






















































































.jpeg?#)














































































Для каких задач я жду "приличной RAG"
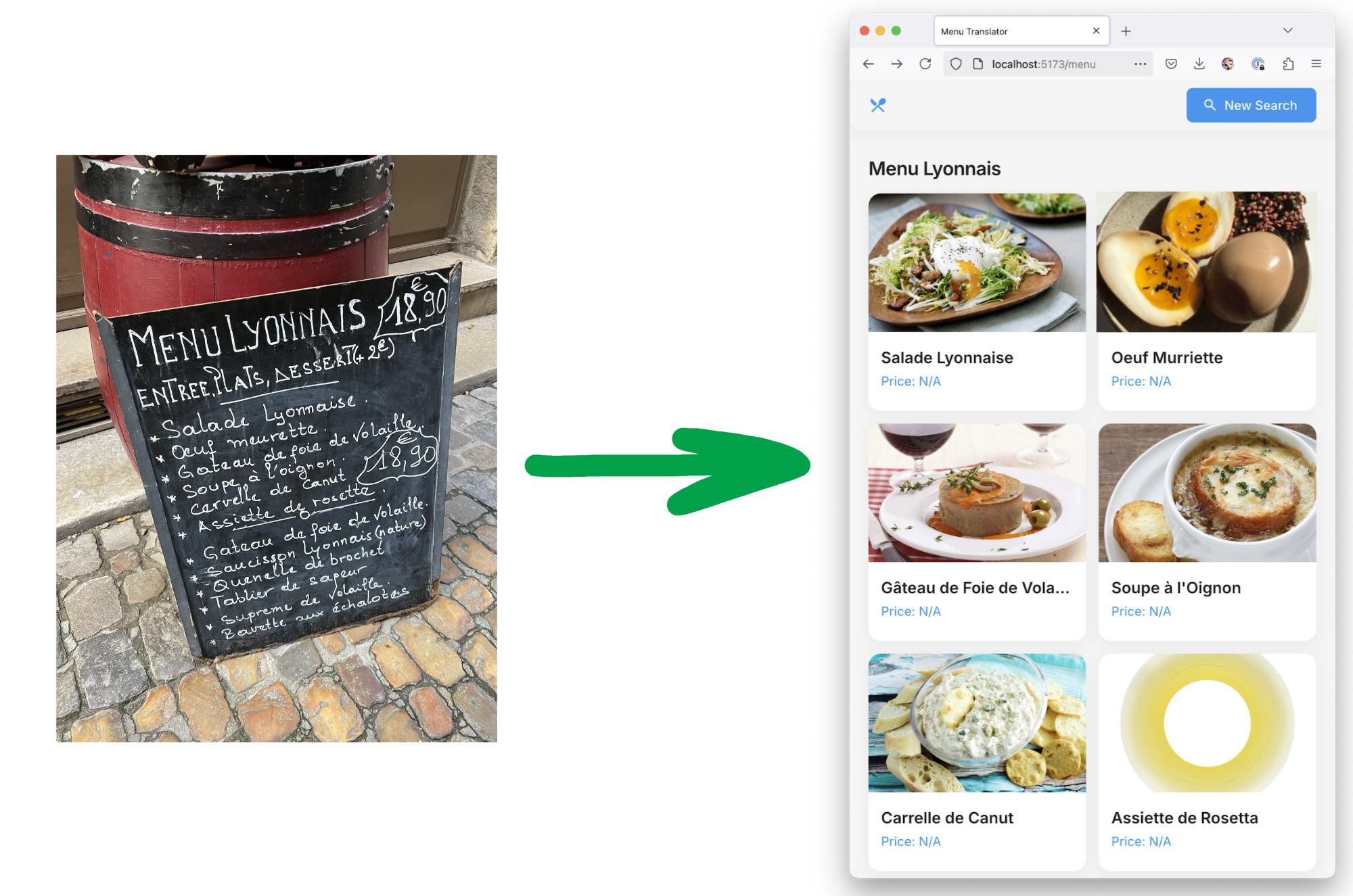
Регулярно спрашивают, почему я сам работаю с LLM, но в наших курсах на Aisystant выставлена какая-то рудиментарная RAG реализация -- и я явно не тороплюсь с ней работать.Первая задача — это у меня курсы, которые представляют собой десяток томов текста, плотно перевязанных по набору понятий. И в них ещё куча ссылок на первоисточники, они ж все привязаны к культуре. Надо уметь не просто отвечать на вопросы к этим текстам (скажем, вопросы студентов), а надо уметь отвечать на вообще все вопросы, исходя из содержания этих курсов (и есть ожидание, что ответы будут умнее, а перед ответами уточняющие вопросы будут точнее, по крайней мере с людьми, прошедшими эти курсы ровно такой эффект). И это же ответы не просто с рассуждениями, а с причинно-следственными рассуждениями.Вторая задача — вот огромный список книг по личному развитию (в том числе агентности, стратегированию и всему такому). Нашёл через упоминание Why Greatness Cannot Be planned: https://x.com/neuranne/status/1900513532304593009. Понятно, что прочесть такую кучу книг одному человеку невозможно. Но возможно сжать информацию оттуда (понимая, что много идей одних и тех же -- но терминология разная), профильтровать на рациональность (а как же!) и изложить в едином с нашими курсами языке.Какие там проблемы по пути:— надо работать с концептами, а не с лингвистикой. Скажем, LLM жутко отвечают на любые вопросы по эволюционной архитектуре: путают архитектуру строительную (где важна экология) и нейронных сетей (она фукнциональная) с собственно эволюционной архитектурой про связанность/сцепление и сплочённость/цельность модулей, а ещё по слову "эволюция" приплетают эволюционный поиск нейросетевых архитектур (NAS) и всю тематику меметических алгоритмов. Вот надо понимать, что важны типы — "косил косой косой косой" надо не лингвистически разбирать или вероятностно, а по смыслу. Собственно, онтологии где-то вот тут работают, но они должны работать "из коробки", а не прикручиваться болтами сбоку или делаться вообще вручную. Чтобы нормально работать с онтологиями и отстраиваться от лингвистики, надо иметь более умную модель, причём даже не reasoning, а вот прямо базовую.