




















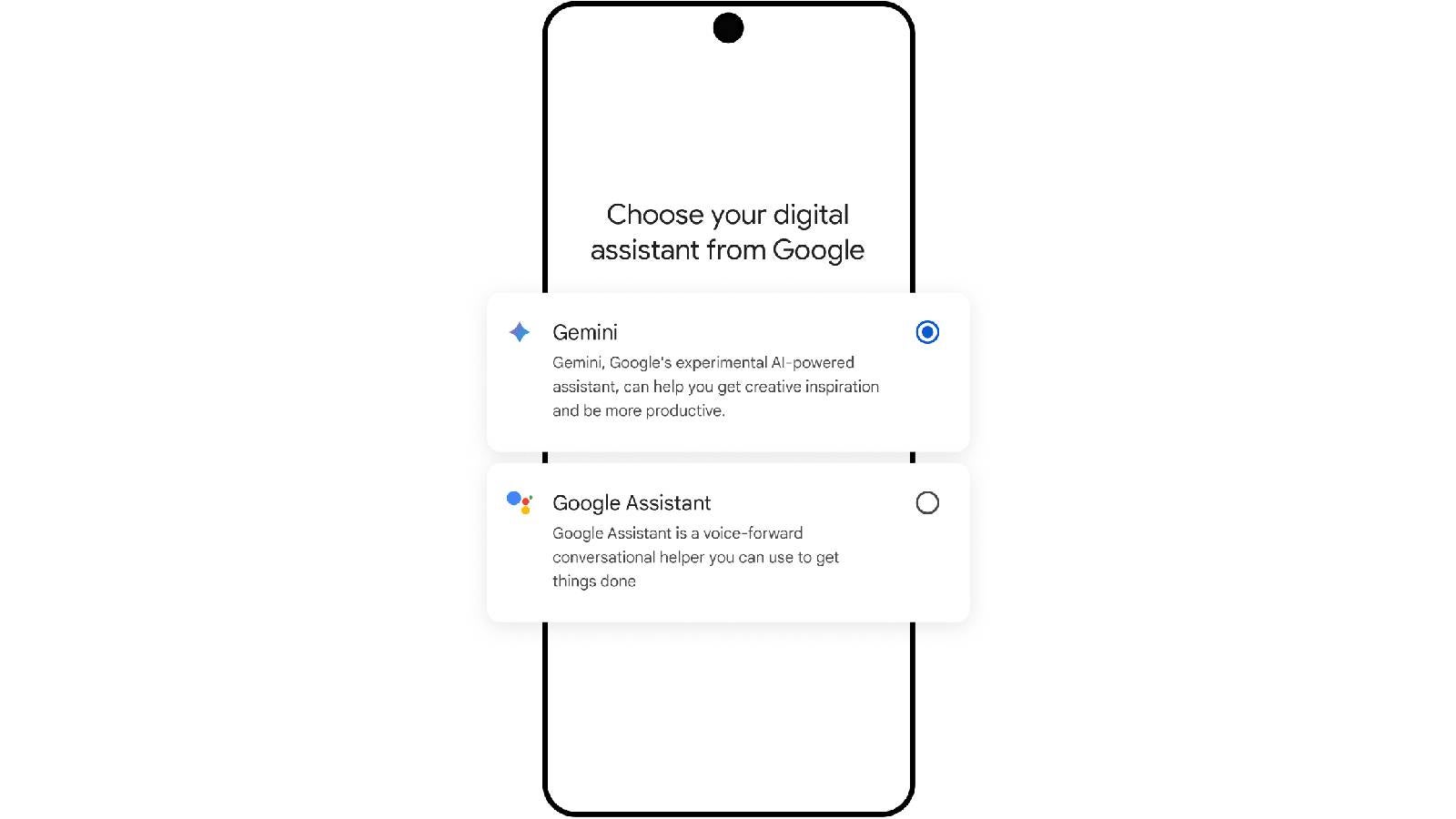

































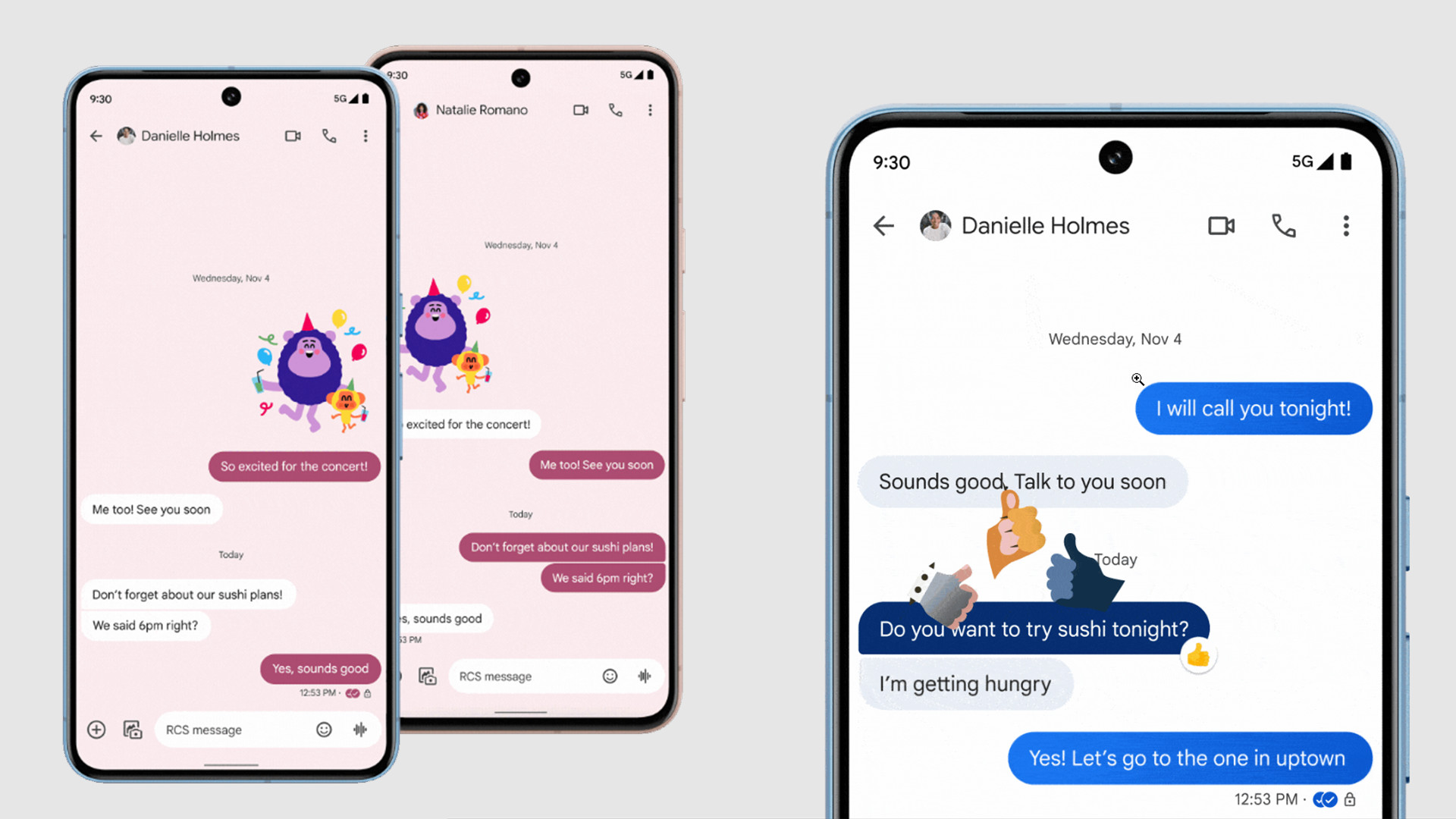











![Apple Officially Announces Return of 'Ted Lasso' for Fourth Season [Video]](https://www.iclarified.com/images/news/96710/96710/96710-640.jpg)
![Apple Plans Live Translation Feature for AirPods in iOS 19 [Report]](https://www.iclarified.com/images/news/96712/96712/96712-640.jpg)
![Apple Shares Official Trailer for 'F1' Starring Brad Pitt [Video]](https://www.iclarified.com/images/news/96714/96714/96714-640.jpg)













![[Update: Fix] Chromecast (2nd gen) and Audio can’t Cast in ‘Untrusted’ outage](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/08/chromecast_audio_1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


























































































_Tanapong_Sungkaew_Alamy.jpg?#)

_JIRAROJ_PRADITCHAROENKUL_Alamy.jpg?#)































