
_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)































































![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)
![Dummy Models Showcase 'Unbelievably' Thin iPhone 17 Air Design [Images]](https://www.iclarified.com/images/news/97114/97114/97114-640.jpg)









































































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)























































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)















































































































Mellum: How We Trained a Model to Excel in Code Completion
Code completion has always been a defining strength of JetBrains products. So, when adding AI into our products, we knew it had to deliver top-tier code completion. This post covers how we trained the model behind our cloud-based completion. Initial research: What about obvious model options? We started by testing both closed-source LLMs via APIs […]

Code completion has always been a defining strength of JetBrains products. So, when adding AI into our products, we knew it had to deliver top-tier code completion. This post covers how we trained the model behind our cloud-based completion.
Initial research: What about obvious model options?
We started by testing both closed-source LLMs via APIs and open-source alternatives. But we quickly hit some roadblocks:
- As we were aiming for on-the-fly completion, typical chat LLMs proved themselves impractical due to high costs and substantial latency. Such models were also missing critical code completion features, like fill in the middle (FIM) and token healing.
- Chat models also tend to provide their outputs in inconsistent format, making it harder to properly process the response and insert suggestions in the editor.
- One of our biggest concerns was the lack of transparency about the data used for training, which could lead to potential risks related to the use of licensed code. While some open-source models do offer transparency in their data sources, we opted not to use them due to production stability issues.
Mellum: A bird’s-eye view of the model
After evaluating our options, we concluded that a relatively small in-house code completion model was the way to go. We set a goal of training a high-quality model with reasonable inference costs and latency using transparent data. We determined that staying under 4B parameters would allow us to support efficient inference for all users. Additionally, since our model has been trained primarily on code, its token vocabulary is specialized for coding tasks.
To train the model, we implemented a three-stage process, with each stage bringing in new knowledge and improving the generation quality. We started with basic pre-training on a large corpus of standalone files and then fine-tuned on a smaller number of contextual examples. Finally, to align the model to our product needs and remove undesired generations, we used reinforcement learning with AI feedback (RLAIF).
Let’s take a look at the training steps in detail.
Pre-training stage
To avoid risks connected with training data, we started training from scratch. The goal of the pre-training stage was to introduce the model to a wide variety of languages, make it learn the syntax, patterns, and general programming concepts.
Dataset
We used TheStack as the main source of code data in various languages. It’s not fully up to date, but we addressed this by collecting additional data with fresh code, filtering it by repo and files licenses and cleaning it of personal identifiable information (PII). This ensures that our dataset is both legally compliant and useful.
Pre-training process
For pre-training, we sampled our combined dataset multiple times to reach approximately 3 trillion tokens. We used an 8192-token context window and split the dataset into chunks of matching size. For half of the files in each chunk, we applied a fill-in-the-middle (FIM) transformation. This involves splitting the file into three parts (prefix, middle, and suffix), then rearranging them so that the model learns to predict the missing middle segment given the surrounding context. This technique encourages the model to consider both the preceding and following code when generating suggestions, which better mimics real-world usage in code editors.
The pre-training was conducted on a cluster of 16 nodes with 8 H100 GPUs each, and it took about 15 days to complete. The result was our 4B-parameter Mellum-base model. For comparison, 100M code completion models, which we deploy locally in JetBrains IDEs, typically train in about a week on a single 8 H100 GPUs node.
The pre-training produces a general-purpose code completion model with broad knowledge across many programming languages. However, at this step the model is trained to achieve one simple objective: prediction of the next token in a randomly selected segment of a file. Without more context, the model won’t understand your code structure and won’t know when to stop generating.
These limitations are precisely what the fine-tuning stage is designed to address.
Context-aware fine-tuning
Better fill-in-the-middle examples
Unlike pre-training – where we randomly select chunks of code for prediction – fine-tuning focuses on slicing the code in more meaningful ways, i.e. by extracting fragments you’re more likely to see “in the wild”.
The visual below illustrates this approach. The code shown in blue is what we ask the model to predict. In the second example, for instance, the selected fragment stays within the scope of a single function. This setup better reflects a typical user scenario.

