


.webp?#)























































![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)
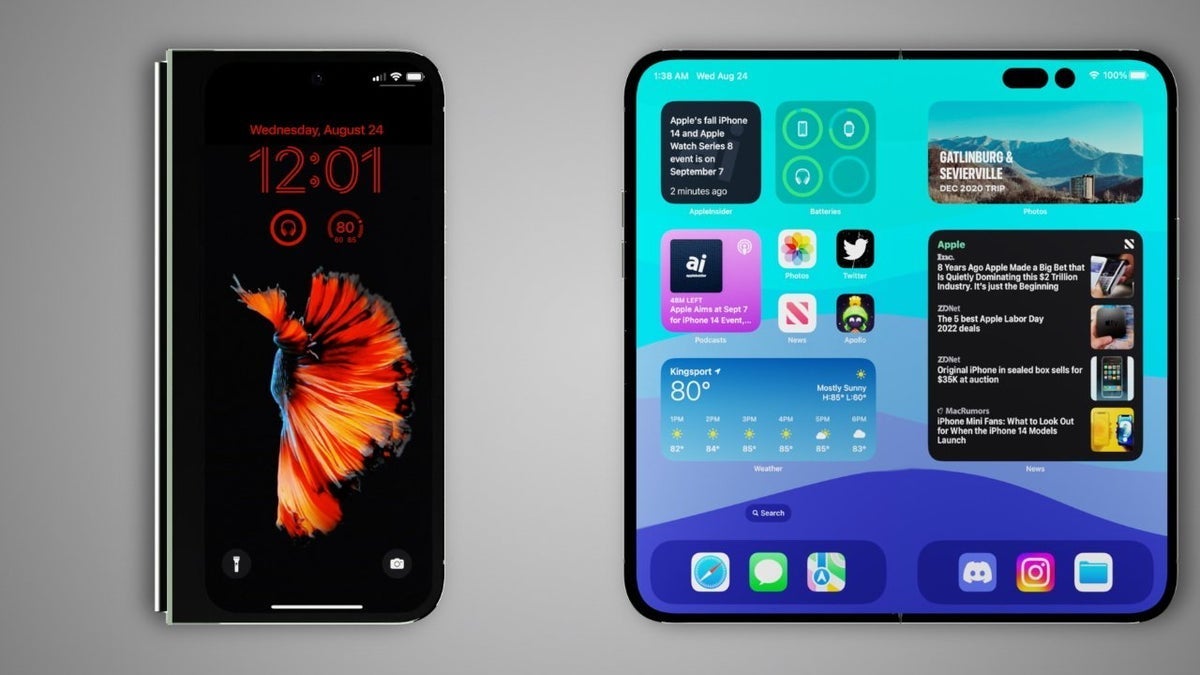
![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)


























































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
































































































































































































































Research Suggests Powerful AI Models Now Possible Without High-End Hardware
Large language models (LLMs) often require substantial computing resources that are usually met by high-performance hardware. These systems are built to handle vast amounts of data and execute the intricate calculations that power these models. For most people, the prospect of running advanced AI technology on their everyday devices seems unrealistic. However, a recent collaborative effort by researchers from MIT, the King Abdullah University of Science and Technology (KAUST), the Austrian Institute of Science and Technology (ISTA), and Yandex Research have introduced a new AI approach that can rapidly compress LLMs without a significant loss of quality. This breakthrough has the potential to make these powerful systems accessible for use on consumer-grade devices, such as smartphones and laptops. Deploying LLMs is typically a resource-intensive and expensive process, often requiring high-performance graphics processing units (GPUs). These hardware requirements have created significant barriers for everyday users, individual developers, and even small organizations with limited budgets to experiment with advanced AI models. The need for such specialized equipment has not only driven up costs but also introduced delays to the process making it even more challenging for basic users. The delays primarily stem from the heavy computational requirements and prolonged quantization processes involved in deploying LLMS. Depending on the use case, and inference demands, even some of the leading open-source AI models, may also require extensive hardware. While quantizing LLMs can help reduce the memory and computational demands, the lack of theoretical grounding can lead to suboptimal results. The new HIGGS ((Hadamard Incoherence with Gaussian MSE-optimal GridS) method (unrelated to the Higgs particle), is developed by researchers to overcome some of the limitations in efficiently compressing LLMs. It introduces a novel approach by utilizing “Hadamard Rotations” to reorganize internal numerical weights into a bell-curve-like distribution, making them more suitable for compression. The method uses MSE-optimal grids to minimize errors during compression, while vector quantization allows compressing groups of values together. Dynamic programming further refines the process by identifying the best compression settings for each layer. HIGGS has been made available on Hugging Face and GitHub. Technical details of the model have been shared by a paper published on arXiv. A key feature of the HIGGS model is its “data-free” capabilities. The researchers claim that the HIGGS works without needing any calibration datasets, making it more versatile and practical for everyday devices. HIGGS is based on the “linearity theorem” which explains how changes in different parts of an AI model affect its overall performance. This allows researchers to focus compression on less critical areas while protecting the key parts that impact functionality. According to the researchers, HIGGS goes beyond simply compressing the LLMs. They claim that specialized software kernels, developed for the HIGGS method, optimize the performance of compressed models. These kernels, built on the FLUTE system, enable the HIGGS compressed model to run two to three times faster than their uncompressed versions. HIGGS was tested on the Qwen-family models and the Llama 3.1 and 3.2-family models. The paper states that HIGGS achieved superior accuracy and compression performance with these models. It outperformed other quantization methods in key benchmarks. The researchers noted that dynamic HIGGS “can even outperform calibration-based methods such as GPTQ (GPT Quantization) and AWQ (Activation-Aware Quantization) in the 3–4 bit-width range.” This, they argue, underscores the potential for data-free techniques to achieve state-of-the-art performance without relying on calibration datasets. With its data-free, low-bit quantization and strong theoretical foundation, HIGGS promises reduced infrastructure needs. While the method still requires more testing, especially on different models, it does set the stage for making AI tools more accessible. The HIGGS paper is set to be showcased at NAACL (The North American Chapter of the Association for Computational Linguistics), one of the leading global conferences on artificial intelligence. The event will take place in Albuquerque, NM, from April 29 to May 4, 2025.

