




































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)









![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)























































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

































































































































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

CRUST-Bench: New Benchmark for Safe C-to-Rust Transpilation with Realistic Code & Tests
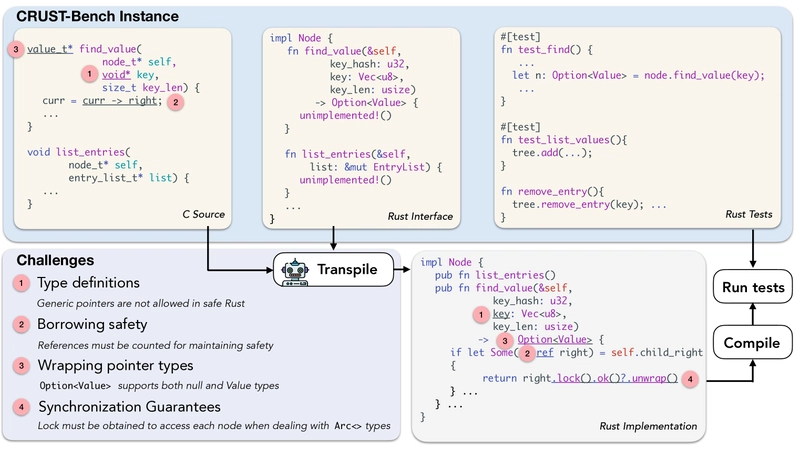
This is a Plain English Papers summary of a research paper called CRUST-Bench: New Benchmark for Safe C-to-Rust Transpilation with Realistic Code & Tests. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Need for Safe C-to-Rust Code Translation Benchmarks C-to-Rust transpilation is essential for modernizing legacy code while enhancing safety and interoperability with modern Rust ecosystems. Many critical infrastructure systems are written in C, creating an urgent need for reliable automated techniques that support not only C-to-Rust translation but, more importantly, C-to-safe-Rust migration. While Rust supports unsafe code for low-level operations, the core value of migration lies in producing code that executes within Rust's safe subset, allowing users to benefit from Rust's strong memory safety guarantees. Despite rapid progress in large language models (LLMs) for code generation, fully automated C-to-safe-Rust transpilation remains challenging. Existing machine learning benchmarks largely focus on competitive programming problems rather than realistic, multi-file systems programming. Other efforts like SWE-bench target bug-fixing scenarios with localized edits, not whole-program translation or structural refactoring. To address these limitations, the researchers introduce CRUST-Bench, a benchmark for evaluating automated C-to-Rust transpilation in realistic settings. CRUST-Bench comprises 100 C repositories, each paired with manually crafted Rust interfaces and test cases to assess the correctness and quality of transpilation. The Rust interfaces serve as formal specifications, defining function signatures, type annotations, and ownership constraints to guide the translation process. These interfaces enforce idiomatic and memory-safe Rust patterns, ensuring transpiled code adheres to Rust's safety guarantees. The accompanying test cases provide validation, verifying that the generated Rust code correctly implements the specified behavior. Figure 1: Example of a CRUST-Bench task showing the challenge of translating pointer-based C code to safe, idiomatic Rust. Why Current C-to-Rust Transpilation Benchmarks Fall Short A number of benchmarks have been proposed to evaluate source code translation and transformation tasks, including transpilation, automated debugging, and safe code generation. While these benchmarks provide valuable insights, those that focus specifically on C-to-Rust transpilation tend to exhibit important gaps—particularly limited task scope, lack of robust correctness validation, and insufficient evaluation of memory safety. Many are restricted to small, synthetic examples or overlook whether the generated Rust code adheres to safe and idiomatic practices. Benchmark # Projects Multi-file? Avg LoC Rust Interface? Rust Tests? CROWN 20 ✓ 31.7K ✗ ✗ TransCoder-Rust 520 ✗ 108 ✗ ✗ FLOURINE 112 ✗ 68 ✗ ✗ C2SaferRust 7 ✓ 9.3K ✗ ✗ SYZYGY 1 ✓ 2.5K ✗ ✗ LAERTES 17 ✓ 24K ✗ ✗ CRUST-Bench (Ours) 100 ✓ 958 ✓ ✓ Table 1: Comparison of C-to-Rust transpilation benchmarks. Compared to prior benchmarks, CRUST-Bench includes a substantial number of real-world projects while keeping them within reach for LLM-guided transpilation techniques. A key feature of CRUST-Bench is that it provides safe Rust interfaces and corresponding test files. This is important because existing transpilation tools, such as c2rust, often produce naive translations that rely heavily on unsafe constructs, sidestepping Rust's safety guarantees rather than properly adapting C code. LLM-based approaches also risk generating inconsistent interfaces across files, making it difficult to produce a coherent, working Rust codebase. Inside the CRUST-Bench Framework: Structure and Validation Each