— минимальный объём, с которым работаем — десяток пухленьких томов "знаний как рассуждать про жизнь" (привязанных дальше к культуре, это уж "обычная LLM" должна потянуть, с учётом разбирательства с типами), а то и сотня томов, включая по десять томов первоисточников к каждому тому "целевой картины мира" и полдня рассуждений, и это не укладывается в два миллиона токенов контекста (у которых дикая сейчас деградация качества, начиная с конца первой сотни токенов), а RAG подтягивает изо всех этих текстов странное, и его надо как-то нечеловеческими усилиями настраивать, как показывают бенчмарки. Я знаю, что люди в OpenAI и в Microsoft говорят про LLM с бесконечным контекстом и тем самым бесконечной памятью, но там внутри просто обязан быть RAG, ибо структура памяти должна быть иерархической, это ж слоёная архитектура, азы инженерии. Но память должна быть ассоциативной, а не "адресной" -- и это как раз похоже на RAG. Там явное противоречие есть: "память обо всём" -- это сама LLM, которая вроде как "оперативная память", а ещё есть "память чата", токены для рассуждений и контекст все тут, а ещё есть собственно книги -- которые тем самым то ли в файнтюн должны пойти ("подтянуться в оперативку"), или так и остаться в RAG, подтягивание пойдёт "в чат". Место пока очень мутное.-- причинный вывод и causal RL пока не слишком развиваются, подробности с кучей ссылок на первоисточники были в https://ailev.livejournal.com/1757388.htmlЭто IMHO нужно очень многим, я думаю, что в течение года что-то такое будет. И даже на базе открытых моделей (ибо никогда не знаешь, какой SaaS посчитает тебя врагом [своего] народа, или хотя бы половину твоих пользователей -- или не посчитает, но "ничего личного, требование государства"). Задача абсолютно типовая (knowledge management на каком-нибудь предприятии ведь ровно про это). И на очень похожие задачи уже делают соревнования и есть какие-то бенчмарки, следить за этим вот тут: https://t.me/llm_under_hood.Почему же я жду, если всё понимаю? Потому как у меня никаких ресурсов не хватит такое делать сейчас себе самому из подручных материалов. При этом я разбираюсь и в онтологиях (см., например, мой последний проект в этой сфере -- https://github.com/TechInvestLab/dot15926), и тематику LLM отслеживаю, и хорошо понимаю про данные, которые у нас есть. Но я считаю, что мне сейчас полезней готовить данные для такой системы -- те самые десять томиков сами себя не напишут, textbook is all you need (и дальнейшее движение в этом направлении, подробней было в https://ailev.livejournal.com/1756659.html и чуть раньше в https://ailev.livejournal.com/1753048.html) рулит, писать курсы (получается, что для LLM++) это и есть пока моя роль в прогрессе человечества. Ну, и пока AI "на подходе", студенты вполне могут учиться по этим курсам.Это я нормально переписал второй абзац из lytdybr -- https://ailev.l

