






























































![Apple Teases Spike Jonze 'Someday' Film Showcasing AirPods 4 with ANC [Video]](https://www.iclarified.com/images/news/96727/96727/96727-640.jpg)
![Apple Working on Two New Studio Display Models [Gurman]](https://www.iclarified.com/images/news/96724/96724/96724-640.jpg)
![Dummy Models Allegedly Reveal Design of iPhone 17 Lineup [Images]](https://www.iclarified.com/images/news/96725/96725/96725-640.jpg)
![New M4 MacBook Air On Sale for $949 [Deal]](https://www.iclarified.com/images/news/96721/96721/96721-640.jpg)


















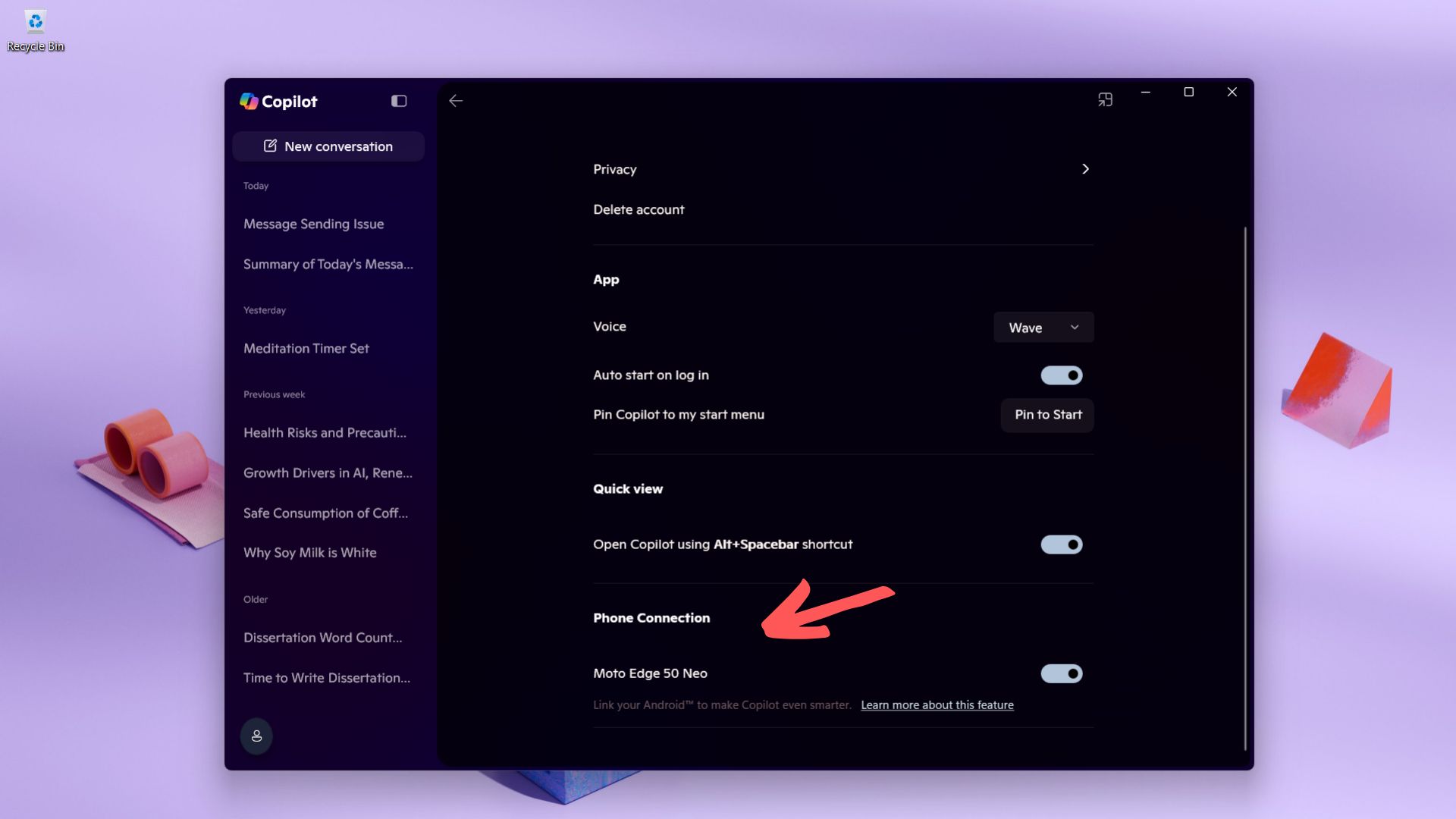








![Amazon to kill Echo's local voice processing feature in favor of Voice ID [u]](https://photos5.appleinsider.com/gallery/62978-130749-62782-130279-IMG_0502-xl-xl.jpg)






































































































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)












































































































![How to become a self-taught developer while supporting a family [Podcast #164]](https://cdn.hashnode.com/res/hashnode/image/upload/v1741989957776/7e938ad4-f691-4c9e-8c6b-dc26da7767e1.png?#)
















































































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)







Dynamic Tanh DyT: A Simplified Alternative to Normalization in Transformers
Normalization layers have become fundamental components of modern neural networks, significantly improving optimization by stabilizing gradient flow, reducing sensitivity to weight initialization, and smoothing the loss landscape. Since the introduction of batch normalization in 2015, various normalization techniques have been developed for different architectures, with layer normalization (LN) becoming particularly dominant in Transformer models. Their […] The post Dynamic Tanh DyT: A Simplified Alternative to Normalization in Transformers appeared first on MarkTechPost.



