




































































![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)










![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)
























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
































































































































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

Kuwain: Arabic Language Injection Boosts English LLM Without Retraining
This is a Plain English Papers summary of a research paper called Kuwain: Arabic Language Injection Boosts English LLM Without Retraining. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Breaking New Ground: Adding Arabic to English-Only Models Most large language models focus primarily on English, making them less effective for languages with distinct characteristics like Arabic. This English-centric nature creates a significant barrier for users of non-English languages, particularly those with different linguistic structures and writing systems. Kuwain 1.5B offers a novel solution for adding Arabic capabilities to an existing English language model without compromising its original abilities. Rather than retraining the entire model from scratch—a computationally expensive approach—the researchers developed a method that strategically adds new layers to a pre-trained model while expanding its vocabulary. This approach stands out because it: Preserves the model's original English knowledge Adds robust Arabic language capabilities Requires significantly fewer resources than training a new model Achieves competitive performance despite a small model size Model performance vs size visualization: Points represent models on the Arabic NLP benchmark, where point size indicates efficiency (average score divided by model size). Larger points show better performance-to-size ratio. The visualization above demonstrates how Kuwain compares to other models despite its small size, showing remarkable efficiency in the performance-to-size ratio. This innovative approach addresses a critical gap in language technology, providing a pathway for efficient multilingual model development that could extend to other underrepresented languages. The State of Multilingual and Arabic-Focused LLMs Approaches to Creating Multilingual Models Training multilingual models from scratch requires enormous computational resources and data. The complexity of optimizing randomly initialized parameters demands extensive training data to guide effective performance. Several approaches have emerged to make this process more efficient: Continuous pre-training extends an existing model's pre-training on new language data, reducing costs compared to starting from scratch. This approach has been used for German (LeoLM-7B), Japanese (Swallow-MS-7b), and Greek (Meltemi-7B). Vocabulary expansion adapts a model's tokenizer to accommodate new languages, often critical for languages with different writing systems. Mixture-of-Experts (MoE) techniques train separate language components on distinct multilingual subsets, reducing interference between languages. However, these approaches face common challenges. Models trained with continuous pre-training often perform worse on original language tasks—LeoLM-7B showed a -2.6% decline on English benchmarks, while Swallow-MS-7b saw a -5.3% drop. This phenomenon, known as catastrophic forgetting, remains a significant obstacle in multilingual model development. The Landscape of Arabic Language Models Recent years have seen several notable Arabic-focused language models, each with distinct approaches and limitations: Jais is an open-source bilingual model trained from scratch for Arabic and English tasks. While innovative, it suffers from significant imbalance—it was exposed to substantially more English data than Arabic, with much of the Arabic content translated from English sources. This creates outputs that often reflect English cultural contexts rather than authentic Arabic cultural nuances. AceGPT adapts the English-focused LLaMA2 model through additional pre-training and tuning. However, it retains LLaMA2's original tokenizer, which processes Arabic at the character level, leading to inefficient representation of Arabic morphology and vocabulary. ArabianGPT, built on the GPT-2-small architecture, features an advanced tokenizer optimized for Arabic linguistics. Its exclusive focus on Arabic limits its ability to handle multilingual tasks or leverage knowledge transfer from English. ALLaM enhances Arabic language processing by leveraging a mixture of Arabic and English data, incorporating vocabulary expansion and continued pre-training. While effective, it requires extensive computational resources. These models share common limitations: high training costs, degradation in original language performance, and inadequate tokenization strategies—particularly problematic for morphologically rich languages like Arabic. Kuwain addresses these limitations with a lightweight, cost-efficient alternative that extends an existing English-centric model while preserving its original capabilities. This approach makes Kuwain uniquely positioned as a practical solution for multilingual expansion in resource-constrained environments. Building a Balanced Bilingual Dataset Sourcing High-Quality Arabic and
This is a Plain English Papers summary of a research paper called Kuwain: Arabic Language Injection Boosts English LLM Without Retraining. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Breaking New Ground: Adding Arabic to English-Only Models
Most large language models focus primarily on English, making them less effective for languages with distinct characteristics like Arabic. This English-centric nature creates a significant barrier for users of non-English languages, particularly those with different linguistic structures and writing systems.
