














































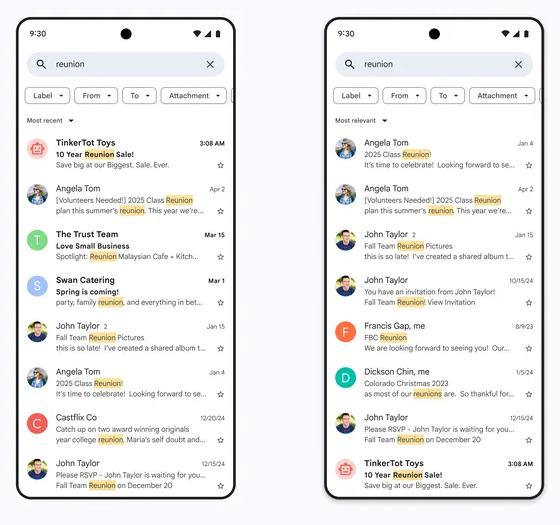















![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)









































































































_Federico_Caputo_Alamy.jpg?#)

































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)



















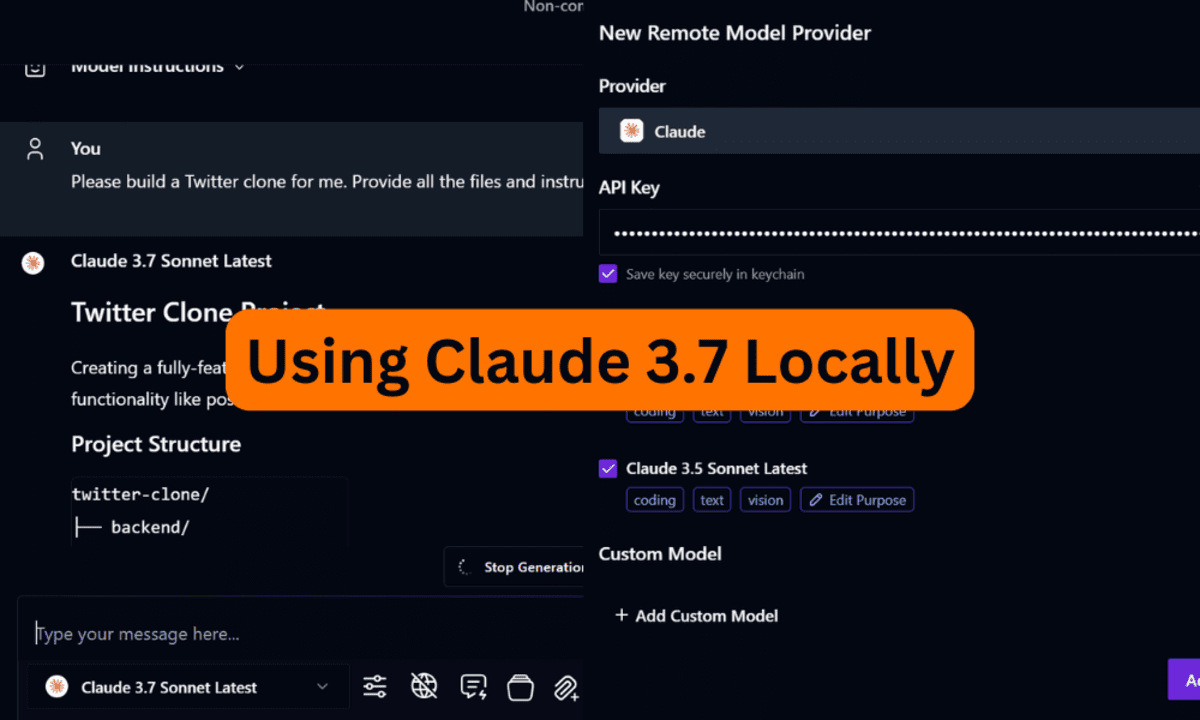





























































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)
































