Normalization layers have become fundamental components of modern neural networks, significantly improving optimization by stabilizing gradient flow, reducing sensitivity to weight initialization, and smoothing the loss landscape. Since the introduction of batch normalization in 2015, various normalization techniques have been developed for different architectures, with layer normalization (LN) becoming particularly dominant in Transformer models. Their widespread use is largely attributed to their ability to accelerate convergence and enhance model performance, especially as networks grow deeper and more complex. Despite ongoing architectural innovations that replace other core components like attention or convolution layers, normalization layers remain integral to most designs, underscoring their perceived necessity in deep learning.
While normalization layers have proven beneficial, researchers have also explored methods to train deep networks without them. Studies have proposed alternative weight initialization strategies, weight normalization techniques, and adaptive gradient clipping to maintain stability in models like ResNets. In Transformers, recent efforts have examined modifications that reduce reliance on normalization, such as restructuring Transformer blocks or gradually removing LN layers through fine-tuning. These approaches demonstrate that, while normalization layers offer optimization advantages, they are not strictly indispensable, and alternative training techniques can achieve stable convergence with comparable performance.
Researchers from FAIR, Meta, NYU, MIT, and Princeton propose Dynamic Tanh (DyT) as a simple yet effective alternative to normalization layers in Transformers. DyT operates as an element-wise function, DyT(x) = tanh(alpha x), where (alpha) is a learnable parameter that scales activations while limiting extreme values. Unlike layer normalization, DyT eliminates the need for activation statistics, simplifying computations. Empirical evaluations show that replacing normalization layers with DyT maintains or improves performance across various tasks without extensive hyperparameter tuning. Additionally, DyT enhances training and inference efficiency, challenging the assumption that normalization is essential for modern deep networks.
