































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)












![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































































OSD 700 - RAG Integration: Stage 3
Table of Contents Introduction Tensorflow.js Settings UI Conclusion Introduction After we have successfully landed the stage 1, 2 to the Chatcraft.org, it's time to work on the stage 3. Today, I am going to describe the embeddings' generation implementation process that I am currently working on. Firstly, we gotta stick to the proposed plan, you may find it here: RAG on DuckDB Implementation Based on Prototype #868 mulla028 posted on Mar 29, 2025 Description Recently, we have implemented a prototype of RAG on DuckDB, and it proves that implementation is doable for the ChatCraft it's time to start working on it! The implementation will take several steps, lets call them stages. Since we already have the set up of DuckDB using duckdb-wasm, the file loader, and format to text extractors, we are skipping some of the steps(stages). Therefore here are the steps we need to take in order successfully implement it: Proposed Implementation Stages Stage 1: Create Two New Tables in IndexedDB Embeddings Table, with foreign key to a file Chunks Table, with foreign key to a file Stage 2: Implement Chunking Logic Proper Chunking with overlap (cf. https://platform.openai.com/docs/assistants/tools/file-search#customizing-file-search-settings) Proper Chunking Storage in IndexedDB Stage 3: Implement Embeddings Generation Allow using a cloud-based model or local (transformers.js or tensorflow.js) Stage 4: Vector Search Use DuckDB's extension Called VSS Load Embeddings, Chunks, etc. into DuckDB Apply HNSW Indexing to Increase Speed of the Search ( HNSW Indexing Provided by VSS extension) Stage 5: LLM Integration Modify Prompt Construction to Include Retrieved Context Implement Source Attribution in Responses Adjust Token Management to Account For Context Stage 6: Query Processing Implement Embedding Generation for User Queries Use the Same Embedding Model as Documents for Consistency(text-embedding-3-small) @humphd, @tarasglek please take a look at the proposed implementation stages, and approve them. Let me know if I am missing something :) View on GitHub Stage 3 has just one point: "Allow using a cloud-based model or local (transformers.js or tensorflow.js)" First, I had to figure out what's tensorflow.js. Tensorflow.js TensorFlow is a software library for machine learning and artificial intelligence. Alright, it sounds cool, but how should I use it? I made a research and found out that tensorflow.js has a model called Universal Sentence Encoder that has embed method which generates the embeddings for the text passed as parameter. Here's the link of Universal Sentence Encoder's source code and the npm usage documentation. These resources helped me to implement it. The advantage of tensorflow.js over the openai model that I have also implemented is that we are running it offline, and it doesn't require the API key and the internet connection, which makes it extremely reliable for the chatcraft users. I would love to share the tensorflow.js implementation: import { EmbeddingsProvider } from "./EmbeddingProvider"; /** * TensorFlow.js-based embedding provider * Uses Universal Sentence Encoder for local embedding generation */ export class TensorflowEmbeddingsProvider implements EmbeddingsProvider { readonly id = "tensorflow-use"; readonly name = "TensorFlow Universal Sentence Encoder"; readonly description = "Local embedding model using TensorFlow.js (512 dimensions)"; readonly dimensions = 512; readonly maxBatchSize = 256; readonly defaultBatchSize = 128; readonly minBatchSize = 16; static readonly CONFIG = { dimensions: 512, maxBatchSize: 256, defaultBatchSize: 128, minBatchSize: 16, }; private model: any = null; private isLoading: boolean = false; private loadPromise: Promise | null = null; constructor() {} get CONFIG(): void { throw new Error("Method not implemented."); } /** * Load the model if it hasn't been loaded yet */ private async loadModelIfNeeded(): Promise { if (this.model) { return; } if (!this.loadPromise) { this.isLoading = true; this.loadPromise = (async () => { try { console.log("Loading Universal Sentence Encoder model..."); await import("@tensorflow/tfjs"); const use = await import("@tensorflow-models/universal-sentence-encoder"); this.model = await use.load(); console.log("Universal Sentence Encoder loaded successfully"); } catch (err) { console.error("Failed to load Universal Sentence Encoder:", err); this.loadPromise = null; throw err; } finally { this.isLoading = false; } })(); } return this.loadPromise; } /** * Generate an
Table of Contents
- Introduction
- Tensorflow.js
- Settings UI
- Conclusion
Introduction
After we have successfully landed the stage 1, 2 to the Chatcraft.org, it's time to work on the stage 3.
