





























































![Apple Releases iOS 18.5 Beta 3 and iPadOS 18.5 Beta 3 [Download]](https://www.iclarified.com/images/news/97076/97076/97076-640.jpg)
![Apple Seeds visionOS 2.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97077/97077/97077-640.jpg)
![Apple Seeds tvOS 18.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97078/97078/97078-640.jpg)
![Apple Seeds watchOS 11.5 Beta 3 to Developers [Download]](https://www.iclarified.com/images/news/97079/97079/97079-640.jpg)












![What’s new in Android’s April 2025 Google System Updates [U: 4/21]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)






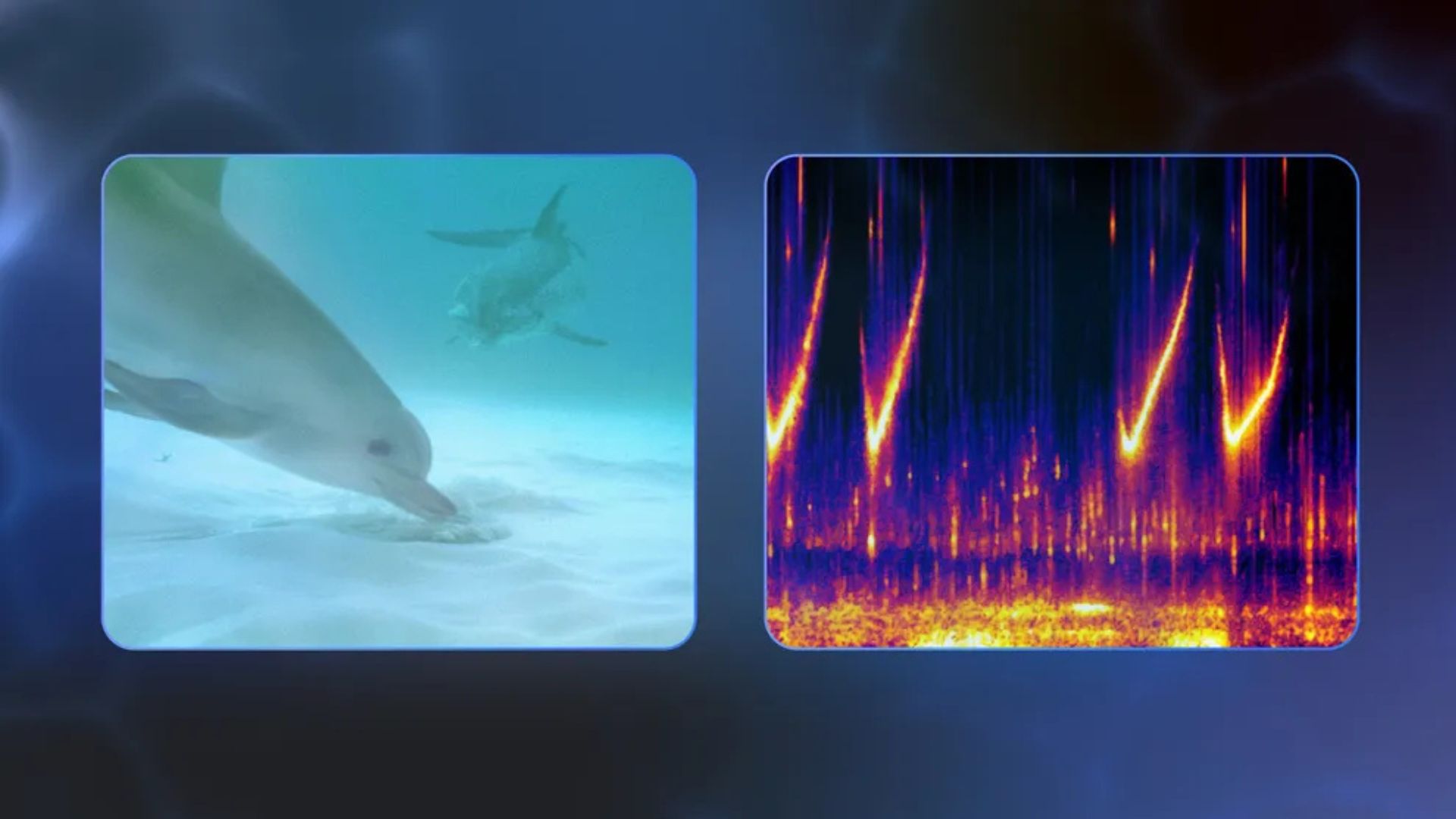







































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)


















