![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)













![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)
















































































































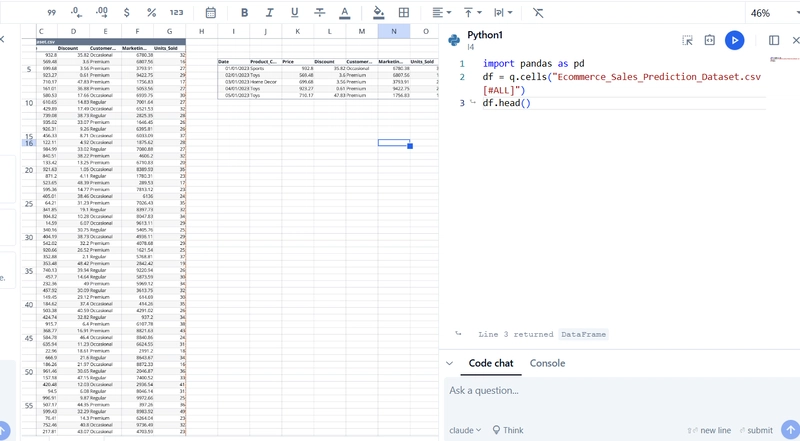
Supercharging My VS Code AI Agent with Local RAG
My AI Agent Needed a Better Memory Working with AI assistants directly in my IDE (like Cline or Roo Code in VS Code) has become a core part of my workflow, especially for personal reflection and journaling – what I call "Project Life". The agent is great at capturing my thoughts in the moment, saving them neatly into dated Markdown files. But a crucial piece was missing: efficient access to the past. When I asked my AI agent, "What did I write about managing anxiety last month?", it faced a dilemma: Manual File Reading? It could try to list and read relevant files, but that's slow, clunky, and requires complex instructions. Massive Context Window? We could try stuffing weeks or months of journal entries into the prompt, but LLM context windows have limits, costs escalate quickly, and performance degrades. Sending the entire history frequently is inefficient and costly. Lost Context: Long-running conversations eventually lose track of earlier details. I needed a way for my agent to instantly retrieve relevant historical context without these drawbacks. I wanted it to feel like it had a memory of my past entries, specifically tailored to my current query. The Solution: Local RAG Accessed via MCP The answer lay in combining two powerful concepts: Retrieval-Augmented Generation (RAG): Instead of relying solely on the prompt, RAG retrieves relevant information from an external knowledge base (my journal files!) and adds it to the prompt before sending it to the LLM. Model Context Protocol (MCP): A standardized way for my VS Code AI agent to communicate with other local tools and services. The plan: Build a local RAG service that indexes my Markdown journal files and expose its querying capability as a tool via an MCP server. My VS Code agent could then call this tool whenever I asked about past entries. The Workflow: Giving My Agent Instant Recall Here’s how it works in practice: Journaling: I talk to my AI agent in VS Code. It captures my thoughts and saves them to journal/YYYY/MM/DD.md. Indexing: A local RAG service (journal-rag-mcp) monitors the journal directory (or runs on demand) and updates its index. It reads Markdown files, splits them into chunks, generates vector embeddings using sentence-transformers, and stores them in a local ChromaDB vector database. Querying the Past: I ask the agent, "What were my main concerns during the project planning phase?" Agent Uses Tool: The agent recognizes this requires historical context. Instead of reading files or using a huge prompt, it makes a single, targeted call to the journal-rag-mcp server using the query_journal tool via MCP, sending my query ("project planning phase concerns"). RAG Server Works: The MCP server receives the request, embeds the query, searches its ChromaDB index for the most semantically similar text chunks from my past entries, and gathers the top few results. Context Returned: The MCP server sends only these relevant text snippets back to the AI agent as the tool's result. Informed Response: The agent now has the specific, relevant context needed. It combines my original question and these retrieved snippets into a concise prompt for the LLM (e.g., Gemini). The LLM generates a response grounded in my actual past writings. The key benefit: The agent gets the historical context it needs in one efficient request, without manual file handling or bloated prompts. Building the RAG MCP Service The core components are: Markdown Files: The source of truth. Python: The language for the server. sentence-transformers: For creating text embeddings locally (using all-MiniLM-L6-v2 and GPU acceleration via PyTorch/CUDA). ChromaDB: A local vector database for storing and querying embeddings. python-frontmatter: To parse metadata if needed (though the focus here is the text content). MCP Server Script (journal_rag_mcp.py): A Python script that: Initializes the embedding model and ChromaDB connection. Listens for incoming MCP requests via standard input/output (stdio). Defines tools like query_journal and update_index. Handles query_journal requests by embedding the query, searching ChromaDB, and returning results. Handles update_index requests to keep the vector store fresh. Here's a conceptual look at the MCP tool definition: # Conceptual MCP tool definition within the server script QUERY_TOOL_SCHEMA = { "name": "query_journal", "description": "Queries personal journal entries using semantic search.", "inputSchema": { "type": "object", "properties": { "query": {"type": "string", "description": "The search query text."} }, "required": ["query"] } } # Server logic maps requests matching this schema to the RAG query function. The build involved setting up the Python environment (.venv), installing dependencies, and configuring the MCP server in VS Code's settings. Debugging involved fixi