Today, I am going to describe the embeddings' generation implementation process that I am currently working on.
Firstly, we gotta stick to the proposed plan, you may find it here:
 RAG on DuckDB Implementation Based on Prototype
#868
RAG on DuckDB Implementation Based on Prototype
#868
Description
Recently, we have implemented a prototype of RAG on DuckDB, and it proves that implementation is doable for the ChatCraft it's time to start working on it!
The implementation will take several steps, lets call them stages. Since we already have the set up of DuckDB using duckdb-wasm, the file loader, and format to text extractors, we are skipping some of the steps(stages). Therefore here are the steps we need to take in order successfully implement it:
Proposed Implementation Stages
-
Stage 1: Create Two New Tables in IndexedDB
- Embeddings Table, with foreign key to a file
- Chunks Table, with foreign key to a file
-
Stage 2: Implement Chunking Logic
- Proper Chunking with overlap (cf. https://platform.openai.com/docs/assistants/tools/file-search#customizing-file-search-settings)
- Proper Chunking Storage in IndexedDB
-
Stage 3: Implement Embeddings Generation
- Allow using a cloud-based model or local (transformers.js or tensorflow.js)
-
Stage 4: Vector Search
- Use DuckDB's extension Called VSS
- Load Embeddings, Chunks, etc. into DuckDB
- Apply HNSW Indexing to Increase Speed of the Search (
HNSWIndexing Provided by VSS extension)
-
Stage 5: LLM Integration
- Modify Prompt Construction to Include Retrieved Context
- Implement Source Attribution in Responses
- Adjust Token Management to Account For Context
-
Stage 6: Query Processing
- Implement Embedding Generation for User Queries
- Use the Same Embedding Model as Documents for Consistency(
text-embedding-3-small)
@humphd, @tarasglek please take a look at the proposed implementation stages, and approve them. Let me know if I am missing something :)
Stage 3 has just one point: "Allow using a cloud-based model or local (transformers.js or tensorflow.js)"
First, I had to figure out what's tensorflow.js.
Tensorflow.js
TensorFlow is a software library for machine learning and artificial intelligence.
Alright, it sounds cool, but how should I use it? I made a research and found out that tensorflow.js has a model called Universal Sentence Encoder that has embed method which generates the embeddings for the text passed as parameter.
Here's the link of Universal Sentence Encoder's source code and the npm usage documentation. These resources helped me to implement it.
The advantage of tensorflow.js over the openai model that I have also implemented is that we are running it offline, and it doesn't require the API key and the internet connection, which makes it extremely reliable for the chatcraft users.
