![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)







































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































































Integrating Full-Text Search with Hibernate Search in a Java Application
This article demonstrates full-text search integration using Hibernate Search in a Java 8+ application with Hibernate ORM for relational database storage. The first section (Basics) gives a high level overview, and the second section (DEMO) provides example project and explains it's crucial parts. The project presents some more complex use case scenario, using custom analyzers, edgeNgram, and larger projections. Simple examples are omitted, as they can be found in the official Hibernate documentation. ⚠️ This is not a one-size-fits-all solution for every full-text search requirement. Hibernate Search is optimized for handling large datasets and high-throughput applications. Also, the extra resource greedy search engine is required. For different use cases, alternatives like client-side search or PostgreSQL's full-text search capabilities might be more suitable. However, these approaches are beyond the scope of this article. Basics This guide is based on Hibernate Search 6.1 documentation. For additional details, refer to the official documentation. Why Hibernate Search? Implementing full-text search in an application can be challenging, but Hibernate Search simplifies the process by offering a built-in solution that requires minimal configuration. It seamlessly integrates with powerful search engines like Elasticsearch and Lucene, enabling efficient and scalable search capabilities. In the diagram below, the blue section represents a typical application that uses Hibernate ORM to interact with a relational database. The red section highlights the additional infrastructure required to enable full-text search with Hibernate Search. However, introducing a search engine also means dealing with data synchronization between the database and the search index. Synchronization Challenges & Solutions Since Hibernate Search maintains a separate index in Elasticsearch, data must be kept synchronized. The default solution is automatic synchronization, which replicates all database modifications to the search index in real-time. However, for some use cases, automatic synchronization may not be optimal. Instead, batch synchronization (e.g., updating once a day) can be more efficient. Querying the Data Once the data is indexed and synchronized, Hibernate Search provides two primary ways to execute search queries: Query Elasticsearch to retrieve only indexes, then fetch corresponding data from the database. Query Elasticsearch to retrieve data directly, without additional database queries (using projections). For a more detailed explanation, checkout the next presentation: DEMO - Spring Boot Application with Full-Text Search Netz00 / hibernate-search-6-example Simple Spring Boot application demonstrating Hibernate Search 6 advanced usage Hibernate Search 6 Example Simple Spring Boot application demonstrating Hibernate Search 6 usage with Elasticsearch. Hibernate Search 6.1.7.Final: Reference Documentation Example app ER diagram: Full text search is available for Freelancer and Project entities. Indexing Entities Project Freelancer Freelancer categories 3 search examples: searchProjectsEntities demonstrates basic full text search of projects by project name searchProjects demonstrates previous example with projections usage searchFreelancers demonstrates full text search of freelancers (with projections) by username first name last name categories (M:N relationship) Creating custom edgeNgram analyser Running the Application Before starting the Spring Boot application, ensure that the necessary Docker containers are running. docker compose -f deployment/docker-compose-dev.yaml up -d Running Tests: newman run ./backend/src/test/postman/Hibernate-search-6-example.postman_collection.json -e ./backend/src/test/postman/Test\ Environment.postman_environment.json --reporters cli,json --reporter-json-export ./backend/src/test/postman/output/outputfile.json Import postman collection from here Elasticsearch browser extension: https://elasticvue.com/ Extras Paginated fetching of child entities over parent entity at unidirectional OneToMany relationship CREDITS Mapping only required fields with MapStruct by defining… View on GitHub This example shows how Hibernate Search fits into a Spring Boot architecture, covering everything from controllers to the search engine and back, including handling real life scenarios. The following section explains crucial parts. Adding Full-Text Search For development, we configure Elasticsearch as a single-node cluster running on the same server as the application, single backend configuration. RAM usage is limited to prevent excessive memory consumption. You can use ElasticVue to explore your data. Also, it is good practice to secure Elasticsearch by enabling security and provid
This article demonstrates full-text search integration using Hibernate Search in a Java 8+ application with Hibernate ORM for relational database storage.
The first section (Basics) gives a high level overview, and the second section (DEMO) provides example project and explains it's crucial parts. The project presents some more complex use case scenario, using custom analyzers, edgeNgram, and larger projections. Simple examples are omitted, as they can be found in the official Hibernate documentation.
⚠️ This is not a one-size-fits-all solution for every full-text search requirement. Hibernate Search is optimized for handling large datasets and high-throughput applications. Also, the extra resource greedy search engine is required. For different use cases, alternatives like client-side search or PostgreSQL's full-text search capabilities might be more suitable. However, these approaches are beyond the scope of this article.