Регулярно спрашивают, почему я сам работаю с LLM, но в наших курсах на Aisystant выставлена какая-то рудиментарная RAG реализация -- и я явно не тороплюсь с ней работать.
Первая задача — это у меня курсы, которые представляют собой десяток томов текста, плотно перевязанных по набору понятий. И в них ещё куча ссылок на первоисточники, они ж все привязаны к культуре. Надо уметь не просто отвечать на вопросы к этим текстам (скажем, вопросы студентов), а надо уметь отвечать на вообще все вопросы, исходя из содержания этих курсов (и есть ожидание, что ответы будут умнее, а перед ответами уточняющие вопросы будут точнее, по крайней мере с людьми, прошедшими эти курсы ровно такой эффект). И это же ответы не просто с рассуждениями, а с причинно-следственными рассуждениями.
Вторая задача — вот огромный список книг по личному развитию (в том числе агентности, стратегированию и всему такому). Нашёл через упоминание Why Greatness Cannot Be planned: https://x.com/neuranne/status/1900513532304593009. Понятно, что прочесть такую кучу книг одному человеку невозможно. Но возможно сжать информацию оттуда (понимая, что много идей одних и тех же -- но терминология разная), профильтровать на рациональность (а как же!) и изложить в едином с нашими курсами языке.
Какие там проблемы по пути:
— надо работать с концептами, а не с лингвистикой. Скажем, LLM жутко отвечают на любые вопросы по эволюционной архитектуре: путают архитектуру строительную (где важна экология) и нейронных сетей (она фукнциональная) с собственно эволюционной архитектурой про связанность/сцепление и сплочённость/цельность модулей, а ещё по слову "эволюция" приплетают эволюционный поиск нейросетевых архитектур (NAS) и всю тематику меметических алгоритмов. Вот надо понимать, что важны типы — "косил косой косой косой" надо не лингвистически разбирать или вероятностно, а по смыслу. Собственно, онтологии где-то вот тут работают, но они должны работать "из коробки", а не прикручиваться болтами сбоку или делаться вообще вручную. Чтобы нормально работать с онтологиями и отстраиваться от лингвистики, надо иметь более умную модель, причём даже не reasoning, а вот прямо базовую.