Building contextual examples
Even with improved fill-in-the-middle splitting, we’re still operating within the scope of a single file, which doesn’t accurately reflect how most developers work. In practice, completing code often requires an understanding of surrounding files and broader project context.
One of JetBrains’ superpowers is expertise in symbol resolution, usage search, and other IDE tooling. So, for the sake of scalable data pre-processing, we launched an internal project called Code Engine: a cross-platform SDK providing a lightweight, high-performance CLI tool designed to collect contextual information directly from plain files, without requiring the project to be indexed. Such an SDK allowed us to build contextual examples across thousands of repositories on the internal MapReduce cluster in a reasonable amount of time.
However, finding the right algorithms took some trial and error. Here are a few examples to give you an idea of some of the challenges we had to overcome while trying to find the best context collection approach for our model:
- Sorting files that are most similar by Jaccard distance on lines
- Using files from import statements
- Creating a repomap
- …and much more.
Language-specific fine-tuning
We hypothesized that smaller models like ours could benefit significantly from specialization. While the base model is trained on over 80 programming languages, most users typically work with just one or two (e.g. Java or Python). As a result, we fine-tune separate models for some of the most popular languages, allowing them to better capture language-specific patterns, libraries, and developer workflows:
- mellum-all – supports the majority of languages and dialects available in JetBrains’ IDEs, but the completion quality is slightly lower than that of specialized models
- mellum-python – specialized for Python and Jupyter
- mellum-jotlin – specialized for Java and Kotlin
- mellum-web – specialized for the web (coming soon!)
Refining with RLAIF
The final step in our training pipeline focuses on removing undesired behaviors due to misalignment between the model’s training objectives and user expectations. For instance, from a training perspective, it’s perfectly valid to generate placeholders like TODO(“Not implemented”) or pass since these patterns are common in public code repositories. However, these are not likely to be helpful as actual code completion suggestions.
To address such issues, we apply an additional training phase using reinforcement learning from AI feedback (RLAIF), incorporating synthetic data crafted from rules and model-generated preferences. We construct a dataset of completion pairs in two main categories:
- Rule-based completion pairs: We take real examples from our dataset and deliberately degrade them – replacing meaningful code with generic placeholders like pass, comments, or TODO statements.
- Mellum-generated completion pairs: For a given prompt, we generate two completions – one with low temperature (more deterministic and often higher quality), and another with high temperature (typically more erratic or lower quality). We then use an external LLM to rank the two completions, producing a labeled positive-negative pair.