![From fast food worker to cybersecurity engineer with Tae'lur Alexis [Podcast #169]](https://cdn.hashnode.com/res/hashnode/image/upload/v1745242807605/8a6cf71c-144f-4c91-9532-62d7c92c0f65.png?#)




































.jpg?#)
.jpg?#)























































Optimized Management Of Configuration Files On Aws S3: Strategies And Best Practices
Efficient management and updating of configuration files is essential in modern software settings, particularly when these files are stored on cloud storage services such as AWS S3. There are a number of issues associated with this process, such as maintaining data integrity, reducing downtime, and maximizing network and storage use. The main challenge is managing the lifespan of these configuration files efficiently, from deployments to updates, all the while making sure that changes are disseminated throughout dispersed systems in a timely and reliable manner. This necessitates a solid uploading plan that makes use of cloud features to improve dependability and performance for altered files on S3. Streamlining Operations: Single Upload and Download of the YAML File The process involves two primary phases: uploading and downloading a YAML file, which contains structured data essential for operational workflows. Upload Phase: Data Capture: Systematically capture and consolidate data as per the operational requirements. Local Storage: Temporarily store this data in a YAML file on a local system to ensure immediate availability and data integrity. Asynchronous Upload: Once the data capture is complete, initiate an asynchronous upload of the YAML file to an S3 bucket. This step is designed to minimize disruption to ongoing operations. This can also be orchestrated using AWS Lambda S3 API Gateway upload file TypeScript workflows for improved automation. User Notification: Inform users that the data capture phase has ended and that the upload is underway, providing transparency about the process status. Download Phase: Retrieval: When the data is required for further processing, download the relevant YAML file from S3 to a local directory. Operational Use: Utilize the structured data as needed to fulfil specific operational tasks. Resource Cleanup: Post-operation, clean up any local files and resources that were used, maintaining system efficiency and data security. Advantages: Reduced Network Calls: By limiting operations to a single upload and download, network traffic is minimised, leading to more efficient data handling and reduced latency. Efficient Memory Usage: Storing data in a YAML file, as opposed to continuous in-memory storage, can be more resource-efficient, particularly for large datasets. Challenges: Local Storage Concerns: The need for temporary local storage of potentially large YAML files might pose security or resource allocation issues. Operational Delays: The asynchronous nature of the upload could introduce delays in workflow transitions, although this is mitigated by informing users of the process status. Implementation Outline for In-Memory Data Handling and S3 Integration Data Capture Phase: Start Capturing: Collect data actively, such as API requests and responses, storing them directly in memory using a structured format or data structure. Serialize Data: Once the collection is complete, serialize the in-memory data into a suitable format, such as a compressed JSON or YAML file, preparing it for upload. Asynchronous Upload: Initiate an asynchronous upload of the serialized data to an S3 bucket. This method helps in minimizing the operational impact on the system. Using AWS Amplify API request query S3 bucket can simplify this process in frontend-heavy apps. User Notification: Post-upload initiation, inform users that the data capture has concluded and that the upload process is ongoing, thereby ensuring operational transparency. Data Replay Phase: Retrieve Data: Download the required serialized data file from S3 to local memory. Deserialize Data: Convert the serialized data back into its original in-memory format for operational use. Simulate Responses: Use the deserialized data to simulate or replicate the originally captured API responses. Cleanup: After the simulation, clear the used data from memory to maintain optimal memory usage and system performance. Advantages: No Local File Creation: By handling data exclusively in memory and eliminating local file storage, file I/O operations are reduced, leading to faster processing and less potential for file management errors. Single Upload: Consolidating all data into a single upload at the end of the recording phase minimizes network traffic and simplifies the data management pipeline. Challenges: Increased Memory Usage: Maintaining all configurations and data in memory can substantially increase memory consumption, particularly with large datasets. Operational Delays: The asynchronous data upload process might introduce a delay during the transition from active recording to system closure, although users are made aware of this potential delay. Incremental Configuration Management with Frequent S3 Updates Data Capture Phase: Start Data Capture: Capture API requests and responses. Store Single Configuration in Memory: Each captured configuration is saved in memory. Update and Upload: For each new