instance in CRUST-Bench is built on a C repository, formalized as a collection of source files. The goal of transpilation is to produce a corresponding Rust repository with a parallel file structure, ensuring that each Rust file is a direct translation of the corresponding C file. Validation of the transpiled Rust code is based on three criteria: It must conform to a well-defined interface that specifies a set of abstract datatypes and functions The transpiled Rust code must compile without errors A set of tests must pass, confirming functional correctness C Code Properties Avg Max Test cases 76.4 952 Test files 3.0 19 Test coverage 67% 100% Lines of code 958 25,436 Pointer dereferences 264 12,664 Functions 34.6 418 Table 2: Properties of C code in the CRUST-Bench dataset. The projects in the benchmark were sourced from open-source repositories on GitHub, covering a diverse range of software categories created between 2005 and 2025. The selection includes programming language infrastructure (e.g., compilers), algorithmic libraries (e.g., solvers), system utilities (e.g., shell implementations), and others. To construct C
This is a Plain English Papers summary of a research paper called CRUST-Bench: New Benchmark for Safe C-to-Rust Transpilation with Realistic Code & Tests. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Need for Safe C-to-Rust Code Translation Benchmarks
C-to-Rust transpilation is essential for modernizing legacy code while enhancing safety and interoperability with modern Rust ecosystems. Many critical infrastructure systems are written in C, creating an urgent need for reliable automated techniques that support not only C-to-Rust translation but, more importantly, C-to-safe-Rust migration. While Rust supports unsafe code for low-level operations, the core value of migration lies in producing code that executes within Rust's safe subset, allowing users to benefit from Rust's strong memory safety guarantees.
Despite rapid progress in large language models (LLMs) for code generation, fully automated C-to-safe-Rust transpilation remains challenging. Existing machine learning benchmarks largely focus on competitive programming problems rather than realistic, multi-file systems programming. Other efforts like SWE-bench target bug-fixing scenarios with localized edits, not whole-program translation or structural refactoring.
To address these limitations, the researchers introduce CRUST-Bench, a benchmark for evaluating automated C-to-Rust transpilation in realistic settings. CRUST-Bench comprises 100 C repositories, each paired with manually crafted Rust interfaces and test cases to assess the correctness and quality of transpilation. The Rust interfaces serve as formal specifications, defining function signatures, type annotations, and ownership constraints to guide the translation process. These interfaces enforce idiomatic and memory-safe Rust patterns, ensuring transpiled code adheres to Rust's safety guarantees. The accompanying test cases provide validation, verifying that the generated Rust code correctly implements the specified behavior.
Figure 1: Example of a CRUST-Bench task showing the challenge of translating pointer-based C code to safe, idiomatic Rust.
Why Current C-to-Rust Transpilation Benchmarks Fall Short
A number of benchmarks have been proposed to evaluate source code translation and transformation tasks, including transpilation, automated debugging, and safe code generation. While these benchmarks provide valuable insights, those that focus specifically on C-to-Rust transpilation tend to exhibit important gaps—particularly limited task scope, lack of robust correctness validation, and insufficient evaluation of memory safety. Many are restricted to small, synthetic examples or overlook whether the generated Rust code adheres to safe and idiomatic practices.
| Benchmark | # Projects | Multi-file? | Avg LoC | Rust Interface? | Rust Tests? |
|---|---|---|---|---|---|
| CROWN | 20 | ✓ | 31.7K | ✗ | ✗ |
| TransCoder-Rust | 520 | ✗ | 108 | ✗ | ✗ |
| FLOURINE | 112 | ✗ | 68 | ✗ | ✗ |
| C2SaferRust | 7 | ✓ | 9.3K | ✗ | ✗ |
| SYZYGY | 1 | ✓ | 2.5K | ✗ | ✗ |
| LAERTES | 17 | ✓ | 24K | ✗ | ✗ |
| CRUST-Bench (Ours) | 100 | ✓ | 958 | ✓ | ✓ |
Table 1: Comparison of C-to-Rust transpilation benchmarks.