This dataset is then used to train the model to better reflect user preferences. Currently, we use the direct preference optimization (DPO) algorithm, which makes the model more inclined to generate positive or preferred completion examples.
This approach not only increases the evaluation score but also reduces the number of annoying generation artifacts.
How good is Mellum?
Spoiler: the model performs extremely well for its size! Here’s how we evaluated it:
- First, we evaluated our models on the internal benchmark that we call “JetBrains BigCode”.
- Then, we ran our models on well-known public benchmarks like SAFIM.
- Finally, we measured the user-centric metrics by leveraging feature usage logs.
Below, we break our feedback loops down into two categories: offline evaluation (with pre-determined datasets) and online evaluation (with real user data).
Offline evaluation
Discussing datasets is always nice, but what about the metrics?
While creating the dataset is challenging enough, it’s even more challenging to create a good metric that compares the ground truth completion with the one proposed by the neural model. We did a little research and ended up with a combination of two main metrics:
- EM:
- Exact match – a popular choice for code completion evaluation.
- The prediction is considered good if the first line of the completion matches the first line of the ground truth with minimal pre-processing.
- KK:
- The metric was named after its authors, Karol and Katya, who designed it and manually annotated the threshold-estimating dataset.
- The number of suggested lines that are found in the ground truth, divided by the total number of lines in the suggested completion.
We also use some additional evaluation techniques, including chrF and LLM-as-a-Judge, for comparing the model variations, but we won’t be covering them here for the sake of keeping the blog post concise. Keep following our updates for more!
JetBrains BigCode
We evaluated the model using a benchmark dataset derived from our internal tool, JetBrains BigCode, covering the most popular languages supported by Mellum – including Python, Kotlin, and Java. We ensured that our evaluation dataset has no overlap with the training dataset and transformed it to the FIM structure with contexts gathered using Code Engine.
One of the key advantages of the JetBrains BigCode dataset is its ability to slice code snippets based on various features, such as repository topic, popularity, age, whether the code is main or test code, and recent activity (e.g. commits in the past year). This is done for two primary reasons. First, a well-performing model should demonstrate strong results across all these slices, not just on a subset of them. Second, public benchmarks often end up in model training datasets over time, leading to evaluation contamination. To mitigate the latter risk, we designed our age and activity slices to better reflect real-world conditions.
As a result, by maintaining full control over our dataset rather than relying on public benchmarks, we can more reliably assess model quality across different coding styles and practices. According to our experiments on JetBrains BigCode, the complicated nature of the base model does pay dividends in terms of performance. So, it’s demonstrably a good idea to have a strong base model, then fine-tune it, and then align it with DPO.

