































































































![С миру по нитке [27.03.2025]](http://tesera.ru/images/items/2465835,15/125x125xpa/photo.png)
























![Для самых преданных фанатов. Обзор гоночной игры Wreckfest 2 [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/25/nova-filepond-CLkvqB.jpg)
![Затягивает, несмотря на кривизну и баги. Обзор симулятора погружения Peripeteia [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/20/nova-filepond-VoGrRW.jpg)














































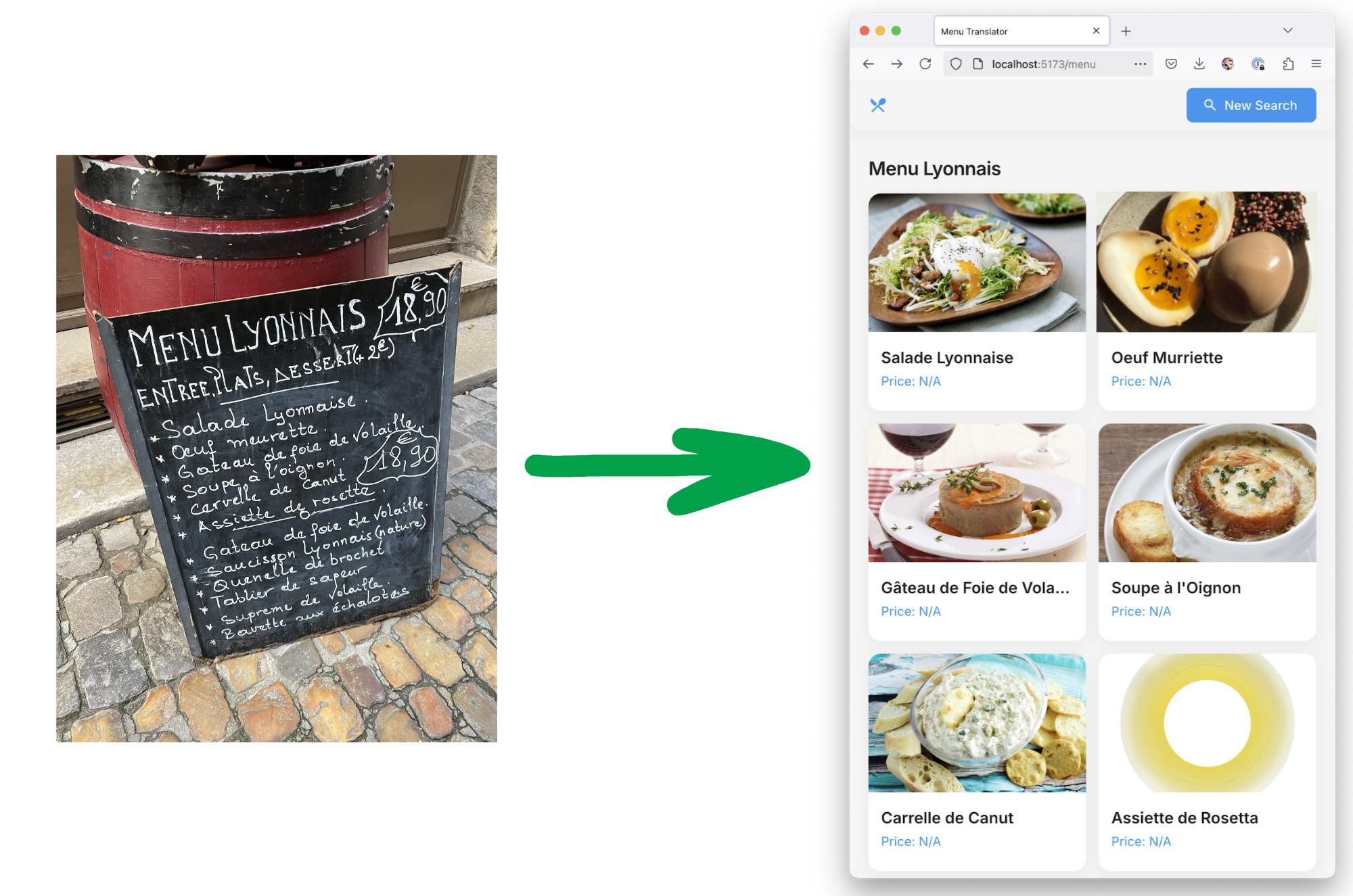
Все ведущие модели ИИ провалили новый тест на общий интеллект
Новый бенчмарк ARC-AGI-2, разработанный для оценки общего интеллекта искусственного интеллекта, показал значительный отрыв между возможностями современных ИИ и человеческим разумом в задачах, требующих адаптации и понимания новых концепций. Большинство ведущих ИИ-моделей продемонстрировали крайне низкие результаты на этом испытании, в отличие от группы людей.

Новый бенчмарк ARC-AGI-2, разработанный для оценки общего интеллекта искусственного интеллекта, показал значительный отрыв между возможностями современных ИИ и человеческим разумом в задачах, требующих адаптации и понимания новых концепций. Большинство ведущих ИИ-моделей продемонстрировали крайне низкие результаты на этом испытании, в отличие от группы людей.


