























































.webp)


.webp)
































































![Bilan 2024 : Les nouveautés Agorapulse pour booster votre stratégie sociale [Infographie]](https://www.agorapulse.com/fr/blog/wp-content/uploads/sites/3/2025/03/FR-New-Favorite-Agorapulse-Features-of-2024-Blogpost-Header-scaled.jpg?#)





















































Launch HN: Augento (YC W25) – Fine-tune your agents with reinforcement learning
Hi HN, we’re the cofounders of Augento (https://augento.ai/). We’re building Deepseek R1-like fine-tuning as a service. You connect your agent, tell us when it’s right or wrong, and we deliver an LLM optimized for that agent. There’s a demo video https://www.youtube.com/watch?v=j5RQaTdRrKE, and our docs are at https://docs.augento.ai/. It’s open for anyone to use at https://augento.ai.Agents fail all the time, especially when you try to use them for something actually useful. Current solution approaches suck: prompting has intrinsic limits and supervised fine-tuning requires big explicit datasets that are hard to collect.Two months ago, the DeepSeek R1 paper outlined a way to post-train LLMs with (almost) pure reinforcement learning. We took up their research and built a fine-tuning platform around that.You let us intercept your agent's data flow, and we deliver you a fine-tuned open-source model, that is trained on the agent's specific task. Instead of providing big datasets of explicit fine-tuning samples, you provide a reward function, judging the model's outputs.Here are examples of what this can be used for:Coding Agent: We fine-tuned a coding agent that was constantly making syntax errors and failed to handle semantic edge cases properly. By providing a reward function that evaluated code against the compiler, the agent learned not to produce these errors. The fine-tuned model reduced critical bugs by 40% with just 20 training samples.MCP Tool Specialization: Imagine you have a custom set of internal tools using the MCP protocol, but your agent keeps selecting the wrong tool or passing incompatible parameters. You could fine-tune with a reward function that scores tool selection and parameter matching.Browser Agent Navigation: If you're building a browser agent that struggles with complex web UIs or specific sites, you could fine-tune it to better understand UI elements and navigation patterns. With a reward function that scores successful task completion (like "find the best price for this product" or "complete this multi-step form"), you could train an agent that better identifies clickable elements, understands form validation errors, and navigates through complex SPAs without getting stuck.VLA Robot Control: If you're using vision-language models to control robotic arms or other hardware, you could fine-tune for your specific actuator setup. With a reward function based on high-level task completion, you could train a Vision-Langauge-Action (VLA) model that translates natural language commands like "move the red block behind the blue cylinder" into actuator controls for your specific hardware.As you see from these examples, the current paradigm is best suited for "verifiable domains”, where it is possible to give an explicit function judging the model’s outputs. However, up next, we will also support an "alignment mode", where you don't have to provide a reward function but provide high-level feedback on past failure runs of your agent. Just tag where things went wrong, and we'll handle the rest. This makes it even easier to improve your agents without needing to write formal reward functions.Our platform is not itself open source, but it fine-tunes open-source language models. I.e. it is an alternative to the reinforcement fine-tuning API from OpenAI, but with Qwen, LLama, Deepseek, etc., and more customizability on the reward model. We charge users for the training and for their inference/interaction with the model later on ($0 monthly flat fee + training cost + inference cost).The platform is self-serving and open to use at https://augento.ai/dashboard. We’ll give you $20 in training credits, which should be enough for connecting your agent and delivering some observable improvement on your use case.We’d love to hear your thoughts and feedback! Comments URL: https://news.ycombinator.com/item?id=43537505 Points: 21 # Comments: 4

Hi HN, we’re the cofounders of Augento (https://augento.ai/). We’re building Deepseek R1-like fine-tuning as a service. You connect your agent, tell us when it’s right or wrong, and we deliver an LLM optimized for that agent. There’s a demo video https://www.youtube.com/watch?v=j5RQaTdRrKE, and our docs are at https://docs.augento.ai/. It’s open for anyone to use at https://augento.ai.
Agents fail all the time, especially when you try to use them for something actually useful. Current solution approaches suck: prompting has intrinsic limits and supervised fine-tuning requires big explicit datasets that are hard to collect.
Two months ago, the DeepSeek R1 paper outlined a way to post-train LLMs with (almost) pure reinforcement learning. We took up their research and built a fine-tuning platform around that.
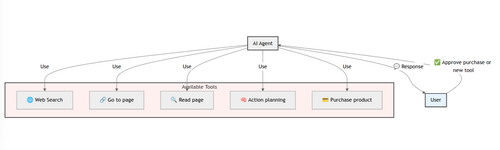
You let us intercept your agent's data flow, and we deliver you a fine-tuned open-source model, that is trained on the agent's specific task. Instead of providing big datasets of explicit fine-tuning samples, you provide a reward function, judging the model's outputs.
Here are examples of what this can be used for:
Coding Agent: We fine-tuned a coding agent that was constantly making syntax errors and failed to handle semantic edge cases properly. By providing a reward function that evaluated code against the compiler, the agent learned not to produce these errors. The fine-tuned model reduced critical bugs by 40% with just 20 training samples.
MCP Tool Specialization: Imagine you have a custom set of internal tools using the MCP protocol, but your agent keeps selecting the wrong tool or passing incompatible parameters. You could fine-tune with a reward function that scores tool selection and parameter matching.
Browser Agent Navigation: If you're building a browser agent that struggles with complex web UIs or specific sites, you could fine-tune it to better understand UI elements and navigation patterns. With a reward function that scores successful task completion (like "find the best price for this product" or "complete this multi-step form"), you could train an agent that better identifies clickable elements, understands form validation errors, and navigates through complex SPAs without getting stuck.
VLA Robot Control: If you're using vision-language models to control robotic arms or other hardware, you could fine-tune for your specific actuator setup. With a reward function based on high-level task completion, you could train a Vision-Langauge-Action (VLA) model that translates natural language commands like "move the red block behind the blue cylinder" into actuator controls for your specific hardware.
As you see from these examples, the current paradigm is best suited for "verifiable domains”, where it is possible to give an explicit function judging the model’s outputs. However, up next, we will also support an "alignment mode", where you don't have to provide a reward function but provide high-level feedback on past failure runs of your agent. Just tag where things went wrong, and we'll handle the rest. This makes it even easier to improve your agents without needing to write formal reward functions.
Our platform is not itself open source, but it fine-tunes open-source language models. I.e. it is an alternative to the reinforcement fine-tuning API from OpenAI, but with Qwen, LLama, Deepseek, etc., and more customizability on the reward model. We charge users for the training and for their inference/interaction with the model later on ($0 monthly flat fee + training cost + inference cost).
The platform is self-serving and open to use at https://augento.ai/dashboard. We’ll give you $20 in training credits, which should be enough for connecting your agent and delivering some observable improvement on your use case.
We’d love to hear your thoughts and feedback!
Comments URL: https://news.ycombinator.com/item?id=43537505
Points: 21
# Comments: 4