Efficient management and updating of configuration files is essential in modern software settings, particularly when these files are stored on cloud storage services such as AWS S3. There are a number of issues associated with this process, such as maintaining data integrity, reducing downtime, and maximizing network and storage use. The main challenge is managing the lifespan of these configuration files efficiently, from deployments to updates, all the while making sure that changes are disseminated throughout dispersed systems in a timely and reliable manner. This necessitates a solid uploading plan that makes use of cloud features to improve dependability and performance for altered files on S3.
Streamlining Operations: Single Upload and Download of the YAML File
The process involves two primary phases: uploading and downloading a YAML file, which contains structured data essential for operational workflows.
Upload Phase:
Data Capture: Systematically capture and consolidate data as per the operational requirements.
Local Storage: Temporarily store this data in a YAML file on a local system to ensure immediate availability and data integrity.
Asynchronous Upload: Once the data capture is complete, initiate an asynchronous upload of the YAML file to an S3 bucket. This step is designed to minimize disruption to ongoing operations. This can also be orchestrated using AWS Lambda S3 API Gateway upload file TypeScript workflows for improved automation.
User Notification: Inform users that the data capture phase has ended and that the upload is underway, providing transparency about the process status.
Download Phase:
Retrieval: When the data is required for further processing, download the relevant YAML file from S3 to a local directory.
Operational Use: Utilize the structured data as needed to fulfil specific operational tasks.
Resource Cleanup: Post-operation, clean up any local files and resources that were used, maintaining system efficiency and data security.
Advantages:
Reduced Network Calls: By limiting operations to a single upload and download, network traffic is minimised, leading to more efficient data handling and reduced latency.
Efficient Memory Usage: Storing data in a YAML file, as opposed to continuous in-memory storage, can be more resource-efficient, particularly for large datasets.
Challenges:
Local Storage Concerns: The need for temporary local storage of potentially large YAML files might pose security or resource allocation issues.
Operational Delays: The asynchronous nature of the upload could introduce delays in workflow transitions, although this is mitigated by informing users of the process status.
Implementation Outline for In-Memory Data Handling and S3 Integration
Data Capture Phase:
Start Capturing: Collect data actively, such as API requests and responses, storing them directly in memory using a structured format or data structure.
Serialize Data: Once the collection is complete, serialize the in-memory data into a suitable format, such as a compressed JSON or YAML file, preparing it for upload.
Asynchronous Upload: Initiate an asynchronous upload of the serialized data to an S3 bucket. This method helps in minimizing the operational impact on the system. Using AWS Amplify API request query S3 bucket can simplify this process in frontend-heavy apps.
User Notification: Post-upload initiation, inform users that the data capture has concluded and that the upload process is ongoing, thereby ensuring operational transparency.
Data Replay Phase:
Retrieve Data: Download the required serialized data file from S3 to local memory.
Deserialize Data: Convert the serialized data back into its original in-memory format for operational use.
Simulate Responses: Use the deserialized data to simulate or replicate the originally captured API responses.
Cleanup: After the simulation, clear the used data from memory to maintain optimal memory usage and system performance.
Advantages:
No Local File Creation: By handling data exclusively in memory and eliminating local file storage, file I/O operations are reduced, leading to faster processing and less potential for file management errors.
Single Upload: Consolidating all data into a single upload at the end of the recording phase minimizes network traffic and simplifies the data management pipeline.
Challenges:
Increased Memory Usage: Maintaining all configurations and data in memory can substantially increase memory consumption, particularly with large datasets.
Operational Delays: The asynchronous data upload process might introduce a delay during the transition from active recording to system closure, although users are made aware of this potential delay.
