



























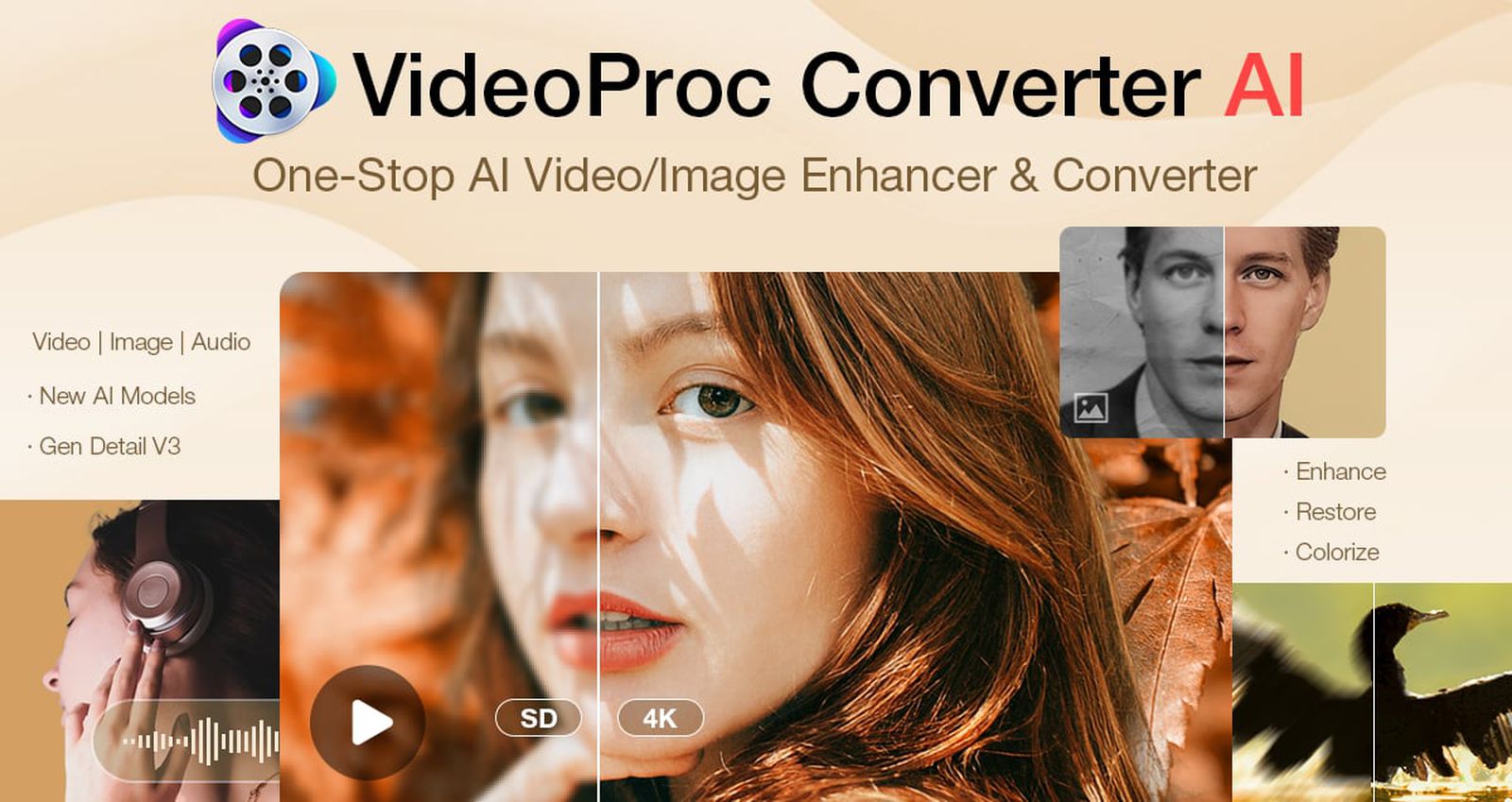




































![Sonos Father's Day Sale: Save Up to 26% on Arc Ultra, Ace, Move 2, and More [Deal]](https://www.iclarified.com/images/news/97469/97469/97469-640.jpg)













































































































.webp?#)