Basics
This guide is based on Hibernate Search 6.1 documentation. For additional details, refer to the official documentation.
Why Hibernate Search?
Implementing full-text search in an application can be challenging, but Hibernate Search simplifies the process by offering a built-in solution that requires minimal configuration. It seamlessly integrates with powerful search engines like Elasticsearch and Lucene, enabling efficient and scalable search capabilities.
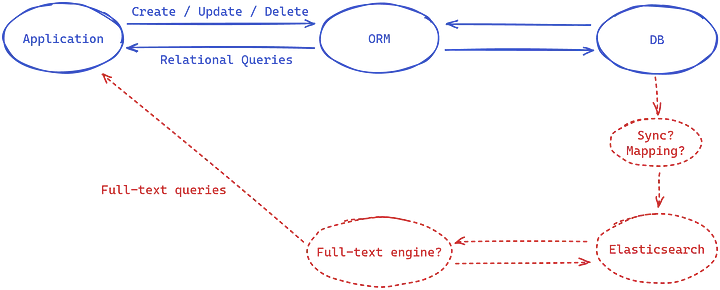
In the diagram below, the blue section represents a typical application that uses Hibernate ORM to interact with a relational database. The red section highlights the additional infrastructure required to enable full-text search with Hibernate Search.
However, introducing a search engine also means dealing with data synchronization between the database and the search index.
Synchronization Challenges & Solutions
Since Hibernate Search maintains a separate index in Elasticsearch, data must be kept synchronized. The default solution is automatic synchronization, which replicates all database modifications to the search index in real-time. However, for some use cases, automatic synchronization may not be optimal. Instead, batch synchronization (e.g., updating once a day) can be more efficient.
Querying the Data
Once the data is indexed and synchronized, Hibernate Search provides two primary ways to execute search queries:
- Query Elasticsearch to retrieve only indexes, then fetch corresponding data from the database.
- Query Elasticsearch to retrieve data directly, without additional database queries (using projections).
For a more detailed explanation, checkout the next presentation:
DEMO - Spring Boot Application with Full-Text Search
 Netz00
/
hibernate-search-6-example
Netz00
/
hibernate-search-6-example
Simple Spring Boot application demonstrating Hibernate Search 6 advanced usage
Hibernate Search 6 Example
Simple Spring Boot application demonstrating Hibernate Search 6 usage with Elasticsearch.
Hibernate Search 6.1.7.Final: Reference Documentation
Example app
ER diagram:

Full text search is available for Freelancer and Project entities.
Indexing Entities
3 search examples:
-
searchProjectsEntities demonstrates basic full text search of projects by
- project name
-
searchProjects demonstrates previous example with projections usage
-
searchFreelancers demonstrates full text search of freelancers (with projections) by
- username
- first name
- last name
- categories (M:N relationship)
Creating custom edgeNgram analyser
Running the Application
Before starting the Spring Boot application, ensure that the necessary Docker containers are running.
docker compose -f deployment/docker-compose-dev.yaml up -d
Running Tests:
newman run ./backend/src/test/postman/Hibernate-search-6-example.postman_collection.json -e ./backend/src/test/postman/Test\ Environment.postman_environment.json --reporters cli,json --reporter-json-export ./backend/src/test/postman/output/outputfile.json
Import postman collection from here
Elasticsearch browser extension: https://elasticvue.com/
Extras
This example shows how Hibernate Search fits into a Spring Boot architecture, covering everything from controllers to the search engine and back, including handling real life scenarios. The following section explains crucial parts.
Adding Full-Text Search
For development, we configure Elasticsearch as a single-node cluster running on the same server as the application, single backend configuration. RAM usage is limited to prevent excessive memory consumption. You can use ElasticVue to explore your data. Also, it is good practice to secure Elasticsearch by enabling security and providing password for default user “elastic”. Advanced security options are not included in the free Security functionality.
ℹ️ Hibernate container configuration, maven dependencies and hibernate configuration can be found in repository.
Indexing Entities
Which data should be indexed? Hibernate Search offers annotations that allow developers to control this behavior.
To index an entity, annotate the class with @Indexed(index = "index_name"). Following annotation will create an empty index inside Elasticsearch with name idx_comment.
@Entity
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Getter
@Setter
@Table(name = "comment")
@Indexed(index="idx_comment")
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "sequenceGenerator")
@SequenceGenerator(name = "sequenceGenerator")
@Column(name = "id")
private Long id;
In order to map entity properties into index fields they also need to be annotated. Multiple annotations on same entity property are allowed. Following entity properties annotations will be explained:
-
@FullTextField– For analyzed text fields (supports tokenization and filtering). -
@KeywordField– For exact match searches and sorting. -
@GenericField– For other data types like Long or Date. -
@IndexedEmbedded– For nested objects (e.g., searching Students by Course name).