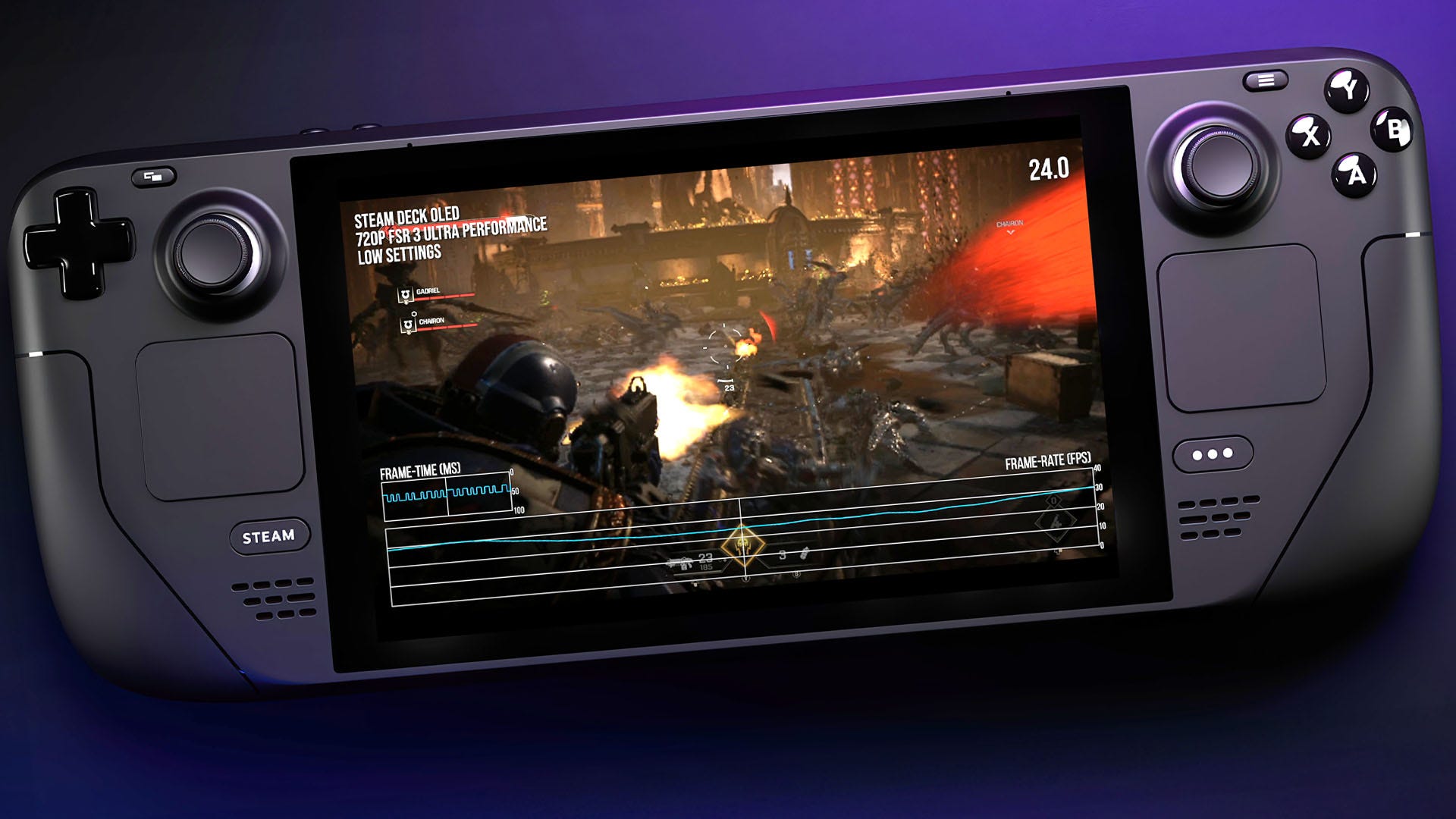



.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)




.png?#)














































How Do LLMs Reason? 5 Approaches Powering the Next Generation of AI
Large Language Models (LLMs) have come a long way since their early days of mimicking autocomplete on steroids. But generating fluent text isn’t enough – true intelligence demands reasoning. That means solving math problems, debugging code, drawing logical conclusions, and even reflecting on errors. Yet modern LLMs are trained to predict the next word, not […] The post How Do LLMs Reason? 5 Approaches Powering the Next Generation of AI appeared first on TOPBOTS.

