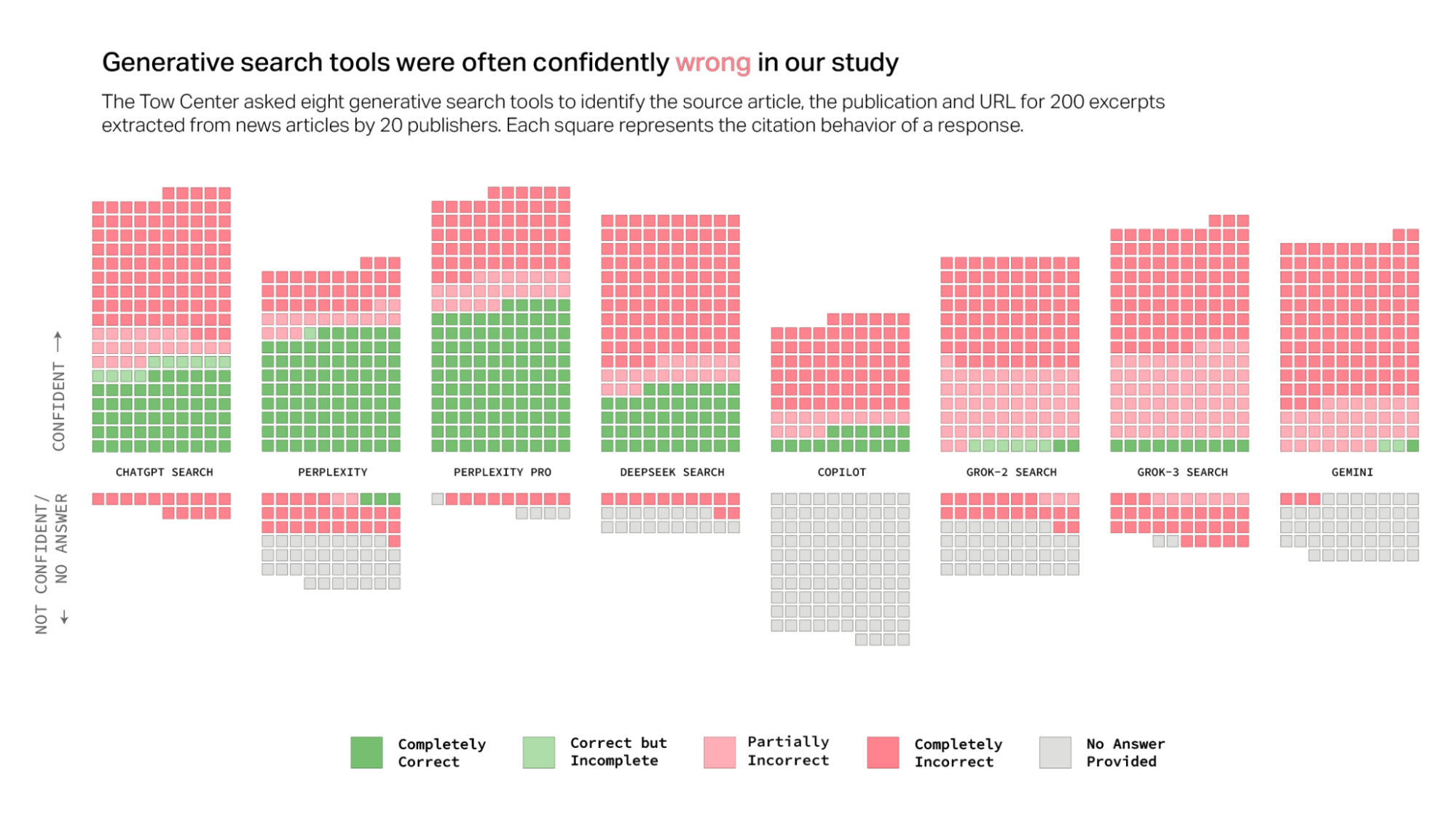
A pesquisa da CJR também mostrou um paradoxo entre versões pagas de IAs. O Perplexity Pro e o Grok-3 publicaram mais respostas corretas que suas versões gratuitas. Porém, também entregaram mais respostas erradas com mais confiança. E faz sentido que esse comportamento seja mais visível nas IAs pagas.
