












![[Видео] Новости мира Python за март 2025](https://i.ytimg.com/vi/jcPM1sr9JDg/hqdefault.jpg?v=67e98d2d)









































































































![Революция и одиночество в Аду. Обзор кооперативного «рогалика» 33 Immortals [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/25/nova-filepond-Av0xGB.png)

![Для самых преданных фанатов. Обзор гоночной игры Wreckfest 2 [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/25/nova-filepond-CLkvqB.jpg)



































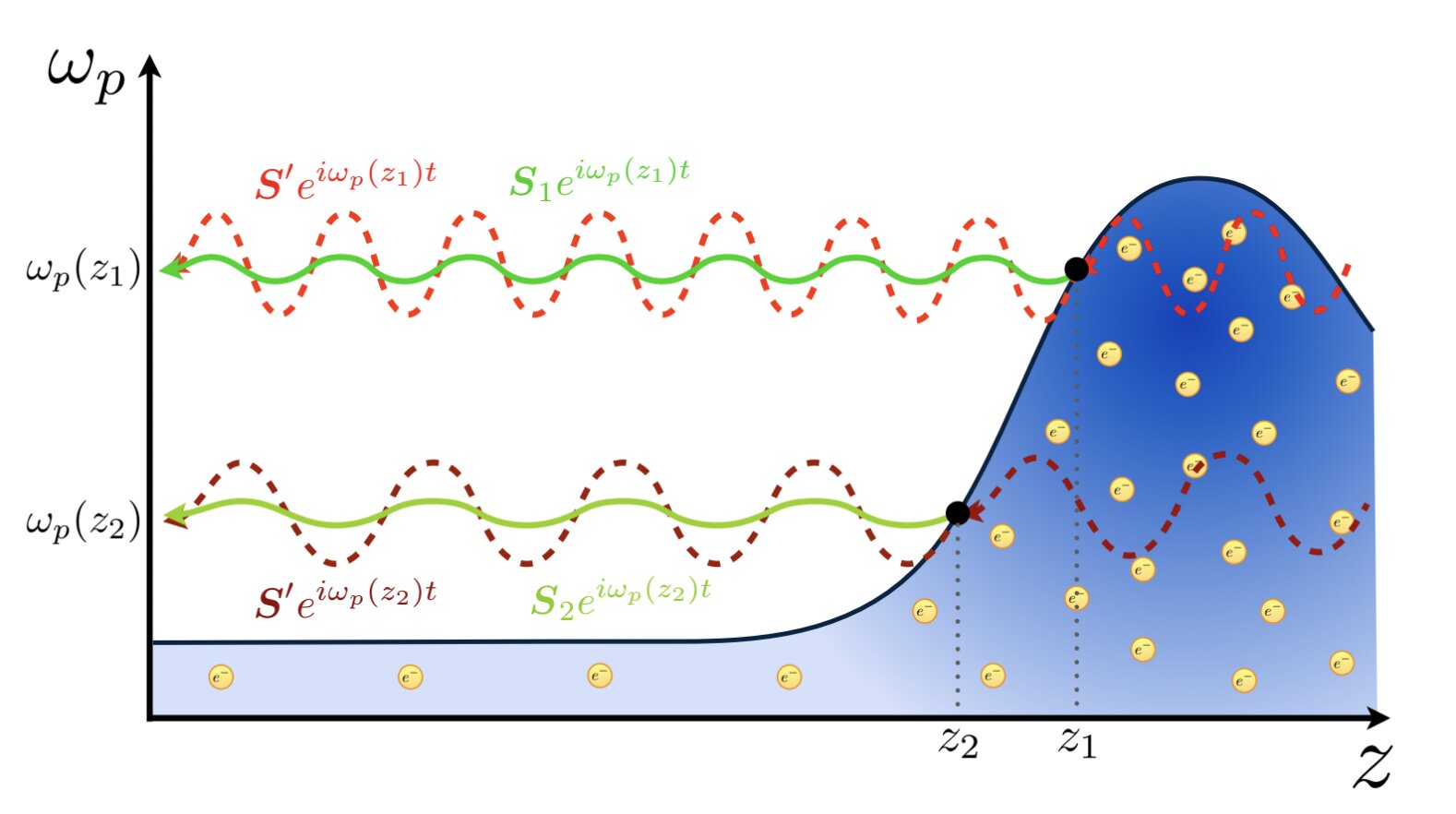






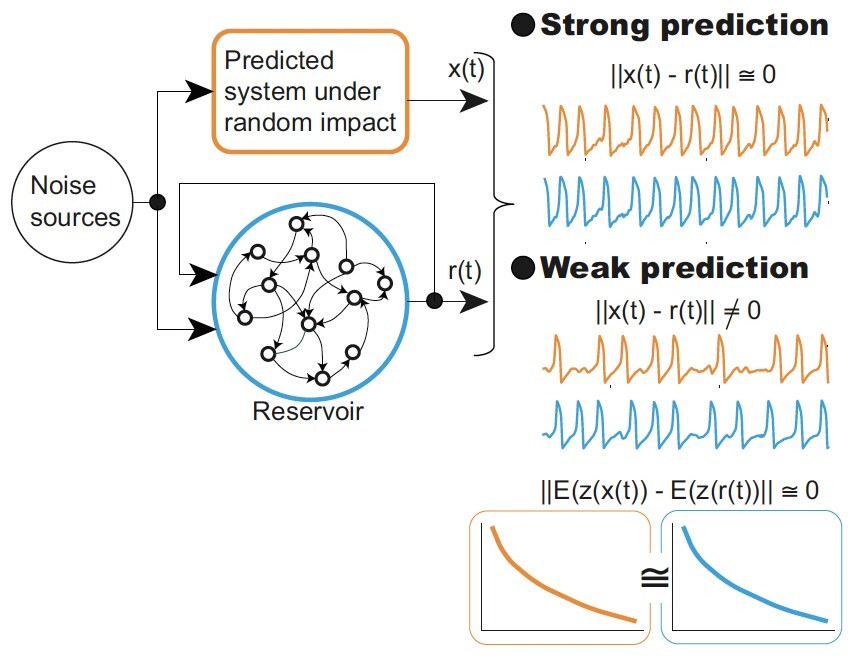

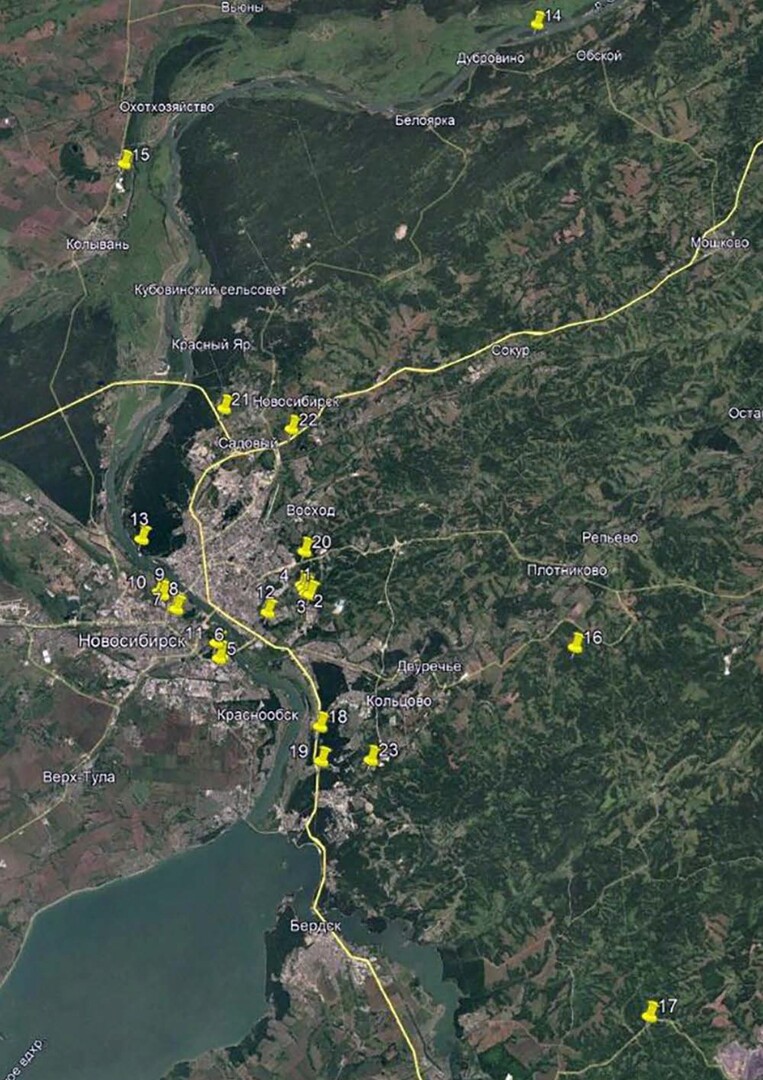
Генеративные нейросети: с какими правовыми рисками сталкиваются их разработчики
Ведущие IT-компании создают собственные языковые модели и системы ИИ: у «Яндекса» есть YandexGPT 5, «Сбер» представил GigaChat 2.0 и ИИ Kandinsky 3.1 для генерации изображений и видео. Также над LLM работают Т-Банк и МТС. Вместе с экспертом разбираемся, как снизить правовые риски при разработке ИИ. Для развития и обучения нейросетей необходимы большие объемы данных, которые загружаются в систему. Они различаются в зависимости от типа и функционала нейросети: для обучения модели