I would love to share the tensorflow.js implementation:
import { EmbeddingsProvider } from "./EmbeddingProvider";
/**
* TensorFlow.js-based embedding provider
* Uses Universal Sentence Encoder for local embedding generation
*/
export class TensorflowEmbeddingsProvider implements EmbeddingsProvider {
readonly id = "tensorflow-use";
readonly name = "TensorFlow Universal Sentence Encoder";
readonly description = "Local embedding model using TensorFlow.js (512 dimensions)";
readonly dimensions = 512;
readonly maxBatchSize = 256;
readonly defaultBatchSize = 128;
readonly minBatchSize = 16;
static readonly CONFIG = {
dimensions: 512,
maxBatchSize: 256,
defaultBatchSize: 128,
minBatchSize: 16,
};
private model: any = null;
private isLoading: boolean = false;
private loadPromise: Promise<void> | null = null;
constructor() {}
get CONFIG(): void {
throw new Error("Method not implemented.");
}
/**
* Load the model if it hasn't been loaded yet
*/
private async loadModelIfNeeded(): Promise<void> {
if (this.model) {
return;
}
if (!this.loadPromise) {
this.isLoading = true;
this.loadPromise = (async () => {
try {
console.log("Loading Universal Sentence Encoder model...");
await import("@tensorflow/tfjs");
const use = await import("@tensorflow-models/universal-sentence-encoder");
this.model = await use.load();
console.log("Universal Sentence Encoder loaded successfully");
} catch (err) {
console.error("Failed to load Universal Sentence Encoder:", err);
this.loadPromise = null;
throw err;
} finally {
this.isLoading = false;
}
})();
}
return this.loadPromise;
}
/**
* Generate an embedding vector for a single text
*/
async generateEmbeddings(text: string): Promise<number[]> {
const result = await this.generateBatchEmbeddings([text]);
return result[0];
}
/**
* Generate embedding vectors for multiple texts in batch
*/
async generateBatchEmbeddings(texts: string[]): Promise<number[][]> {
let embeddings;
try {
await this.loadModelIfNeeded();
embeddings = await this.model.embed(texts);
const arrays = await embeddings.array();
return arrays;
} catch (error: any) {
console.error("Error generating TensorFlow embeddings:", error);
throw new Error(`TensorFlow embedding error: ${error.message || "Unknown error"}`);
} finally {
if (embeddings) {
embeddings.dispose();
}
}
}
}
Here's the open PR:
[RAG] Stage - 3: Embeddings Generation
#873
Description
This is stage 3 of #868. We are adding the capability of generation and storage vector embeddings for document chunks. It introduces modular embedding provider archtecture, and supports:
- OpenAI's text-embedding-3-small API
- Local tensorflow.js alternative
ChatCraftFile has been extended with methods to:
- generate embeddings
- store embeddings
- manage embeddings
Integrated embedding generation with the use-file-import to automatically create embeddings after chunking.
New settings added to control:
- the embedding provider
- batch size
- automatic generation preference
[!IMPORTANT] UI for the embedding preferences required! Therefore, we must land this PR with the updated Settings UI...
Test It
[!TIP] You may want to test it. In order to do so follow the steps below!
- Open
CloudFlaredeployment below - Upload File >=300KB
- Go to DevTools
-
Application→Storage→IndexedDB→ChatCraftDatabase→files - Wuolah! You can see the generated embeddings! (I HOPE :D)
Screenshot

Question
Maybe we could reduce the size of the minimum chunking size from 300KB → 100 KB. Therefore, the minimum character per chunk is from 1000 → 300.
Settings UI
Since this is an experimental feature that might be unstable or break, we need to make sure that regular users aren't distracted and by default it is turned off. Therefore, we need a switch that turns on the feature without adjusting the code every time. Here's the result:
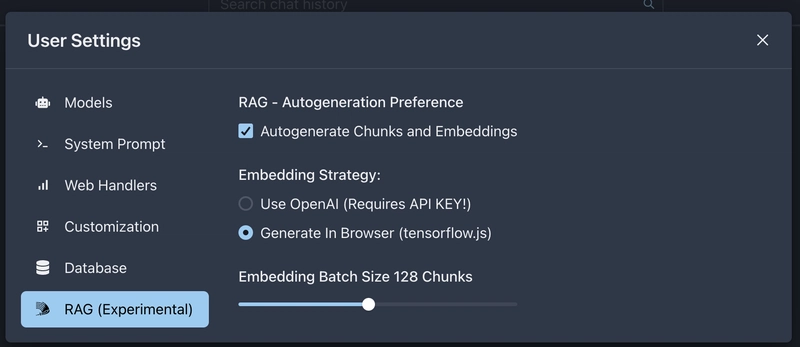
Conclusion
This PR is still in progress, but embeddings generation works well. Since it is the last week of the term, everyone busy and don't have time to review my code, which is understandable. This is the end of the semester, but I will continue working on the RAG feature and running this blog, I really enjoy doing it!