_Delphotos_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































































![[The AI Show Episode 150]: AI Answers: AI Roadmaps, Which Tools to Use, Making the Case for AI, Training, and Building GPTs](https://www.marketingaiinstitute.com/hubfs/ep%20150%20cover.png)
![[The AI Show Episode 149]: Google I/O, Claude 4, White Collar Jobs Automated in 5 Years, Jony Ive Joins OpenAI, and AI’s Impact on the Environment](https://www.marketingaiinstitute.com/hubfs/ep%20149%20cover.png)























































































































































![How to Survive in Tech When Everything's Changing w/ 21-year Veteran Dev Joe Attardi [Podcast #174]](https://cdn.hashnode.com/res/hashnode/image/upload/v1748483423794/0848ad8d-1381-474f-94ea-a196ad4723a4.png?#)































































































From BI to GenAI: Hire Data Scientists in to Bridge the Gap
The future belongs to those companies who recognize data engineering as the secret to success in AI. As GenAI capabilities continue to change constantly, infrastructure requirements will become increasingly complex. Companies who bridge these gaps before they become a problem will be ideally positioned to capitalize on upcoming opportunities, while companies who dismiss data engineering will play a never-ending game of catch-up in an increasingly AI-powered world.

The Shift No One Predicted
Business Intelligence was the height of data strategy. Organizations would hire data scientists to develop dashboards, reports, and historical trend analysis. Fast forward to today, and generative AI has altered the whole landscape. The gap between prior BI and new GenAI isn't technical, it is philosophical, architectural, and operational.
Data engineers are the behind-the-scenes heroes of this revolution. While everyone is scrambling to hire AI and machine learning talent, the real bottleneck is at the infrastructure level. GenAI applications need real-time data pipelines, huge computational power, and integration capabilities smooth enough that old-school BI systems simply can't cope with.
Why Traditional BI Falls Short in the GenAI Era
Legacy BI systems were built in another era. They perform well against "what happened" type questions but struggle with the "what could happen" type of questions that GenAI is so good at answering. The batch mentality, rigid schemas, and report-centric architectures lead to resistance as organizations try to capitalize on generative AI solutions.
The data requirements for GenAI are qualitatively different. Whereas BI applications run with pre-cleaned, formatted data, GenAI models need to be able to work with raw, unstructured data from any source. They should have the capability to learn indefinitely, infer on the fly, and digest vast volumes of text, images, and other forms of media.
Companies that hire data scientists on a contract basis without making promises of quality data engineering infrastructure end up trapped in proof-of-concept hell. Their models work stunningly well under contained conditions but fail when deployed at scale because underlying data architecture cannot keep pace with production GenAI application requirements
The Infrastructure Challenge
Designing GenAI-ready infrastructure requires a complete rewrite of data architecture. Data engineers must design systems for processing streaming data, supporting vector databases, managing model artifacts, and supporting low-latency responses for real-time AI applications.
This complexity is further increased when the question of data governance and compliance comes into play. GenAI models usually train on complex data sets and therefore raise data lineage, privacy, and compliance-related issues. Data engineers then find themselves as the guardians of this complex ecosystem, granting the AI models access to data they need while having security and compliance controls in place.
Storage approaches also shift completely. Historical data warehouses for analytical queries are not optimized for storage patterns required by big language models and vector embeddings. Data engineers will need to architect hybrid solutions that would scale well for older legacy BI workloads as well as newer AI workloads.
Smart companies hire data scientists and data engineers as complementary teams rather than competitive roles. Data engineers concentrate on building sturdy, scalable data pipelines that will satisfy today's BI needs and future's AI projects. It means deploying next-generation data stacks with cloud-native technology, deploying effective data governance frameworks, and designing elastic architectures to adapt to shifting demands.
Successful migrations are mostly characterized by phased migration architectures. Rather than incrementally upgrading BI environments in a one-night cutover, data engineers build side-by-side environments that can subsequently manage legacy analytics and GenAI workloads. This reduces disruption while leveraging existing investment.
Feature stores themselves are now a critical component of this bridge-building process. They serve as the bridge between historical data warehouses and AI models, providing governed, consistent access to features needed for reporting and machine learning use cases.
The Competitive Advantage
Those who manage to bridge the BI-to-GenAI chasm harvest much competitive value. They can leverage their current investments in data with new superpowers like content creation, smart decision-making, and predictive analytics at scale.
These firms that hire data scientists and skilled data engineers establish win-win alliances where AI innovation is powered by data infrastructure and data practices are driven by AI applications. It is this self-reinforcing cycle that powers digital transformation and constructs sustainable competitive moats.




