





















































































































![[Обновлено] Похоже, Shift Up не знала об ограничении ПК-версии Stellar Blade в странах без PSN](https://images.stopgame.ru/news/2025/05/16/eeMwbKr9r.jpg?#)




































![С миру по нитке [13.05.2025]](http://tesera.ru/images/items/2478636,15/125x125xpa/photo.png)






































Новая проблема ИИ: визуальные языковые модели не понимают слова «нет»
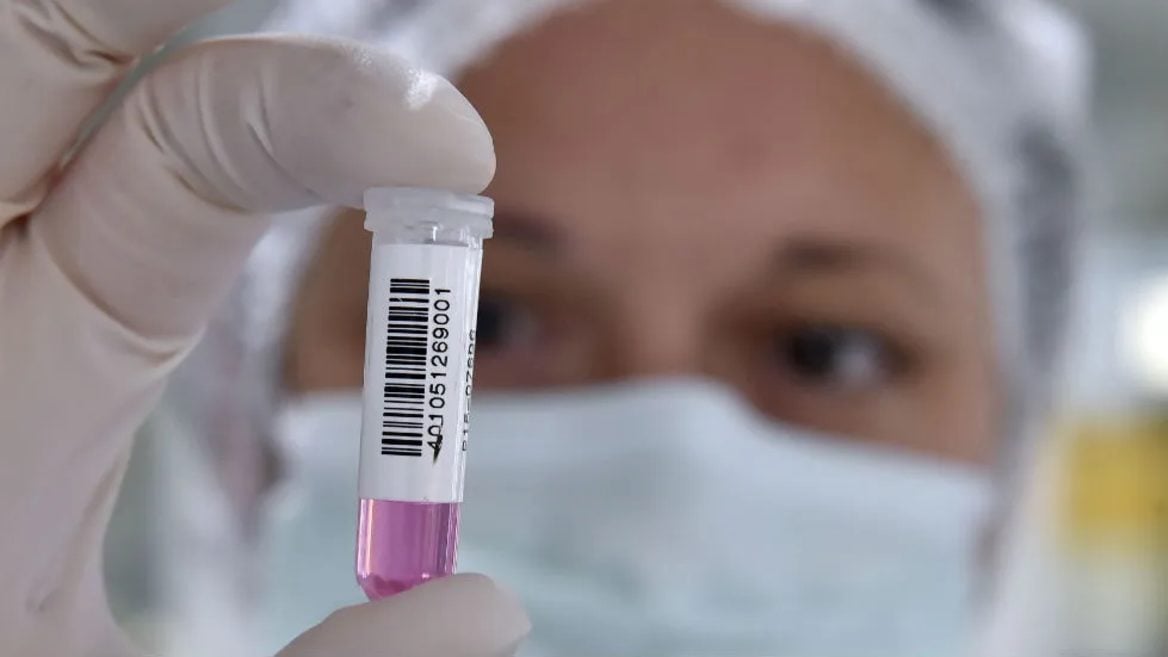
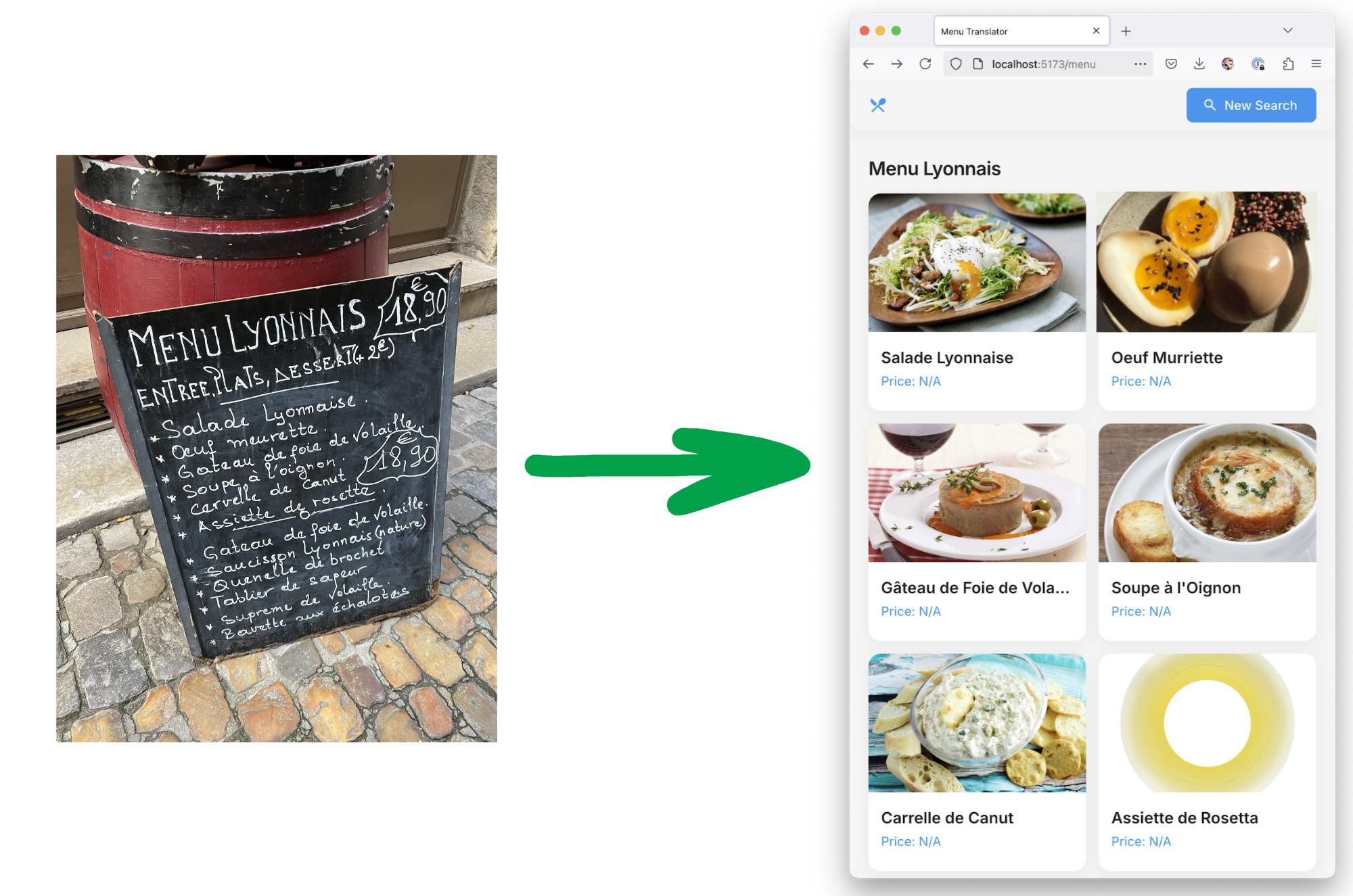
ИИ все чаще применяется в областях, в которых исключительно важна точность, а на кону нередко стоит человеческая жизнь— например, в медицине. Однако обнаруженная учеными опасная уязвимость может свести на нет всю пользу от внедрения нейросетей в такие сферы. Исследователи из Массачусетского технологического института (MIT) нашли серьезную уязвимость в современных визуально-языковых моделях искусственного интеллекта: они практически не распознают отрицания в текстах. Это означает, что системы, задачей которых является анализ изображений и соответствующих им описаний, могут допускать критические ошибки в понимании, особенно в сферах, где точность играет ключевую роль — в том числе, в медицине или промышленности. В качестве примера ученые привели ситуацию с рентгеновским снимком пациента. Если врач использует модель ИИ, чтобы найти аналогичные случаи в базе данных, но модель не распознает, что в описании указано «отек тканей без увеличения сердца», она может подобрать случаи и без увеличения сердца, и с ним — и таким образом допустить серьезную ошибку. В условиях, когда наличие или отсутствие одного симптома может полностью изменить медицинское заключение, подобные сбои недопустимы. Проблема кроется в том, что визуально-языковые модели (VLM), обученные на огромных массивах изображений и сопроводительных подписей, практически не сталкиваются с примерами, в которых четко указано, чего на изображении нет. Подписи обычно описывают только то, что есть: «собака прыгает через забор», а не «собака прыгает через забор, без вертолетов на фоне». Отсюда возникает так называемое «подтверждающее смещение» — модели просто игнорируют слова вроде «не» и «без», сосредотачиваясь исключительно на упомянутых объектах.