— минимальный объём, с которым работаем — десяток пухленьких томов "знаний как рассуждать про жизнь" (привязанных дальше к культуре, это уж "обычная LLM" должна потянуть, с учётом разбирательства с типами), а то и сотня томов, включая по десять томов первоисточников к каждому тому "целевой картины мира" и полдня рассуждений, и это не укладывается в два миллиона токенов контекста (у которых дикая сейчас деградация качества, начиная с конца первой сотни токенов), а RAG подтягивает изо всех этих текстов странное, и его надо как-то нечеловеческими усилиями настраивать, как показывают бенчмарки. Я знаю, что люди в OpenAI и в Microsoft говорят про LLM с бесконечным контекстом и тем самым бесконечной памятью, но там внутри просто обязан быть RAG, ибо структура памяти должна быть иерархической, это ж слоёная архитектура, азы инженерии. Но память должна быть ассоциативной, а не "адресной" -- и это как раз похоже на RAG. Там явное противоречие есть: "память обо всём" -- это сама LLM, которая вроде как "оперативная память", а ещё есть "память чата", токены для рассуждений и контекст все тут, а ещё есть собственно книги -- которые тем самым то ли в файнтюн должны пойти ("подтянуться в оперативку"), или так и остаться в RAG, подтягивание пойдёт "в чат". Место пока очень мутное.
-- причинный вывод и causal RL пока не слишком развиваются, подробности с кучей ссылок на первоисточники были в https://ailev.livejournal.com/1757388.html
Это IMHO нужно очень многим, я думаю, что в течение года что-то такое будет. И даже на базе открытых моделей (ибо никогда не знаешь, какой SaaS посчитает тебя врагом [своего] народа, или хотя бы половину твоих пользователей -- или не посчитает, но "ничего личного, требование государства"). Задача абсолютно типовая (knowledge management на каком-нибудь предприятии ведь ровно про это). И на очень похожие задачи уже делают соревнования и есть какие-то бенчмарки, следить за этим вот тут: https://t.me/llm_under_hood.
Почему же я жду, если всё понимаю? Потому как у меня никаких ресурсов не хватит такое делать сейчас себе самому из подручных материалов. При этом я разбираюсь и в онтологиях (см., например, мой последний проект в этой сфере -- https://github.com/TechInvestLab/dot15926), и тематику LLM отслеживаю, и хорошо понимаю про данные, которые у нас есть. Но я считаю, что мне сейчас полезней готовить данные для такой системы -- те самые десять томиков сами себя не напишут, textbook is all you need (и дальнейшее движение в этом направлении, подробней было в https://ailev.livejournal.com/1756659.html и чуть раньше в https://ailev.livejournal.com/1753048.html) рулит, писать курсы (получается, что для LLM++) это и есть пока моя роль в прогрессе человечества. Ну, и пока AI "на подходе", студенты вполне могут учиться по этим курсам.
Это я нормально переписал второй абзац из lytdybr -- https://ailev.livejournal.com/1757388.html. Хотя в этом абзаце я поднял чуть больше тем: "Вопрос, чего я жду для использования LLM. Чтобы писать свои тексты -- ничего, регулярно использую. Лучше всего для моих целей идёт Gemini 2.0 Pro Experimental, очень крутая выдача. Следующий -- Grok 3 beta, абсолютно адекватно. Claude у меня платная через телеграм, тоже ОК, но пользую редко. На последнем месте -- платная GhatGPT. Это какое-то недоразумение: вроде ответы есть, но использовать их никак нельзя, выдаётся убогий клочок текста, и в нём сразу много ерунды, которую потом даже чистить не хочется. Похоже, что сетки тренируют на "олимпиадное программирование", навык очень полезный для бенчмарков, типа как "победитель олимпиады", но в моей работе-то надо совсем другое, мозги приставлять не к крутой логической/математической задаче с легко проверяемым ответом, а к вытаскиванию нужных типов объектов из огромной кучи сетевого мусора и отличать, например, архитектуру зданий и архитектуру нейросетей -- не пропускать sustainability как основной архитектурный тренд в инженерии, это у строителей тренд. Ну чисто как наши студенты в начале обучения: кресты металлические, запятая, кресты католические). А вот чтобы выпускать LLM на студентов, я жду какого-нибудь удобного фреймворка с RAG -- и отслеживаю то, что происходит вот тут: https://t.me/llm_under_hood. При этом я уже дёргался поставить себе Cursor, чтобы потренироваться (давненько я не брал в руки шашек! А ведь в далёкой молодости меня считали суперпрограммистом, и даже среди читателей этих строк есть такие, кто такое помнит). Но опомнился в последнюю минуту -- это же интересно, но это могу и не я делать. А вот переписывать "Системную инженерию", а затем "Инженерию личности" кроме меня никто не будет. И я убеждён, что это таки сейчас надо делать, и делать надо мне. И я трачу на это full time, а всё остальное время читаю ленты про AI".