Researchers analyzed normalization layers in Transformers using models like ViT-B, wav2vec 2.0, and DiT-XL. They found that LN often exhibits a tanh-like, S-shaped input-output mapping, primarily linear for most values but squashing extreme activations. Inspired by this, they propose Dynamic Tanh (DyT) as a replacement for LN. Defined as DyT(x) = gamma *tanh(alpha x) + beta), where alpha, gamma, and beta are learnable parameters, DyT preserves LN’s effects without computing activation statistics. Empirical results show DyT integrates seamlessly into existing architectures, maintaining stability and reducing the need for hyperparameter tuning.
To evaluate DyT’s effectiveness, experiments were conducted across various architectures and tasks by replacing LN or RMSNorm with DyT while keeping hyperparameters unchanged. In supervised vision tasks, DyT slightly outperformed LN in ImageNet-1K classification. For self-supervised learning, diffusion models, language models, speech processing, and DNA sequence modeling, DyT achieved performance comparable to existing normalization methods. Efficiency tests on LLaMA-7B showed DyT reduced computation time. Ablation studies highlighted the importance of the tanh function and learnable parameter α, which correlated with activation standard deviation, acting as an implicit normalization mechanism. DyT demonstrated competitive performance with improved efficiency.
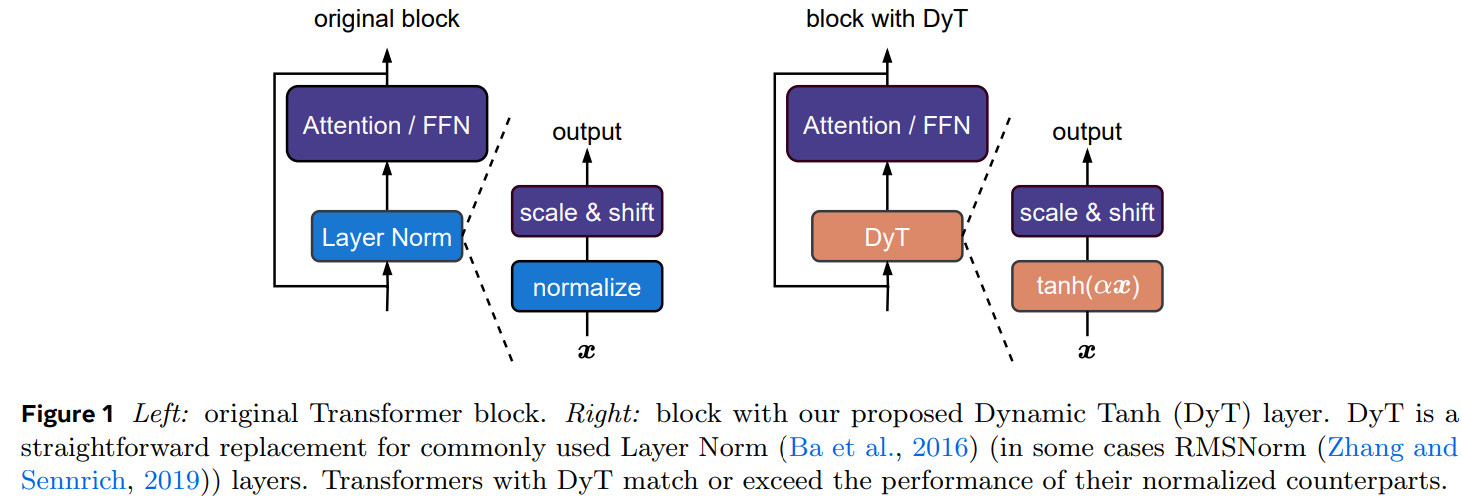
In conclusion, the study shows that modern neural networks, particularly Transformers, can be trained effectively without normalization layers. The proposed DyT replaces traditional normalization using a learnable scaling factor alpha and an S-shaped tanh function to regulate activation values. Despite its simplicity, DyT replicates normalization behavior and achieves comparable or superior performance across various tasks, including recognition, generation, and self-supervised learning. The results challenge the assumption that normalization layers are essential, offering new insights into their function. DyT provides a lightweight alternative that simplifies training while maintaining or improving performance, often without requiring hyperparameter adjustments.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post Dynamic Tanh DyT: A Simplified Alternative to Normalization in Transformers appeared first on MarkTechPost.







