

















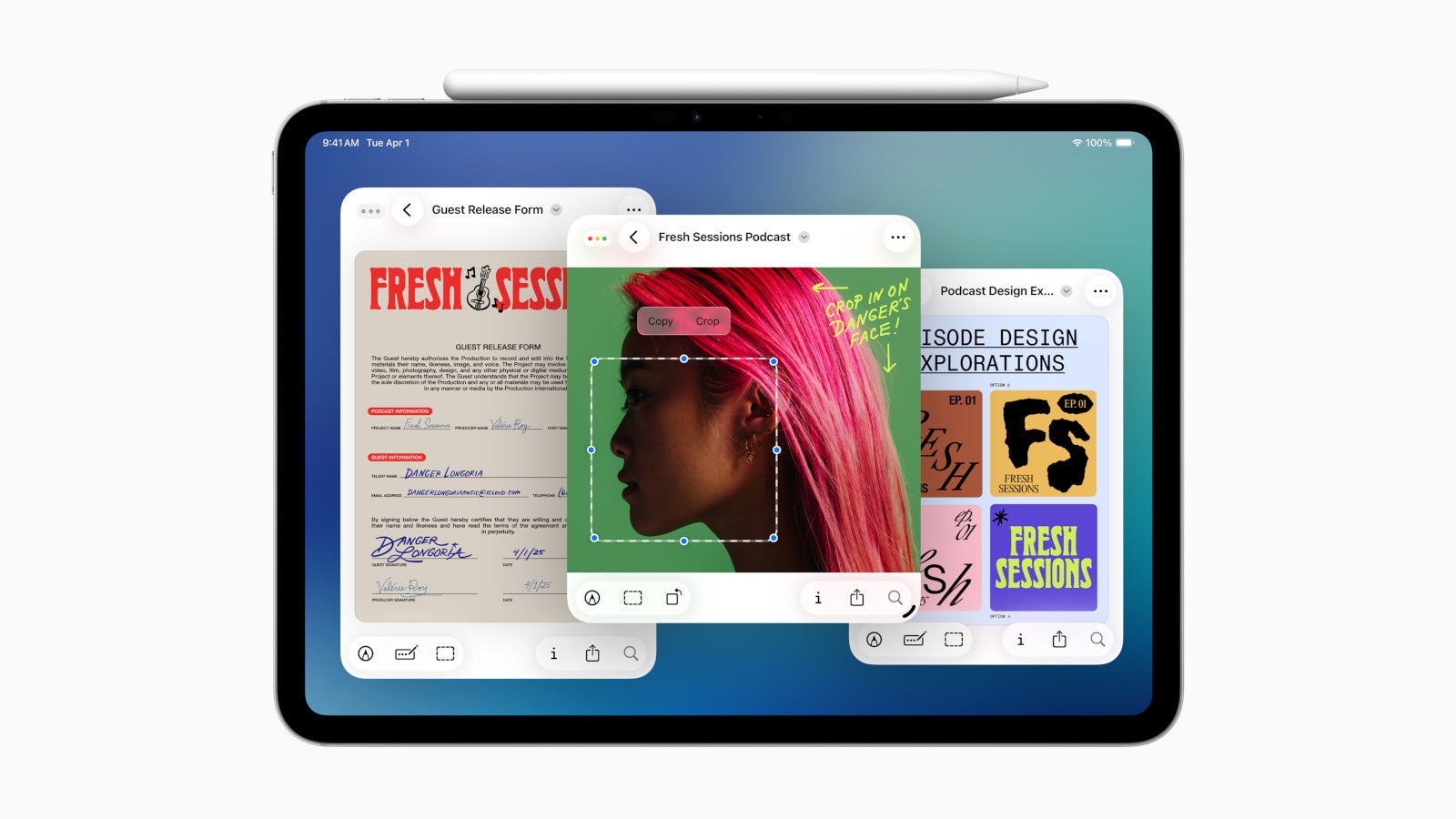













































![Apple Shares Teaser Trailer for 'The Lost Bus' Starring Matthew McConaughey [Video]](https://www.iclarified.com/images/news/97582/97582/97582-640.jpg)