Incremental Configuration Management with Frequent S3 Updates
Data Capture Phase:
Start Data Capture: Capture API requests and responses.
Store Single Configuration in Memory: Each captured configuration is saved in memory.
Update and Upload:
For each new configuration, retrieve the current configuration file from S3.
Update the file with the new configuration data.
Re-upload the updated file to S3 using API Gateway integrations like AWS upload file to S3 API Gateway TypeScript for secure and scalable file uploads.
Clear the configuration from memory.
Stop Data Capture:
Upload any remaining configurations in memory to S3.
Notify the user that data capture has ceased.
Data Replay Phase:
Start Data Replay: Download the configuration file from S3.
Load Configurations: Transfer the configurations into memory.
Replay: Simulate API responses using the loaded configurations.
Stop Data Replay: Remove configurations from memory.
Pros:
Individual Configuration Upload: Provides granular control and simplifies debugging.
Cons:
High Network Overhead: Frequent download, update, and upload cycles increase network traffic.
Delay on Close: Introduces a delay when stopping the recording due to the upload process.
Complexity: Managing individual configurations adds significant complexity.
Batch Configuration Management with Threshold-Based Updates
Data Capture Phase:
Start Data Capture: Capture API requests and responses.
Store Configurations in Memory: Accumulate configurations until a preset count is reached.
Batch Update:
Download the current configuration file from S3.
Update it with a new batch of configurations.
Initiate an asynchronous upload of the updated file to S3.
Clear the batch from memory.
Stop Data Capture:
Update the configuration file with any remaining configurations and upload to S3.
Notify the user that data capture has stopped and updates are pending.
Data Replay Phase:
Start Data Replay: Download the configuration file from S3.
Load Configurations: Load configurations into memory.
Replay: Simulate API responses.
Stop Data Replay: Clear memory of configurations.
Pros:
Single File Management: Simplifies handling by storing all configurations in one file.
No Local File Creation: Reduces local storage needs.
Cons:
High Network Overhead: Batch updates involve significant network use.
Concurrency Issues: Risks of data conflicts during simultaneous file updates.
Delay on Stop: Stopping recording can be delayed by batch updates.
Resource Intensive: Handling large files can consume substantial resources.
Batch File Segregation
Data Capture Phase:
Start Data Capture: Capture API requests and responses.
Store Configurations in Memory: Save configurations until a limit is reached.
Batch Upload:
Serialize the batch of configurations and upload it to S3 as a "new configuration file."
Clear the batch from memory.
Stop Data Capture:
Upload any residual configurations as a final batch.
Notify the user that data capture has ended.
Data Replay Phase:
Start Data Replay: Download the required configuration files from S3.
Load Configurations: Transfer configurations into memory.
Replay: Use configurations to simulate responses.
Stop Data Replay: Remove configurations from memory.
Pros:
No Download-Update-Upload Cycle: Reduces network calls and simplifies the process.
Smooth Stop: Allows quick cessation of recording.
Cons:
Multiple Configuration Files: Creates numerous files, complicating management.
Replay Complexity: Aggregating multiple files for replay can be slow and cumbersome.
Bonus Use Case: AWS Glue from S3 to OpenSearch
For large-scale analytical or monitoring needs, configurations stored in AWS S3 can be transformed using AWS Glue and ingested into OpenSearch. This enables near real-time querying and visualizations of configurations or logs — a valuable strategy for ops teams dealing with dynamic infrastructure setups.
Conclusion
Efficient configuration management using AWS S3 unlocks scalability, performance, and automation across development workflows. By leveraging AWS services like Lambda, API Gateway, Amplify, and Glue, you can tailor your system to handle updates, uploads, and configuration replays without bottlenecks. Whether you're optimizing for minimal latency or ease of debugging, choosing the right upload strategy matters.
To dive deeper into related areas of developer tooling and cloud automation, check out these helpful reads from the Keploy blog:
Connecting a Hosted UI Website to an AWS EC2 Instance
Java Native Interface Deep Dive
10 Developer Communities to Be a Part of in 2025
Improving Code Quality with Automated Tools
For more innovations in developer productivity and test automation, visit www.keploy.io.