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)







































































































































































































Convert DOCX to PDF Programmatically: AWS Lambda & LibreOffice
Introduction Converting documents from DOCX to PDF while maintaining formatting can be a challenging task. Many libraries exist for document conversion, but they often fall short in preserving the exact layout, fonts, and styles. This was a major issue for me until I discovered an efficient cloud-based solution using AWS Lambda and LibreOffice in headless mode. In this article, I’ll share my experience setting up document conversion in the cloud using AWS Lambda, Docker, and LibreOffice, providing a seamless and reliable way to process files without worrying about server management. The Challenge: Keeping Formatting Intact When working with document conversions, formatting is crucial. Many tools can handle the basic DOCX to PDF conversion, but the output often looks different from the original document. I needed a solution that: Preserves fonts, styles, and layouts Works in a serverless environment Is easy to scale and manage That’s when I came across @shelf/aws-lambda-libreoffice, a powerful package that runs LibreOffice in a headless mode within AWS Lambda, making it perfect for cloud-based document processing. Solution: AWS Lambda with LibreOffice Why Use AWS Lambda? AWS Lambda is a serverless computing service, meaning you don’t need to worry about managing infrastructure. It automatically scales and only runs when needed, making it cost-effective and efficient. By using Lambda, you can process document conversions on demand without maintaining a dedicated server. Why LibreOffice in Headless Mode? LibreOffice is one of the most reliable document processing tools. When run in headless mode, it can process documents programmatically without requiring a GUI, making it an excellent choice for automated conversions. Dockerizing LibreOffice for AWS Lambda Since AWS Lambda has certain limitations on package size and dependencies, we need to containerize our solution using Docker. Thankfully, the @shelf/aws-lambda-libreoffice package provides a pre-configured Docker image, which simplifies deployment. Steps to Set Up DOCX to PDF Conversion in AWS Lambda 1. Use a Pre-built Docker Image To save time, I used a public Docker image that includes everything needed for LibreOffice in AWS Lambda. Here’s the base image: FROM public.ecr.aws/shelf/lambda-libreoffice-base:7.6-node18-x86_64 2. Set Up the AWS Lambda Function We need to create an AWS Lambda function that: Accepts a DOCX file as input Converts it to PDF using LibreOffice in headless mode Returns the converted PDF Here’s a simple Node.js script to handle the conversion: const { execSync } = require("child_process"); const fs = require("fs"); const path = require("path"); exports.handler = async (event) => { const inputFilePath = "/tmp/input.docx"; const outputFilePath = "/tmp/output.pdf"; fs.writeFileSync(inputFilePath, Buffer.from(event.body, "base64")); execSync(`libreoffice --headless --convert-to pdf --outdir /tmp ${inputFilePath}`); const pdfBuffer = fs.readFileSync(outputFilePath); return { statusCode: 200, headers: { "Content-Type": "application/pdf" }, body: pdfBuffer.toString("base64"), isBase64Encoded: true, }; }; 3. Build and Push the Docker Image to AWS ECR After setting up the Dockerfile, build and push the image to AWS Elastic Container Registry (ECR): docker build -t libreoffice-converter . docker tag libreoffice-converter:latest .dkr.ecr..amazonaws.com/libreoffice-converter aws ecr get-login-password --region | docker login --username AWS --password-stdin .dkr.ecr..amazonaws.com docker push .dkr.ecr..amazonaws.com/libreoffice-converter 4. Deploy the AWS Lambda Function Now, create an AWS Lambda function and use the container image you just pushed to AWS ECR. Ensure that the function has sufficient memory (512MB or more) to handle conversions efficiently. 5. Test the Conversion To test the function, upload a sample DOCX file and trigger the Lambda function. It should return a well-formatted PDF, preserving all styles and layouts. Benefits of This Approach ✅ No server management – AWS Lambda handles execution automatically. ✅ Accurate formatting – LibreOffice ensures high-quality conversions. ✅ Scalability – The function can handle multiple conversions without additional infrastructure. ✅ Cost-effective – You only pay for the compute time when the function runs. Conclusion If you’re struggling with DOCX to PDF conversion while maintaining formatting, AWS Lambda with LibreOffice in headless mode is an excellent solution. By leveraging serverless computing and containerization, you can achieve high-quality document processing without the hassle of managing servers. Give this setup a try, and let me know your thoughts!