Compared to prior benchmarks, CRUST-Bench includes a substantial number of real-world projects while keeping them within reach for LLM-guided transpilation techniques. A key feature of CRUST-Bench is that it provides safe Rust interfaces and corresponding test files. This is important because existing transpilation tools, such as c2rust, often produce naive translations that rely heavily on unsafe constructs, sidestepping Rust's safety guarantees rather than properly adapting C code. LLM-based approaches also risk generating inconsistent interfaces across files, making it difficult to produce a coherent, working Rust codebase.
Inside the CRUST-Bench Framework: Structure and Validation
Each instance in CRUST-Bench is built on a C repository, formalized as a collection of source files. The goal of transpilation is to produce a corresponding Rust repository with a parallel file structure, ensuring that each Rust file is a direct translation of the corresponding C file.
Validation of the transpiled Rust code is based on three criteria:
- It must conform to a well-defined interface that specifies a set of abstract datatypes and functions
- The transpiled Rust code must compile without errors
- A set of tests must pass, confirming functional correctness
| C Code Properties | Avg | Max |
|---|---|---|
| Test cases | 76.4 | 952 |
| Test files | 3.0 | 19 |
| Test coverage | 67% | 100% |
| Lines of code | 958 | 25,436 |
| Pointer dereferences | 264 | 12,664 |
| Functions | 34.6 | 418 |
Table 2: Properties of C code in the CRUST-Bench dataset.
The projects in the benchmark were sourced from open-source repositories on GitHub, covering a diverse range of software categories created between 2005 and 2025. The selection includes programming language infrastructure (e.g., compilers), algorithmic libraries (e.g., solvers), system utilities (e.g., shell implementations), and others.
To construct CRUST-Bench, the researchers applied a multi-stage preprocessing and selection pipeline. They filtered for projects entirely written in C that meet a minimum complexity threshold: containing at least one dynamic memory allocation keyword, including build scripts, and having associated test files. Following initial filtering, they manually reviewed the remaining projects to assess code quality and ensure test completeness.
| Metric | Total | Avg | Max |
|---|---|---|---|
| Interface Structure | |||
| Interface files | 299 | 3.0 | 21 |
| Interface functions | 3,085 | 30.9 | 415 |
| Function arguments | 5716 | 57.2 | 1484 |
| Ownership and Type Features | Percent | ||
| % Functions with reference args | 56% | ||
| % Custom types in arguments | 44% | ||
| % Custom types in return types | 50% | ||
| % Functions with mutable references | 30% |
Table 3: Statistics on Rust interfaces in CRUST-Bench showing the complexity of the required transpilation task.
The final benchmark includes 100 C projects annotated with corresponding Rust interfaces, capturing a wide spectrum of interface complexity and idiomatic Rust features. The dataset includes 3,085 interface functions across 299 interface files, with an average of 30.9 functions per project. This benchmark structure provides a comprehensive and realistic evaluation of C-to-Rust transpilation capabilities.
Experimental Setup: Models and Systems Evaluated
The researchers evaluated both closed-source and open-weight large language models (LLMs) on the CRUST-Bench benchmark. For closed-source models, they included GPT-4o, o1, and o1-mini from OpenAI; Claude-3.5-Sonnet and Claude-3.7-Sonnet from Anthropic; and Gemini-1.5-Pro from Google. On the open-weight side, they evaluated models with strong code generation capabilities: Virtuoso (a distilled variant of DeepSeek-V3), QwQ-2-32B, and LLaMA-3-8B.
For models that support temperature control, they used greedy decoding (T=0) to ensure deterministic outputs and consistent pass@1 evaluation. Empirically, they found that higher temperatures significantly degraded performance, likely due to the long-context requirements and stringent correctness constraints of the tasks. The best results were obtained using a general task description followed by concise, point-based instructions. Notably, explicit directives—such as "do not use libc" and "the code must compile"—proved more effective than vague statements like "generate safe Rust."
The researchers investigated two strategies for leveraging additional compute to improve model performance through iterative self-repair:
Compiler repair: Incorporates only compiler error messages into the prompt during each repair round, allowing the model to iteratively address syntactic and type-level issues flagged by the Rust compiler.