My AI Agent Needed a Better Memory
Working with AI assistants directly in my IDE (like Cline or Roo Code in VS Code) has become a core part of my workflow, especially for personal reflection and journaling – what I call "Project Life". The agent is great at capturing my thoughts in the moment, saving them neatly into dated Markdown files. But a crucial piece was missing: efficient access to the past.
When I asked my AI agent, "What did I write about managing anxiety last month?", it faced a dilemma:
- Manual File Reading? It could try to list and read relevant files, but that's slow, clunky, and requires complex instructions.
- Massive Context Window? We could try stuffing weeks or months of journal entries into the prompt, but LLM context windows have limits, costs escalate quickly, and performance degrades. Sending the entire history frequently is inefficient and costly.
- Lost Context: Long-running conversations eventually lose track of earlier details.
I needed a way for my agent to instantly retrieve relevant historical context without these drawbacks. I wanted it to feel like it had a memory of my past entries, specifically tailored to my current query.
The Solution: Local RAG Accessed via MCP
The answer lay in combining two powerful concepts:
- Retrieval-Augmented Generation (RAG): Instead of relying solely on the prompt, RAG retrieves relevant information from an external knowledge base (my journal files!) and adds it to the prompt before sending it to the LLM.
- Model Context Protocol (MCP): A standardized way for my VS Code AI agent to communicate with other local tools and services.
The plan: Build a local RAG service that indexes my Markdown journal files and expose its querying capability as a tool via an MCP server. My VS Code agent could then call this tool whenever I asked about past entries.
The Workflow: Giving My Agent Instant Recall
Here’s how it works in practice:
- Journaling: I talk to my AI agent in VS Code. It captures my thoughts and saves them to
journal/YYYY/MM/DD.md. - Indexing: A local RAG service (
journal-rag-mcp) monitors the journal directory (or runs on demand) and updates its index. It reads Markdown files, splits them into chunks, generates vector embeddings usingsentence-transformers, and stores them in a localChromaDBvector database. - Querying the Past: I ask the agent, "What were my main concerns during the project planning phase?"
- Agent Uses Tool: The agent recognizes this requires historical context. Instead of reading files or using a huge prompt, it makes a single, targeted call to the
journal-rag-mcpserver using thequery_journaltool via MCP, sending my query ("project planning phase concerns"). - RAG Server Works: The MCP server receives the request, embeds the query, searches its ChromaDB index for the most semantically similar text chunks from my past entries, and gathers the top few results.
- Context Returned: The MCP server sends only these relevant text snippets back to the AI agent as the tool's result.
- Informed Response: The agent now has the specific, relevant context needed. It combines my original question and these retrieved snippets into a concise prompt for the LLM (e.g., Gemini). The LLM generates a response grounded in my actual past writings.
The key benefit: The agent gets the historical context it needs in one efficient request, without manual file handling or bloated prompts.
Building the RAG MCP Service
The core components are:
- Markdown Files: The source of truth.
- Python: The language for the server.
-
sentence-transformers: For creating text embeddings locally (usingall-MiniLM-L6-v2and GPU acceleration via PyTorch/CUDA). -
ChromaDB: A local vector database for storing and querying embeddings. -
python-frontmatter: To parse metadata if needed (though the focus here is the text content). - MCP Server Script (
journal_rag_mcp.py): A Python script that:- Initializes the embedding model and ChromaDB connection.