Пошёл дописывать "Системную инженерию", там осталось 30%. Сегодня я писатель. Картинка про это, "бурную дискуссию вызвал вопрос, кто является работодателем писателя", https://litinstitut.ru/content/proekt-standarta-professii-pisatel-obsuzhdenie-nachalos-v-literaturnom-institute. Это 2022 год, GhatGPT вышла как раз в марте 2023, твит Altman про "писательскую модель" вышел в марте 2025 (https://x.com/sama/status/1899535387435086115), всё быстро. Хотя это всё про "художественных писателей", а я много ближе к техническим.
Первая задача — это у меня курсы, которые представляют собой десяток томов текста, плотно перевязанных по набору понятий. И в них ещё куча ссылок на первоисточники, они ж все привязаны к культуре. Надо уметь не просто отвечать на вопросы к этим текстам (скажем, вопросы студентов), а надо уметь отвечать на вообще все вопросы, исходя из содержания этих курсов (и есть ожидание, что ответы будут умнее, а перед ответами уточняющие вопросы будут точнее, по крайней мере с людьми, прошедшими эти курсы ровно такой эффект). И это же ответы не просто с рассуждениями, а с причинно-следственными рассуждениями.
Вторая задача — вот огромный список книг по личному развитию (в том числе агентности, стратегированию и всему такому). Нашёл через упоминание Why Greatness Cannot Be planned: https://x.com/neuranne/status/1900513532304593009. Понятно, что прочесть такую кучу книг одному человеку невозможно. Но возможно сжать информацию оттуда (понимая, что много идей одних и тех же -- но терминология разная), профильтровать на рациональность (а как же!) и изложить в едином с нашими курсами языке.
Какие там проблемы по пути:
— надо работать с концептами, а не с лингвистикой. Скажем, LLM жутко отвечают на любые вопросы по эволюционной архитектуре: путают архитектуру строительную (где важна экология) и нейронных сетей (она фукнциональная) с собственно эволюционной архитектурой про связанность/сцепление и сплочённость/цельность модулей, а ещё по слову "эволюция" приплетают эволюционный поиск нейросетевых архитектур (NAS) и всю тематику меметических алгоритмов. Вот надо понимать, что важны типы — "косил косой косой косой" надо не лингвистически разбирать или вероятностно, а по смыслу. Собственно, онтологии где-то вот тут работают, но они должны работать "из коробки", а не прикручиваться болтами сбоку или делаться вообще вручную. Чтобы нормально работать с онтологиями и отстраиваться от лингвистики, надо иметь более умную модель, причём даже не reasoning, а вот прямо базовую.
— минимальный объём, с которым работаем — десяток пухленьких томов "знаний как рассуждать про жизнь" (привязанных дальше к культуре, это уж "обычная LLM" должна потянуть, с учётом разбирательства с типами), а то и сотня томов, включая по десять томов первоисточников к каждому тому "целевой картины мира" и полдня рассуждений, и это не укладывается в два миллиона токенов контекста (у которых дикая сейчас деградация качества, начиная с конца первой сотни токенов), а RAG подтягивает изо всех этих текстов странное, и его надо как-то нечеловеческими усилиями настраивать, как показывают бенчмарки. Я знаю, что люди в OpenAI и в Microsoft говорят про LLM с бесконечным контекстом и тем самым бесконечной памятью, но там внутри просто обязан быть RAG, ибо структура памяти должна быть иерархической, это ж слоёная архитектура, азы инженерии. Но память должна быть ассоциативной, а не "адресной" -- и это как раз похоже на RAG. Там явное противоречие есть: "память обо всём" -- это сама LLM, которая вроде как "оперативная память", а ещё есть "память чата", токены для рассуждений и контекст все тут, а ещё есть собственно книги -- которые тем самым то ли в файнтюн должны пойти ("подтянуться в оперативку"), или так и остаться в RAG, подтягивание пойдёт "в чат". Место пока очень мутное.