Test repair: Extends the first approach by also including information about failing test cases in the prompt, providing richer feedback about the correctness of the generated code.
For both strategies, they performed three rounds of self-repair per task, balancing the benefits of iterative refinement with practical runtime constraints.
The researchers also adapted SWE-agent into a two-stage workflow they refer to as pipelined SWE-agent. In this setup, an LLM first generates an initial Rust implementation from a C source file and its associated Rust interface. SWE-agent then attempts to repair any resulting compiler errors by iteratively editing the generated code.
Results and Analysis
The results reveal that even the best-performing models struggle with C-to-safe-Rust transpilation, with OpenAI's o1 achieving only a 15% success rate in a single-shot setting.
| Model | Pass@1 | Pass@1 + Compiler repair (r=3) |
Pass@1 + Test repair (r=3) |
|||
|---|---|---|---|---|---|---|
| Build | Test | Build | Test | Build | Test | |
| OpenAI o1 | 32 | 15 | 69 | 28 | 54 | 37 |
| Claude 3.7 | 26 | 13 | 54 | 23 | 49 | 32 |
| Claude 3.5 | 26 | 11 | 49 | 21 | 38 | 24 |
| o1 mini | 19 | 9 | 47 | 16 | 27 | 21 |
| GPT-4o | 18 | 7 | 52 | 18 | 42 | 22 |
| Gemini 1.5 Pro | 11 | 3 | 35 | 11 | 30 | 14 |
| Virtuoso (Distilled Deepseek V3) | 2 | 2 | 21 | 6 | 10 | 6 |
| QwQ-2 32B | 1 | 0 | 1 | 0 | 1 | 0 |
| Adapted SWE-agent (Claude-3.7) | 41 | 32 | - | - | - | - |
Table 4: Pass rates on CRUST-Bench for different models in single-shot and repair settings.
Applying iterative self-repair leads to substantial gains in both build and test success rates across all models. With three rounds of Compiler repair, improvements in build success reached as high as 37% for o1, and test pass rates improved by up to 13% compared to the single-shot baseline. Extending this approach with Test repair yielded additional improvements in test success—between 0% and 9% over the corresponding Compiler repair setting.
However, this gain in test correctness comes at the cost of build stability: the researchers observed a 5% to 20% drop in build success when moving from Compiler to Test repair. This degradation can be attributed to the fact that incorporating test case information encourages the model to make more aggressive semantic changes, which may inadvertently introduce new compilation errors.
The pipelined SWE-agent workflow improved performance from a 13% test pass rate (Claude 3.7 Sonnet baseline) to 32%, demonstrating a substantial benefit compared to the single-shot performance. However, this performance only matches, rather than exceeds, that of the Claude 3.7 Sonnet + Test repair strategy, which also reaches 32% after Test repair.
| Model | Config | % projects with error | ||||||
|---|---|---|---|---|---|---|---|---|
| Mismatch | Borrow | Missing | Unimpl | Trait | Args | Unsafe | ||
| OpenAI o1 | base | 30 | 42 | 13 | 14 | 17 | 3 | 0 |
| repair | 8 | 9 | 2 | 11 | 0 | 1 | 0 | |
| Claude 3.7 | base | 15 | 18 | 4 | 44 | 10 | 0 | 0 |
| repair | 4 | 4 | 4 | 46 | 1 | 1 | 0 | |
| Claude 3.5 | base | 24 | 27 | 23 | 37 | 14 | 4 | 0 |
| repair | 22 | 6 | 16 | 55 | 5 | 5 | 0 | |
| o1 mini | base | 46 | 34 | 40 | 28 | 34 | 5 | 0 |
| repair | 21 | 13 | 10 | 29 | 1 | 6 | 0 | |
| GPT-4o | base | 48 | 35 | 25 | 20 | 22 | 4 | 1 |
| repair | 12 | 20 | 10 | 26 | 6 | 2 | 0 | |
| Gemini 1.5 Pro | base | 40 | 24 | 23 | 33 | 17 | 2 | 1 |
| repair | 18 | 13 | 7 | 35 | 8 | 3 | 1 | |
| Virtuoso (Distilled Deepseek V3) | base | 60 | 26 | 19 | 45 | 33 | 12 | 0 |
| repair | 38 | 23 | 17 | 50 | 15 | 9 | 0 | |
| QwQ-2 32B | base | 9 | 2 | 9 | 94 | 5 | 1 | 0 |
| repair | 13 | 2 | 9 | 92 | 3 | 2 | 0 | |
| Adapted SWE-Agent | 15 | 17 | 4 | 44 | 8 | 1 | 0 |
Table 5: Error breakdown for different models and configurations.