- Listens for incoming MCP requests via standard input/output (stdio).
- Defines tools like
query_journalandupdate_index. - Handles
query_journalrequests by embedding the query, searching ChromaDB, and returning results. - Handles
update_indexrequests to keep the vector store fresh.
Here's a conceptual look at the MCP tool definition:
# Conceptual MCP tool definition within the server script
QUERY_TOOL_SCHEMA = {
"name": "query_journal",
"description": "Queries personal journal entries using semantic search.",
"inputSchema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "The search query text."}
},
"required": ["query"]
}
}
# Server logic maps requests matching this schema to the RAG query function.
The build involved setting up the Python environment (.venv), installing dependencies, and configuring the MCP server in VS Code's settings. Debugging involved fixing dependency issues (frontmatter), path misconfigurations, Python NameErrors (false vs False), and ensuring the index update mechanism worked correctly.
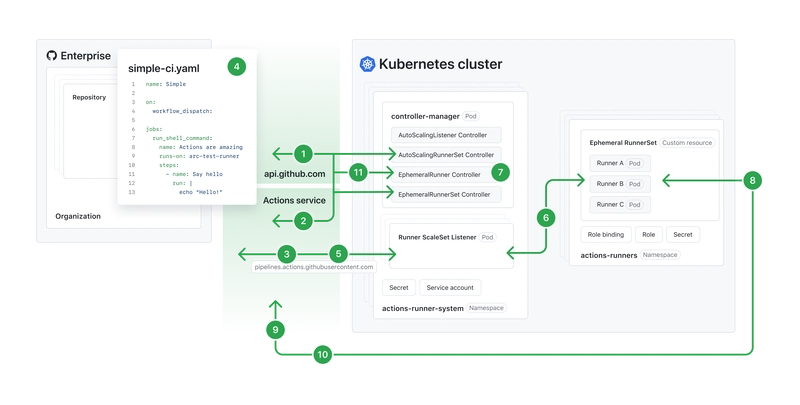
Architecture: Agent -> MCP -> RAG
This diagram shows the primary data flows:
+-----------------+ +-----------------+
| Journal Files | <--(Save Data)---- | VS Code AI Agent| -- User Interaction --> (LLM)
| (.md) | | (e.g.,Cline/Roo)|
+-------+---------+ +-------+---------+
| | Tool Call (query_journal)
| Indexing v
v +-----------------+
+-----------------+ | journal-rag-mcp |
| Vector Store | <-- Search Query --- | (MCP Server) |
| (ChromaDB) | +-----------------+
+-----------------+ --- Results -------> (Agent uses Results)
(Chunks)
(Note: Indexing reads Journal Files to update the Vector Store, typically as a background or on-demand process)
Current Status & Future
The journal-rag-mcp server is running reliably. My VS Code AI agent can now use the query_journal tool to instantly retrieve relevant context from my past entries. This significantly enhances its usefulness as a reflective journaling partner.
Future plans include:
- Building the Metrics Parser and Dashboard to visualize data from YAML front matter.
- Creating a dedicated AI Chat Interface outside of the IDE.
- Refining the RAG process (e.g., experimenting with different models or chunking strategies).
Conclusion: Efficient, Relevant AI Memory
Combining a capable AI agent with specialized local tools like this RAG server via MCP is incredibly powerful. It provides an efficient, relevant, and scalable way to give AI assistants access to personal knowledge bases, sending only pertinent snippets to the LLM instead of the entire history.
Is this the perfect solution? Honestly, no. In an ideal world, the AI would always have the full conversation history instantly available. But current technology has limitations. My earlier experiments involved conversations with staggering context lengths – think over 400 million input tokens and 800k context windows using experimental models. While powerful, the latency became unbearable (often over 30 seconds per response), and the cost implications were significant. RAG offers a pragmatic compromise today.
While the retrieved snippets are sent to the external LLM API for generation, the core index remains private and local, and the overall process is far more targeted and cost-effective than relying solely on massive context windows.
What truly excites me is how accessible building such tools has become. Creating an MCP server, especially with frameworks or assistance from IDE agents like Roo/Cline, is surprisingly straightforward. Debugging Python code with an LLM partner turns potential roadblocks into learning opportunities. Given this landscape, there's immense potential for developers to build personalized software that genuinely improves their lives.
For anyone building personal AI tools or struggling with context window limitations, I highly recommend exploring local RAG and protocols like MCP. It puts you in control of the retrieval process and unlocks new possibilities for how AI can interact with your data efficiently.