-- причинный вывод и causal RL пока не слишком развиваются, подробности с кучей ссылок на первоисточники были в https://ailev.livejournal.com/1757388.html
Это IMHO нужно очень многим, я думаю, что в течение года что-то такое будет. И даже на базе открытых моделей (ибо никогда не знаешь, какой SaaS посчитает тебя врагом [своего] народа, или хотя бы половину твоих пользователей -- или не посчитает, но "ничего личного, требование государства"). Задача абсолютно типовая (knowledge management на каком-нибудь предприятии ведь ровно про это). И на очень похожие задачи уже делают соревнования и есть какие-то бенчмарки, следить за этим вот тут: https://t.me/llm_under_hood.
Почему же я жду, если всё понимаю? Потому как у меня никаких ресурсов не хватит такое делать сейчас себе самому из подручных материалов. При этом я разбираюсь и в онтологиях (см., например, мой последний проект в этой сфере -- https://github.com/TechInvestLab/dot15926), и тематику LLM отслеживаю, и хорошо понимаю про данные, которые у нас есть. Но я считаю, что мне сейчас полезней готовить данные для такой системы -- те самые десять томиков сами себя не напишут, textbook is all you need (и дальнейшее движение в этом направлении, подробней было в https://ailev.livejournal.com/1756659.html и чуть раньше в https://ailev.livejournal.com/1753048.html) рулит, писать курсы (получается, что для LLM++) это и есть пока моя роль в прогрессе человечества. Ну, и пока AI "на подходе", студенты вполне могут учиться по этим курсам.
Это я нормально переписал второй абзац из lytdybr -- https://ailev.livejournal.com/1757388.html. Хотя в этом абзаце я поднял чуть больше тем: "Вопрос, чего я жду для использования LLM. Чтобы писать свои тексты -- ничего, регулярно использую. Лучше всего для моих целей идёт Gemini 2.0 Pro Experimental, очень крутая выдача. Следующий -- Grok 3 beta, абсолютно адекватно. Claude у меня платная через телеграм, тоже ОК, но пользую редко. На последнем месте -- платная GhatGPT. Это какое-то недоразумение: вроде ответы есть, но использовать их никак нельзя, выдаётся убогий клочок текста, и в нём сразу много ерунды, которую потом даже чистить не хочется. Похоже, что сетки тренируют на "олимпиадное программирование", навык очень полезный для бенчмарков, типа как "победитель олимпиады", но в моей работе-то надо совсем другое, мозги приставлять не к крутой логической/математической задаче с легко проверяемым ответом, а к вытаскиванию нужных типов объектов из огромной кучи сетевого мусора и отличать, например, архитектуру зданий и архитектуру нейросетей -- не пропускать sustainability как основной архитектурный тренд в инженерии, это у строителей тренд. Ну чисто как наши студенты в начале обучения: кресты металлические, запятая, кресты католические). А вот чтобы выпускать LLM на студентов, я жду какого-нибудь удобного фреймворка с RAG -- и отслеживаю то, что происходит вот тут: https://t.me/llm_under_hood. При этом я уже дёргался поставить себе Cursor, чтобы потренироваться (давненько я не брал в руки шашек! А ведь в далёкой молодости меня считали суперпрограммистом, и даже среди читателей этих строк есть такие, кто такое помнит). Но опомнился в последнюю минуту -- это же интересно, но это могу и не я делать. А вот переписывать "Системную инженерию", а затем "Инженерию личности" кроме меня никто не будет. И я убеждён, что это таки сейчас надо делать, и делать надо мне. И я трачу на это full time, а всё остальное время читаю ленты про AI".
Пошёл дописывать "Системную инженерию", там осталось 30%. Сегодня я писатель. Картинка про это, "бурную дискуссию вызвал вопрос, кто является работодателем писателя", https://litinstitut.ru/content/proekt-standarta-professii-pisatel-obsuzhdenie-nachalos-v-literaturnom-institute. Это 2022 год, GhatGPT вышла как раз в марте 2023, твит Altman про "писательскую модель" вышел в марте 2025 (https://x.com/sama/status/1899535387435086115), всё быстро. Хотя это всё про "художественных писателей", а я много ближе к техническим.