Additionally, our JetBrains BigCode evaluation runs show that we are in good company with well-known battle-tested polyglot models, while being smaller and more efficient. Of course, larger models do outperform us, but they come with significantly higher serving costs, making them less practical for our products.
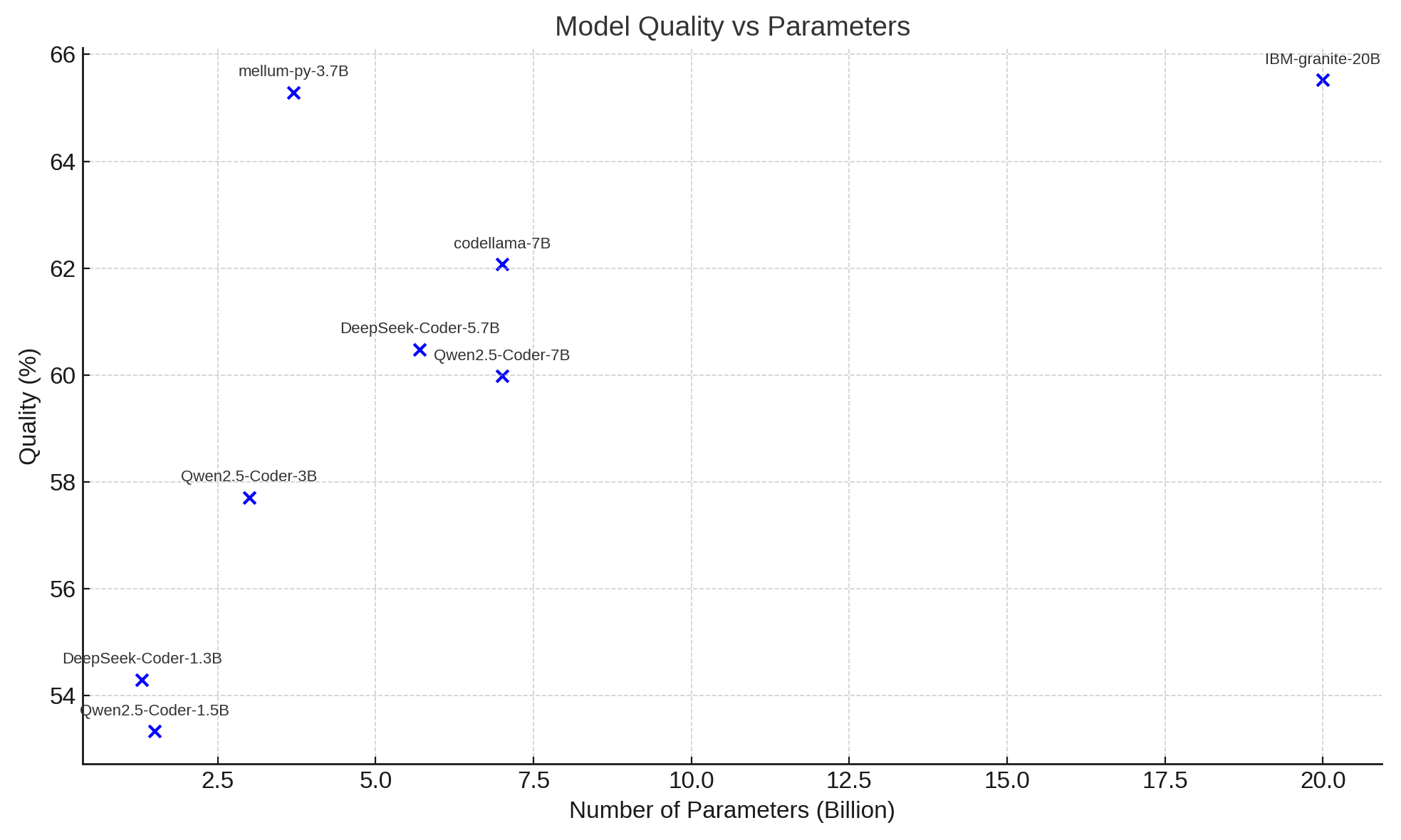
Public benchmarks
Besides evaluation on an internal dataset, we compared the capabilities of our models on different public benchmarks like multilingual benchmark SAFIM (syntax-aware fill in the middle). Stay tuned as we will share benchmarks data for Mellum soon!
That said, it’s important to remember that benchmarks like JetBrains BigCode and SAFIM, while valuable for scalable offline evaluation, don’t fully capture the experience of a real developer using the model. And ultimately, that’s who we’re building for.
Online evaluation
To ensure a positive impact on the user experience, we measure several metrics on the feature usage logs, following the same pipeline we described in the paper Full Line Code Completion: Bringing AI to Desktop.
Long story short, our main metric is called ratio of completed code (RoCC). It is defined as a ratio of symbols of code written with code completion among all code written in the editor. We generally try to optimize for this metric. The core idea and motivation are simple: the more generated text appears in the editor, the better our code completion is. The good thing about the RoCC is that we can vary the number of code completion contributors that we account for. This allows us to, for instance, calculate a general in-editor RoCC or Mellum-specific RoCC.
Another important metric is the acceptance rate (AR), which is the number of accepted suggestions divided by the number of all shown suggestions. This metric is widely used in the community and is also fairly intuitive: the more users accept our suggestions, the better.
Below, we provide some online metrics data for various popular languages:
RoCC (Mellum + standard completion) RoCC (only Mellum) AR Java 46% 23% 35% Kotlin 45% 25% 31% Python 32% 23% 35% JS/TS 39% 23% 32% C# 45% 18% 32% Go 45% 30% 44% PHP 40% 26% 34% Rust 37% 24% 35%
Outcomes and what’s next for Mellum
This was a challenging journey for our ML team, but it resulted in one general completion model and several specialized ones that are all available via the JetBrains AI platform and are currently powering code completion inside JetBrains AI Assistant. To conclude the blogpost, here are our few next steps:
- As mentioned earlier, we are currently working on a specialized model for web development languages that should further boost quality for various languages, and we plan to make this publicly available at some point in the near future.
- We would also like to scale the number of parameters further, introducing more diverse data to the training set at the same time. This way Mellum becomes capable of other AI-for-code tasks as well. Keep in mind that service performance remains a key for us, so we expect to stay within reasonable size boundaries as we expand the model.
Try coding with Mellum and share your impressions with us!