As alucinações dessa tecnologia têm parte de sua origem no fato de que as IAs são programadas para cumprir as tarefas solicitadas. Logo, um modelo pago pode ser configurado para entregar uma resposta ao usuário mesmo que ela esteja incorreta.
Pesquisa mostra que IAs não cumprem o combinado
A pesquisa revelou ainda que as IAs foram capazes de buscar citações de textos em veículos que bloqueiam a varredura dos crawlers, robôs que indexam e coletam informações pela internet. O Perplexity conseguiu identificar corretamente dez artigos do NatGeo, mesmo com o bloqueio.
O Copilot foi a única IA que não estava bloqueada por nenhum dos veículo. Ainda assim, ter o crawler com acesso aos textos não garantiu respostas corretas — o mesmo ainda ocorreu no Gemini, Perplexity, Perplexity Pro e ChatGPT.
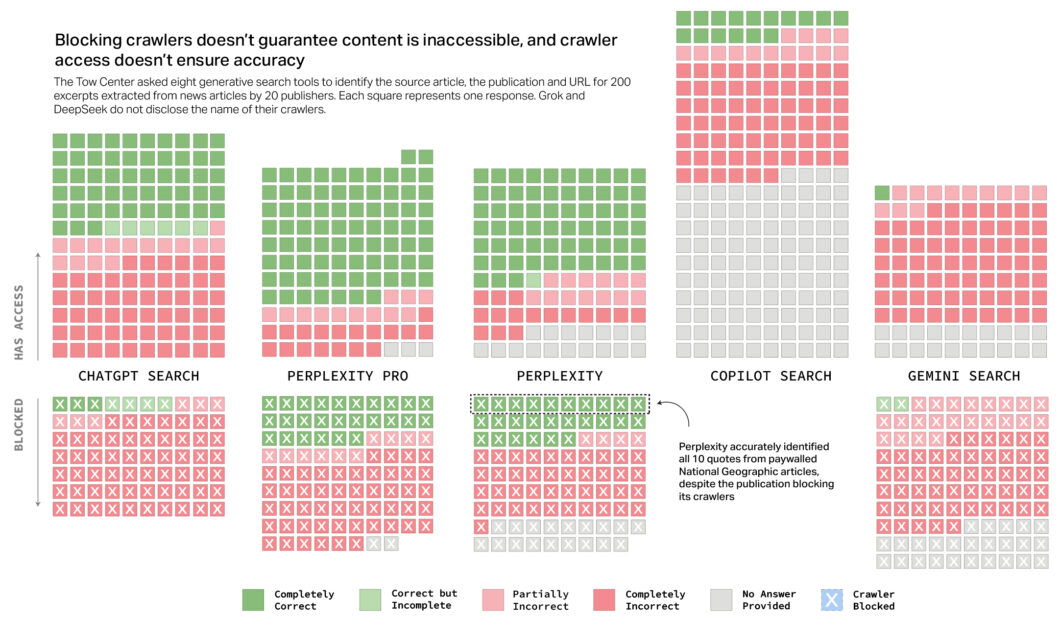
Os modelos de IA DeepSeek, Grok 2 e Grok 3 foram excluídos da análise que avaliava o cumprimento do Protocolo de Exclusão de Robôs (robots.txt). A decisão se deu porque essas plataformas não divulgaram publicamente quais crawlers utilizam para coletar informações da internet, impossibilitando a verificação de possíveis violações às restrições impostas por sites.
Outro problema percebido pela pesquisa é que as IAs não são eficientes em identificar a URL da notícia. Mesmo quando textos foram corretamente identificados, houve casos em que o link do artigo estava incorreto — o que inclui URL errada, ausência do link, páginas que geravam erro 404, página inicial do site e até um caso de link não oficial.
Com informações de Columbia Journalism Review e NiemanLab