@FullTextField
Works only with String and configures field as text. Text will be analyzed before indexing or searching. Analyzers consists of tokenizer and filters. Tokenizer splits the string to substring which are then processed by filters. That means before indexing, string "Thinking in Java" will be tokenized to ["Thinking", "in", "Java"] and then several filters can be applied, such as lowercase all chars or remove stop words… Then while searching "same steps" will be repeated on query. It is possible to configure different analyzers for indexing and for searching through configuration. Finally if user searched for "Learning Java" it will be tokenized to ["Learning", "Java"] and "Java" will match stored "Java" (Thinking in Java) which will be considered as match and “Thinking in Java” will be returned as result! Text fields can’t be sorted but the following annotation solves that problem (keyword).
It is possible to make custom analyzers combining specific tokenizer and filters. Except whitespace tokenizer and lowercase filter there are many others available here.

@KeywordField
Works only with String and configures the field as a keyword. On keyword fields only normalizers can be applied (no analyzers). Normalizers are similar to analyzers but without tokenizing.
That means before indexing, the string “Thinking in Java” can only be normalized and will be stored as a single keyword. Also, while searching, the term will be also normalized and the previous example wouldn’t match. This type is useful for sorting operation. Also we can combine keyword and fulltext field on same field.
@GenericField
A good default choice that will work for every property type with built-in support.
In the example it is used for Date and Long (primary key).
@IndexedEmbedded
The @IndexedEmbedded annotation is used to include fields from associated entities in the search index of the owning entity. This enables searching across nested object fields.
For example, consider an entity Student with a @ManyToMany association to a Course entity. By using @IndexedEmbedded on the courses field, you can perform a search for Student entities based on the name of the associated Course.
This annotation works with various types of associations, including @OneToOne, @OneToMany, and @ManyToMany.
It is not necessary to annotate the associated (nested) entity with @Indexed, unless you also want to index it independently. The following example demonstrates this usage:
@Indexed(index = "idx_student")
public class Student {
...
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinTable(
name = "student_courses",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id"))
@IndexedEmbedded(name = "courses", includePaths = {"name"})
private Set<Course> courses = new HashSet<>();
...
}
public class Course {
...
@Column(name = "name")
@KeywordField(name = "name", normalizer = "lowercase", projectable = Projectable.YES)
private String name;
...
}
Hibernate Search automatically detects whether an entity should be reindexed at field level. For example, updating non-indexed fields does not trigger reindexing, which optimizes performance.
More annotations and explanations can be found here.
Handling Sync Issues with MassIndexer
In edge cases, such as I/O failures after data is stored in database, the database and search index may go out of sync. One solution is to use MassIndexer, which reindexes all data.
In the example project, this process is automated via a scheduled job, ensuring that data remains in sync.
Searching with Hibernate Search
There are two main ways to fetch search results:
1. Fetching Data Directly from Elasticsearch (Used in DEMO)
This approach uses projections and skips the database, retrieving only indexed data. It requires adding the projectable = Projectable.YES property to the annotated fields.
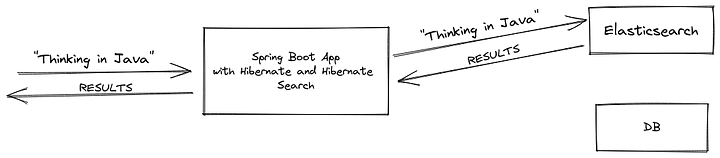
Pros:
- Faster search results.
- Reduces database load.
Cons:
- Data stored in Elasticsearch must be structured properly.
- More complex implementation (requires extra mappings and domain objects).
2. Fetching Indexes First, Then Retrieving Data from DB
In this method, only the entity IDs are retrieved from Elasticsearch, and the actual data is fetched from the database.
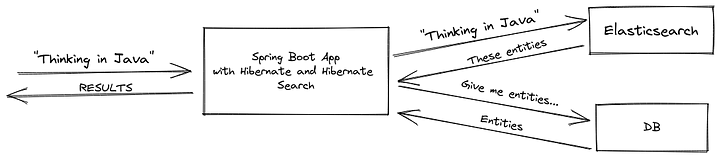
Pros:
- Ensures database integrity.
- Simpler to implement.
- Indexing only required fields, and letting the database handle the rest can result with performance improvement (Search engines are optimized for searching, not for updating)
Cons:
- Requires an additional database round-trip.
Thank you for reading!