To better understand the failure modes, the researchers analyzed the distribution of compiler errors. Common errors included:
- Type mismatches: Errors when the generated Rust code has incompatible types when calling functions
- Borrowing violations: Errors arising from violations of Rust's ownership, borrowing, and lifetime rules
- Missing imports/modules: Errors due to missing import statements or module declarations
- Unimplemented functions: Functions declared in the interface but not implemented in the transpiled code
- Trait-related errors: Missing trait implementations or trait bound violations
The analysis shows that self-repair is particularly effective at addressing certain types of errors. For Claude 3.7 Sonnet, borrowing-related errors were reduced by 75% after applying compiler-guided repair, and trait-related errors were reduced by 90%. Type errors were cut by 50% in the first round of repair but plateaued in subsequent rounds.
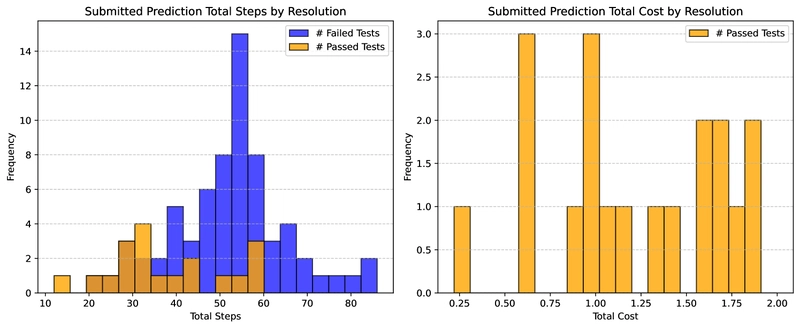
Figure 2: Statistics showing that SWE-agent typically resolves most fixable issues early in the process.
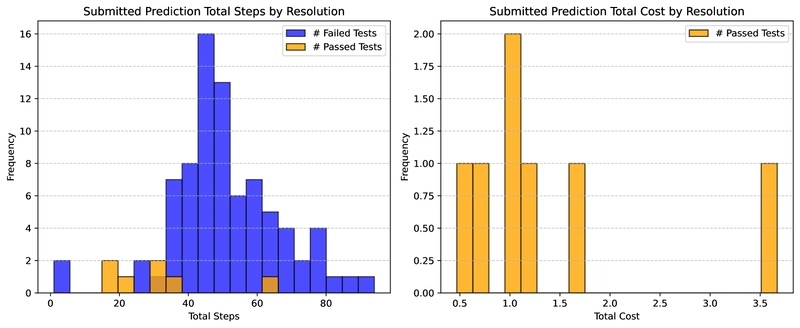
Figure 3: Statistics showing that even with a higher budget, SWE-agent resolves most fixable issues early in the process.
Related Work and Future Directions
Prior work on code generation benchmarks has focused primarily on generating Python code from natural language prompts, typically framed as short, competition-style problems with test cases. Other efforts have explored more realistic settings: incorporating external APIs, class-level code generation, repository-level tasks with inter-file dependencies, and rigorous testing. However, CRUST-Bench evaluates code generation over multi-file C projects with complex dependencies, using code as input rather than natural language, and targets the generation of safe, idiomatic Rust.
Recent work on C-to-Rust transpilation spans both syntactic and learning-based approaches. Tools like c2rust focus on syntactic translation, often relying on external libraries like libc and layout-preserving annotations to maintain compatibility. However, these approaches do not guarantee memory safety and frequently produce Rust code with unsafe blocks. More recent techniques combine syntactic translation with LLM-based post-processing to improve code quality.
Conclusion
CRUST-Bench represents a significant step forward in evaluating C-to-Rust transpilation systems. The benchmark allows verification of LLM-powered transpilation systems according to three criteria: (1) Do they successfully follow the given interface during transpilation? (2) Does the Rust code compile? (3) Does the code pass the provided Rust test cases?
The results show that even the best approach with state-of-the-art LLMs, OpenAI's o1 with iterative repair from both compiler errors and test failures, only succeeds on 37% of tasks in the benchmark. This leaves significant room for improvement in future systems that aim to transform legacy C codebases into safe, idiomatic Rust.
As organizations increasingly seek to modernize legacy systems and improve software security, the ability to automatically transpile C to safe Rust code will become increasingly valuable. CRUST-Bench provides a rigorous framework for assessing progress in this important area and will help drive improvements in transpilation technology.