![Apple Debuts Trailer for Third Season of 'Foundation' [Video]](https://www.iclarified.com/images/news/97589/97589/97589-640.jpg)









































































































.webp?#)

_incamerastock_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![Top Features of Vision-Based Workplace Safety Tools [2025]](https://static.wixstatic.com/media/379e66_7e75a4bcefe14e4fbc100abdff83bed3~mv2.jpg/v1/fit/w_1000,h_884,al_c,q_80/file.png?#)





























![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)















































































































































































































































How to create a job management for a hybrid cloud/on-premise software?
I am exploring the state-of-the-art methods to create a service that can run and scale in both cloud (container) and on-premise environments. The current version of the software is designed for on-premise use. It can run in a container, but it doesn't support simply spawning new pods, because the software cannot work with unknown worker. Therefore, I am looking for ways to develop a new version that functions similarly to the old one without introducing additional third-party software. The software will be written in Java using Quarkus to create native images. It includes a database that stores metadata. The software executes jobs from a job queue, those jobs will work on the metadata stored in the database with read an write, depending on the job. Initially, there might be one service running with one database, which works fine. However, at some point, it will need to scale to 2, 3, or even 10 instances of the service. All these instances must work on the same job queue in which each job will read or write new metadata to the database. Implementing a job queue for a standalone service is not hard but having the option to scale the service horizontally needs a way to synchronize the queue so all services are able to fetch new work. My questions are: Are there any feasible ways to implement a job queue that does not depend on external messaging software like Kafka or RabbitMQ? I am interested in knowing if it is possible to create a scalable application that functions effectively without additional dependencies. How do databases perform when accessed by multiple clients? I typically use PostgreSQL, but the system might also need to support MSSQL and Oracle SQL. I am unsure how these databases will perform with thousands or more requests. How do they scale? While PostgreSQL offers replication, I don't think this will be sufficient. Edit: I just came across https://quarkus.io/guides/messaging#internal-channels, it says: In some use cases, it is convenient to use messaging patterns to transfer messages inside the same application. When you don’t connect a channel to a messaging backend, i.e. a connector, everything happens internally to the application, and the streams are created by chaining methods together. Each chain is still a reactive stream and enforces the back-pressure protocol. Something like this, but working across multiple instances. Or some way to let the workers share their work independently, without a middleman like Kafka and such.
I am exploring the state-of-the-art methods to create a service that can run and scale in both cloud (container) and on-premise environments.
The current version of the software is designed for on-premise use. It can run in a container, but it doesn't support simply spawning new pods, because the software cannot work with unknown worker. Therefore, I am looking for ways to develop a new version that functions similarly to the old one without introducing additional third-party software.
The software will be written in Java using Quarkus to create native images. It includes a database that stores metadata. The software executes jobs from a job queue, those jobs will work on the metadata stored in the database with read an write, depending on the job. Initially, there might be one service running with one database, which works fine. However, at some point, it will need to scale to 2, 3, or even 10 instances of the service. All these instances must work on the same job queue in which each job will read or write new metadata to the database. Implementing a job queue for a standalone service is not hard but having the option to scale the service horizontally needs a way to synchronize the queue so all services are able to fetch new work.
My questions are:
- Are there any feasible ways to implement a job queue that does not depend on external messaging software like Kafka or RabbitMQ? I am interested in knowing if it is possible to create a scalable application that functions effectively without additional dependencies.
- How do databases perform when accessed by multiple clients? I typically use PostgreSQL, but the system might also need to support MSSQL and Oracle SQL. I am unsure how these databases will perform with thousands or more requests. How do they scale? While PostgreSQL offers replication, I don't think this will be sufficient.
Edit: I just came across https://quarkus.io/guides/messaging#internal-channels, it says:
In some use cases, it is convenient to use messaging patterns to transfer messages inside the same application. When you don’t connect a channel to a messaging backend, i.e. a connector, everything happens internally to the application, and the streams are created by chaining methods together. Each chain is still a reactive stream and enforces the back-pressure protocol.
Something like this, but working across multiple instances. Or some way to let the workers share their work independently, without a middleman like Kafka and such.