ИИ все чаще применяется в областях, в которых исключительно важна точность, а на кону нередко стоит человеческая жизнь— например, в медицине. Однако обнаруженная учеными опасная уязвимость может свести на нет всю пользу от внедрения нейросетей в такие сферы.
Исследователи из Массачусетского технологического института (MIT) нашли серьезную уязвимость в современных визуально-языковых моделях искусственного интеллекта: они практически не распознают отрицания в текстах. Это означает, что системы, задачей которых является анализ изображений и соответствующих им описаний, могут допускать критические ошибки в понимании, особенно в сферах, где точность играет ключевую роль — в том числе, в медицине или промышленности.
В качестве примера ученые привели ситуацию с рентгеновским снимком пациента. Если врач использует модель ИИ, чтобы найти аналогичные случаи в базе данных, но модель не распознает, что в описании указано «отек тканей без увеличения сердца», она может подобрать случаи и без увеличения сердца, и с ним — и таким образом допустить серьезную ошибку. В условиях, когда наличие или отсутствие одного симптома может полностью изменить медицинское заключение, подобные сбои недопустимы.
Проблема кроется в том, что визуально-языковые модели (VLM), обученные на огромных массивах изображений и сопроводительных подписей, практически не сталкиваются с примерами, в которых четко указано, чего на изображении нет. Подписи обычно описывают только то, что есть: «собака прыгает через забор», а не «собака прыгает через забор, без вертолетов на фоне». Отсюда возникает так называемое «подтверждающее смещение» — модели просто игнорируют слова вроде «не» и «без», сосредотачиваясь исключительно на упомянутых объектах.