Large language models (LLMs) often require substantial computing resources that are usually met by high-performance hardware. These systems are built to handle vast amounts of data and execute the intricate calculations that power these models.
For most people, the prospect of running advanced AI technology on their everyday devices seems unrealistic. However, a recent collaborative effort by researchers from MIT, the King Abdullah University of Science and Technology (KAUST), the Austrian Institute of Science and Technology (ISTA), and Yandex Research have introduced a new AI approach that can rapidly compress LLMs without a significant loss of quality. This breakthrough has the potential to make these powerful systems accessible for use on consumer-grade devices, such as smartphones and laptops.
Deploying LLMs is typically a resource-intensive and expensive process, often requiring high-performance graphics processing units (GPUs). These hardware requirements have created significant barriers for everyday users, individual developers, and even small organizations with limited budgets to experiment with advanced AI models.

Shutterstock
The need for such specialized equipment has not only driven up costs but also introduced delays to the process making it even more challenging for basic users. The delays primarily stem from the heavy computational requirements and prolonged quantization processes involved in deploying LLMS.
Depending on the use case, and inference demands, even some of the leading open-source AI models, may also require extensive hardware. While quantizing LLMs can help reduce the memory and computational demands, the lack of theoretical grounding can lead to suboptimal results.
The new HIGGS ((Hadamard Incoherence with Gaussian MSE-optimal GridS) method (unrelated to the Higgs particle), is developed by researchers to overcome some of the limitations in efficiently compressing LLMs. It introduces a novel approach by utilizing “Hadamard Rotations” to reorganize internal numerical weights into a bell-curve-like distribution, making them more suitable for compression.
The method uses MSE-optimal grids to minimize errors during compression, while vector quantization allows compressing groups of values together. Dynamic programming further refines the process by identifying the best compression settings for each layer.
HIGGS has been made available on Hugging Face and GitHub. Technical details of the model have been shared by a paper published on arXiv.
A key feature of the HIGGS model is its “data-free” capabilities. The researchers claim that the HIGGS works without needing any calibration datasets, making it more versatile and practical for everyday devices.
HIGGS is based on the “linearity theorem” which explains how changes in different parts of an AI model affect its overall performance. This allows researchers to focus compression on less critical areas while protecting the key parts that impact functionality.
According to the researchers, HIGGS goes beyond simply compressing the LLMs. They claim that specialized software kernels, developed for the HIGGS method, optimize the performance of compressed models. These kernels, built on the FLUTE system, enable the HIGGS compressed model to run two to three times faster than their uncompressed versions.

Shutterstock
HIGGS was tested on the Qwen-family models and the Llama 3.1 and 3.2-family models. The paper states that HIGGS achieved superior accuracy and compression performance with these models. It outperformed other quantization methods in key benchmarks.
The researchers noted that dynamic HIGGS “can even outperform calibration-based methods such as GPTQ (GPT Quantization) and AWQ (Activation-Aware Quantization) in the 3–4 bit-width range.” This, they argue, underscores the potential for data-free techniques to achieve state-of-the-art performance without relying on calibration datasets.
With its data-free, low-bit quantization and strong theoretical foundation, HIGGS promises reduced infrastructure needs. While the method still requires more testing, especially on different models, it does set the stage for making AI tools more accessible.
The HIGGS paper is set to be showcased at NAACL (The North American Chapter of the Association for Computational Linguistics), one of the leading global conferences on artificial intelligence. The event will take place in Albuquerque, NM, from April 29 to May 4, 2025.