Introduction
Converting documents from DOCX to PDF while maintaining formatting can be a challenging task. Many libraries exist for document conversion, but they often fall short in preserving the exact layout, fonts, and styles. This was a major issue for me until I discovered an efficient cloud-based solution using AWS Lambda and LibreOffice in headless mode.
In this article, I’ll share my experience setting up document conversion in the cloud using AWS Lambda, Docker, and LibreOffice, providing a seamless and reliable way to process files without worrying about server management.
The Challenge: Keeping Formatting Intact
When working with document conversions, formatting is crucial. Many tools can handle the basic DOCX to PDF conversion, but the output often looks different from the original document. I needed a solution that:
- Preserves fonts, styles, and layouts
- Works in a serverless environment
- Is easy to scale and manage
That’s when I came across @shelf/aws-lambda-libreoffice, a powerful package that runs LibreOffice in a headless mode within AWS Lambda, making it perfect for cloud-based document processing.
Solution: AWS Lambda with LibreOffice
Why Use AWS Lambda?
AWS Lambda is a serverless computing service, meaning you don’t need to worry about managing infrastructure. It automatically scales and only runs when needed, making it cost-effective and efficient. By using Lambda, you can process document conversions on demand without maintaining a dedicated server.
Why LibreOffice in Headless Mode?
LibreOffice is one of the most reliable document processing tools. When run in headless mode, it can process documents programmatically without requiring a GUI, making it an excellent choice for automated conversions.
Dockerizing LibreOffice for AWS Lambda
Since AWS Lambda has certain limitations on package size and dependencies, we need to containerize our solution using Docker. Thankfully, the @shelf/aws-lambda-libreoffice package provides a pre-configured Docker image, which simplifies deployment.
Steps to Set Up DOCX to PDF Conversion in AWS Lambda
1. Use a Pre-built Docker Image
To save time, I used a public Docker image that includes everything needed for LibreOffice in AWS Lambda. Here’s the base image:
FROM public.ecr.aws/shelf/lambda-libreoffice-base:7.6-node18-x86_64
2. Set Up the AWS Lambda Function
We need to create an AWS Lambda function that:
- Accepts a DOCX file as input
- Converts it to PDF using LibreOffice in headless mode
- Returns the converted PDF
Here’s a simple Node.js script to handle the conversion:
const { execSync } = require("child_process");
const fs = require("fs");
const path = require("path");
exports.handler = async (event) => {
const inputFilePath = "/tmp/input.docx";
const outputFilePath = "/tmp/output.pdf";
fs.writeFileSync(inputFilePath, Buffer.from(event.body, "base64"));
execSync(`libreoffice --headless --convert-to pdf --outdir /tmp ${inputFilePath}`);
const pdfBuffer = fs.readFileSync(outputFilePath);
return {
statusCode: 200,
headers: { "Content-Type": "application/pdf" },
body: pdfBuffer.toString("base64"),
isBase64Encoded: true,
};
};
3. Build and Push the Docker Image to AWS ECR
After setting up the Dockerfile, build and push the image to AWS Elastic Container Registry (ECR):
docker build -t libreoffice-converter .
docker tag libreoffice-converter:latest .dkr.ecr..amazonaws.com/libreoffice-converter
aws ecr get-login-password --region | docker login --username AWS --password-stdin .dkr.ecr..amazonaws.com
docker push .dkr.ecr..amazonaws.com/libreoffice-converter
4. Deploy the AWS Lambda Function
Now, create an AWS Lambda function and use the container image you just pushed to AWS ECR. Ensure that the function has sufficient memory (512MB or more) to handle conversions efficiently.
5. Test the Conversion
To test the function, upload a sample DOCX file and trigger the Lambda function. It should return a well-formatted PDF, preserving all styles and layouts.
Benefits of This Approach
✅ No server management – AWS Lambda handles execution automatically.
✅ Accurate formatting – LibreOffice ensures high-quality conversions.
✅ Scalability – The function can handle multiple conversions without additional infrastructure.
✅ Cost-effective – You only pay for the compute time when the function runs.
Conclusion
If you’re struggling with DOCX to PDF conversion while maintaining formatting, AWS Lambda with LibreOffice in headless mode is an excellent solution. By leveraging serverless computing and containerization, you can achieve high-quality document processing without the hassle of managing servers.
Give this setup a try, and let me know your thoughts!