генерации музыки потребуются терабайты соответствующей информации. Если же мы хотим научить ИИ рисовать дерево, то сначала потребуется загрузить в систему множество изображений деревьев, которые будет считывать система распознавания образов. Она сможет указать на схожие паттерны на разных картинках. На их основе нейросеть начнет «рисовать» собственные изображения дерева. Аналогичные принципы используются для генерации рекламных изображений или видео. Когда нам необходимо обучить нейросеть писать картины или музыку либо генерировать иные объекты авторских прав, сразу возникает множество правовых вопросов, на которые в силу отсутствия регулирования разные интересанты смотрят по-своему. Тем, кто обучает генеративные нейросети, загрузка картинок, музыки или текста из сети в базу данных кажется чем-то естественным. И мало кто задумывается, охватывает ли понятие «использование объекта авторского права» такое действие, как загрузка картинки в базу нейросети, ее обучение и последующая генерация нового изображения.

Ведущие IT-компании создают собственные языковые модели и системы ИИ: у «Яндекса» есть YandexGPT 5, «Сбер» представил GigaChat 2.0 и ИИ Kandinsky 3.1 для генерации изображений и видео. Также над LLM работают Т-Банк и МТС. Вместе с экспертом разбираемся, как снизить правовые риски при разработке ИИ.
Для развития и обучения нейросетей необходимы большие объемы данных, которые загружаются в систему. Они различаются в зависимости от типа и функционала нейросети: для обучения модели генерации музыки потребуются терабайты соответствующей информации. Если же мы хотим научить ИИ рисовать дерево, то сначала потребуется загрузить в систему множество изображений деревьев, которые будет считывать система распознавания образов. Она сможет указать на схожие паттерны на разных картинках. На их основе нейросеть начнет «рисовать» собственные изображения дерева. Аналогичные принципы используются для генерации рекламных изображений или видео.
Когда нам необходимо обучить нейросеть писать картины или музыку либо генерировать иные объекты авторских прав, сразу возникает множество правовых вопросов, на которые в силу отсутствия регулирования разные интересанты смотрят по-своему. Тем, кто обучает генеративные нейросети, загрузка картинок, музыки или текста из сети в базу данных кажется чем-то естественным. И мало кто задумывается, охватывает ли понятие «использование объекта авторского права» такое действие, как загрузка картинки в базу нейросети, ее обучение и последующая генерация нового изображения.