Large Language Models (LLMs) have come a long way since their early days of mimicking autocomplete on steroids. But generating fluent text isn’t enough – true intelligence demands reasoning. That means solving math problems, debugging code, drawing logical conclusions, and even reflecting on errors. Yet modern LLMs are trained to predict the next word, not to think. So how are they suddenly getting better at reasoning?
The answer lies in a constellation of new techniques – from prompt engineering to agentic tool use – that nudge, coach, or transform LLMs into more methodical thinkers. Here’s a look at five of the most influential strategies pushing reasoning LLMs into new territory.
1. Chain-of-Thought Prompting: Teaching LLMs to “Think Step by Step”
One of the earliest and most enduring techniques to improve reasoning in LLMs is surprisingly simple: ask the model to explain itself.
Known as Chain-of-Thought (CoT) prompting, this method involves guiding the model to produce intermediate reasoning steps before giving a final answer. For instance, instead of asking “What’s 17 times 24?”, you prompt the model with “Let’s think step by step,” leading it to break down the problem: 17 × 24 = (20 × 17) + (4 × 17), and so on.
This idea, first formalized in 2022, remains foundational. OpenAI’s o1 model was trained to “think longer before answering” – essentially internalizing CoT-like reasoning chains. Its successor, o3, takes this further with simulated reasoning, pausing mid-inference to reflect and refine responses.
The principle is simple: by forcing intermediate steps, models avoid jumping to conclusions and better handle multi-step logic.
2. Inference-Time Compute Scaling: More Thinking per Question
If a question is hard, spend more time thinking – humans do this, and now LLMs can too.
Inference-time compute scaling boosts reasoning by allocating more compute during generation. Instead of a single output pass, models might generate multiple reasoning paths, then vote on the best one. This “self-consistency” method has become standard across reasoning benchmarks.
OpenAI’s o3-mini uses three reasoning effort options (low, medium, high) that determine how long the model reasons internally before answering. At high reasoning levels, o3-mini outperforms even the full o1 model on math and coding tasks.
A related technique, budget forcing, introduced in the 2025 paper s1: Simple Test-Time Scaling, uses special tokens to control reasoning depth. By appending repeated “Wait” tokens, the model is nudged to generate longer responses, self-verify, and correct itself. An end-of-thinking token like “Final Answer:” signals when to stop. This method improves accuracy by extending inference without modifying model weights – a modern upgrade to classic “think step by step” prompting.
The tradeoff is latency for accuracy, and for tough tasks, it’s often worth it.
3. Reinforcement Learning and Multi-Stage Training: Rewarding Good Reasoning
Another game-changer: don’t just predict words – reward correct logic.
Models like OpenAI’s o1 and DeepSeek-R1 are trained with reinforcement learning (RL) to encourage sound reasoning patterns. Instead of just imitating data, these models get rewards for producing logical multi-step answers. DeepSeek-R1’s first iteration, R1-Zero, used only RL – no supervised fine-tuning – and developed surprisingly powerful reasoning behaviors.
However, RL-only training led to issues like language instability. The final DeepSeek-R1 used multi-stage training: RL for reasoning and supervised fine-tuning for better readability. Similarly, Alibaba’s QwQ-32B combined a strong base model with continuous RL scaling to achieve elite performance in math and code.
The result? Models that not only get answers right, but do so for the right reasons – and can even learn to self-correct.
4. Self-Correction and Backtracking: Reasoning, Then Rewinding
What happens when the model makes a mistake? Can it catch itself?
Until recently, LLMs struggled with self-correction. In 2023, researchers found that simply asking a model to “try again” rarely improved the answer – and sometimes made it worse. But new work in 2025 introduces backtracking – a classic AI strategy now adapted to LLMs.
Wang et al. from Tencent AI Lab identified an “underthinking” issue in o1-style models: they jump between ideas instead of sticking with a line of reasoning. Their decoding strategy penalized thought-switching, encouraging deeper exploration of each idea.
Meanwhile, Yang et al. proposed self-backtracking – letting the model rewind when stuck, then explore alternate paths. This led to >40% accuracy improvements compared to approaches that solely relies on the optimal reasoning solutions.
These innovations effectively add search and planning capabilities at inference time, echoing classical AI methods like depth-first search, layered atop the flexible power of LLMs.
5. Tool Use and External Knowledge Integration: Reasoning Beyond the Model
Sometimes, reasoning means knowing when to ask for help.
Modern LLMs increasingly invoke external tools – calculators, code interpreters, APIs, even web search – to handle complex queries.
Alibaba’s QwQ-32B incorporates agent capabilities directly, letting it call functions or access APIs during inference. Google’s Gemini 2.0 (Flash Thinking) supports similar features – for example, it can enable code execution during inference, allowing the model to run and evaluate code as part of its reasoning process.
Why does this matter? Some tasks – like verifying real-time data, performing symbolic math, or executing code – are beyond the model’s internal capabilities. Offloading these subtasks lets the LLM focus on higher-order logic, dramatically improving accuracy and reliability.
In essence, tools let LLMs punch above their weight – like a digital Swiss Army knife, extending reasoning with precision instruments.
Conclusion: Reasoning Is a Stack, Not a Switch
LLMs don’t just “learn to reason” in one step – they acquire it through a layered set of techniques that span training, prompting, inference, and interaction with the world. CoT prompting adds structure. Inference-time scaling adds depth. RL adds alignment. Backtracking adds self-awareness. Tool use adds reach.
Top-performing models like OpenAI’s o1 and o3, DeepSeek’s R1, Google’s Gemini 2.0 Flash Thinking, and Alibaba’s QwQ combine several of these strategies – a hybrid playbook blending clever engineering with cognitive scaffolding.
As the field evolves, expect even tighter coupling between internal reasoning processes and external decision-making tools. We’re inching closer to LLMs that don’t just guess the next word – but genuinely think.
Enjoy this article? Sign up for more AI updates.
We’ll let you know when we release more summary articles like this one.
The post How Do LLMs Reason? 5 Approaches Powering the Next Generation of AI appeared first on TOPBOTS.




