


































































![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)













![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)
















































































































An Introduction to Retrieval-Augmented Generation
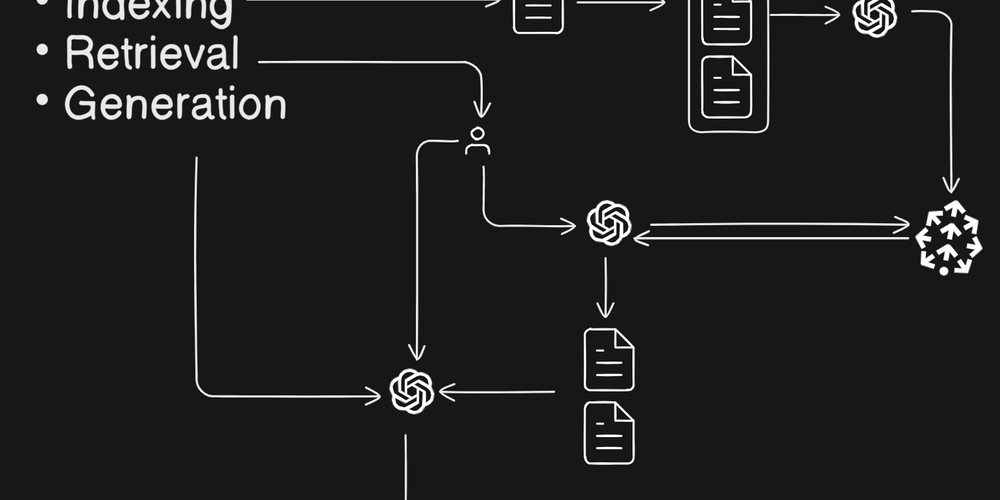
Chapter1 - Introduction to Retrieval-Augmented Generation (RAG) Overview Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of Large Language Models (LLMs) by retrieving relevant information from external data sources and feeding this information as context into the language model to generate more accurate, informative, and contextually relevant responses. In this post, we'll break down the basic components of RAG, how it works, and give you a visual understanding of the process. Table of Contents What is RAG? How does RAG work? Summary Table Flow Chart for Visual Understanding Conclusion What is RAG? RAG is an AI framework that optimizes LLMs by integrating external data to enhance response accuracy and informativeness. When combined with a retrieval mechanism, the model can answer user queries with more depth and relevance by pulling context from a vast set of external data sources. How does RAG work? 1. Indexing: This process prepares external data for retrieval. Key steps include: Data Collection: Gathering the necessary data for your application. Data Chunking: Breaking large datasets into smaller, manageable chunks. Document Embedding: Converting text chunks into vectors that capture semantic meaning. Vector Storing: Storing these vectors in a vector database (like Pinecone, Qdrant, or Weaviate) for efficient searching. 2. Retrieval: Query Embedding: Converting the user’s query into a vector using the same model as the document embeddings. Similarity Search: Comparing the query vector with stored document vectors to retrieve the most relevant chunks. Top-k Retrieval: Identifying and returning the top matching chunks from the vector database. 3. Generation: Once relevant chunks are retrieved, they are fed into the LLM along with the user's query to generate the final response. Input to LLM: The context (user query + retrieved text chunks) is provided to the LLM. Contextual Understanding: The LLM processes the provided information and understands the user’s intent. Response Generation: The LLM synthesizes a coherent and informative response. Summary Table Stage What Happens Indexing Collect → Chunk → Embed → Store in vector DB Retrieval Embed query → Search vector DB → Return top-matching chunks Generation Combine query + retrieved context → Feed into LLM → Generate final response Flow Chart for Visual Understanding Here you can add a visual flow chart explaining the process of RAG. Conclusion In this post, we’ve covered the fundamentals of Retrieval-Augmented Generation (RAG). The process includes: Indexing: Preparing the data. Retrieval: Fetching relevant chunks based on the user query. Generation: Combining the retrieved data with the user’s query for a coherent response. In future posts, we’ll dive deeper into advanced RAG concepts, such as step-back prompting, RRF (Relevance Feedback), parallel query retrieval, CoT (Chain of Thought), and HyDE (Hybrid Dense Encoding). Stay tuned for more informative blogs!
Chapter1 - Introduction to Retrieval-Augmented Generation (RAG)
Overview
Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of Large Language Models (LLMs) by retrieving relevant information from external data sources and feeding this information as context into the language model to generate more accurate, informative, and contextually relevant responses.
In this post, we'll break down the basic components of RAG, how it works, and give you a visual understanding of the process.
Table of Contents
- What is RAG?
- How does RAG work?
- Summary Table
- Flow Chart for Visual Understanding
- Conclusion
What is RAG?
RAG is an AI framework that optimizes LLMs by integrating external data to enhance response accuracy and informativeness. When combined with a retrieval mechanism, the model can answer user queries with more depth and relevance by pulling context from a vast set of external data sources.
How does RAG work?
1. Indexing:
This process prepares external data for retrieval. Key steps include:
- Data Collection: Gathering the necessary data for your application.
- Data Chunking: Breaking large datasets into smaller, manageable chunks.
- Document Embedding: Converting text chunks into vectors that capture semantic meaning.
- Vector Storing: Storing these vectors in a vector database (like Pinecone, Qdrant, or Weaviate) for efficient searching.
2. Retrieval:
- Query Embedding: Converting the user’s query into a vector using the same model as the document embeddings.
- Similarity Search: Comparing the query vector with stored document vectors to retrieve the most relevant chunks.
- Top-k Retrieval: Identifying and returning the top matching chunks from the vector database.
3. Generation:
Once relevant chunks are retrieved, they are fed into the LLM along with the user's query to generate the final response.
- Input to LLM: The context (user query + retrieved text chunks) is provided to the LLM.
- Contextual Understanding: The LLM processes the provided information and understands the user’s intent.
- Response Generation: The LLM synthesizes a coherent and informative response.
Summary Table
| Stage | What Happens |
|---|---|
| Indexing | Collect → Chunk → Embed → Store in vector DB |
| Retrieval | Embed query → Search vector DB → Return top-matching chunks |
| Generation | Combine query + retrieved context → Feed into LLM → Generate final response |
Flow Chart for Visual Understanding
Here you can add a visual flow chart explaining the process of RAG.
Conclusion
In this post, we’ve covered the fundamentals of Retrieval-Augmented Generation (RAG). The process includes:
- Indexing: Preparing the data.
- Retrieval: Fetching relevant chunks based on the user query.
- Generation: Combining the retrieved data with the user’s query for a coherent response.
In future posts, we’ll dive deeper into advanced RAG concepts, such as step-back prompting, RRF (Relevance Feedback), parallel query retrieval, CoT (Chain of Thought), and HyDE (Hybrid Dense Encoding).
Stay tuned for more informative blogs!