Kuwain 1.5B offers a novel solution for adding Arabic capabilities to an existing English language model without compromising its original abilities. Rather than retraining the entire model from scratch—a computationally expensive approach—the researchers developed a method that strategically adds new layers to a pre-trained model while expanding its vocabulary.
This approach stands out because it:
- Preserves the model's original English knowledge
- Adds robust Arabic language capabilities
- Requires significantly fewer resources than training a new model
- Achieves competitive performance despite a small model size
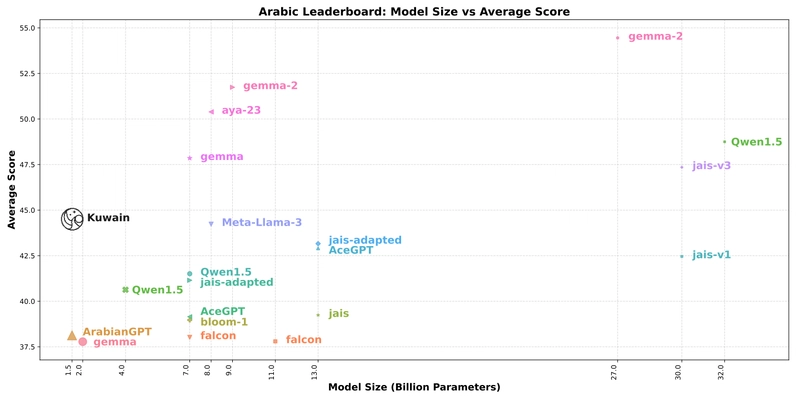
Model performance vs size visualization: Points represent models on the Arabic NLP benchmark, where point size indicates efficiency (average score divided by model size). Larger points show better performance-to-size ratio.
The visualization above demonstrates how Kuwain compares to other models despite its small size, showing remarkable efficiency in the performance-to-size ratio. This innovative approach addresses a critical gap in language technology, providing a pathway for efficient multilingual model development that could extend to other underrepresented languages.
The State of Multilingual and Arabic-Focused LLMs
Approaches to Creating Multilingual Models
Training multilingual models from scratch requires enormous computational resources and data. The complexity of optimizing randomly initialized parameters demands extensive training data to guide effective performance. Several approaches have emerged to make this process more efficient:
Continuous pre-training extends an existing model's pre-training on new language data, reducing costs compared to starting from scratch. This approach has been used for German (LeoLM-7B), Japanese (Swallow-MS-7b), and Greek (Meltemi-7B).
Vocabulary expansion adapts a model's tokenizer to accommodate new languages, often critical for languages with different writing systems.
Mixture-of-Experts (MoE) techniques train separate language components on distinct multilingual subsets, reducing interference between languages.
However, these approaches face common challenges. Models trained with continuous pre-training often perform worse on original language tasks—LeoLM-7B showed a -2.6% decline on English benchmarks, while Swallow-MS-7b saw a -5.3% drop. This phenomenon, known as catastrophic forgetting, remains a significant obstacle in multilingual model development.
The Landscape of Arabic Language Models
Recent years have seen several notable Arabic-focused language models, each with distinct approaches and limitations:
Jais is an open-source bilingual model trained from scratch for Arabic and English tasks. While innovative, it suffers from significant imbalance—it was exposed to substantially more English data than Arabic, with much of the Arabic content translated from English sources. This creates outputs that often reflect English cultural contexts rather than authentic Arabic cultural nuances.
AceGPT adapts the English-focused LLaMA2 model through additional pre-training and tuning. However, it retains LLaMA2's original tokenizer, which processes Arabic at the character level, leading to inefficient representation of Arabic morphology and vocabulary.
ArabianGPT, built on the GPT-2-small architecture, features an advanced tokenizer optimized for Arabic linguistics. Its exclusive focus on Arabic limits its ability to handle multilingual tasks or leverage knowledge transfer from English.
ALLaM enhances Arabic language processing by leveraging a mixture of Arabic and English data, incorporating vocabulary expansion and continued pre-training. While effective, it requires extensive computational resources.
These models share common limitations: high training costs, degradation in original language performance, and inadequate tokenization strategies—particularly problematic for morphologically rich languages like Arabic.
Kuwain addresses these limitations with a lightweight, cost-efficient alternative that extends an existing English-centric model while preserving its original capabilities. This approach makes Kuwain uniquely positioned as a practical solution for multilingual expansion in resource-constrained environments.
Building a Balanced Bilingual Dataset
Sourcing High-Quality Arabic and English Data
The Kuwain training dataset comprises 110 billion tokens, with a strategic split of 90 billion tokens in Arabic and 20 billion in English. This composition reflects the model's focus on Arabic capabilities while maintaining sufficient English representation to preserve original knowledge.
The data comes from publicly available open-source collections:
- CulturaX
- C4
- ArabicText 2022 (including ArabicWeb22-A, ArabicWeb16, OSCAR, ArabicWeb22-B, CC100-AR, and Arabic Tweets)
Beyond Modern Standard Arabic, the dataset incorporates dialectal Arabic from Hugging Face repositories, preserving the linguistic richness and diversity of regional Arabic varieties. This inclusion is crucial for developing a model that can handle the full spectrum of Arabic usage.
To maintain evaluation integrity, the researchers ensured none of the evaluation datasets appeared in the training data, preventing data leakage that could artificially inflate performance metrics.
Rigorous Arabic Text Cleaning Process
Arabic text presents unique challenges that require specialized cleaning techniques. The researchers implemented a comprehensive set of processing steps:
- Removing corrupted characters and repetitions
- Stripping markup and elongation characters
- Normalizing white space
- Preserving Quranic symbols and special characters
- Normalizing encoding inconsistencies
- Unifying orthographic variants (different forms of Arabic letters)
- Filtering malformed examples and short text
This cleaning process was released as a customizable open-source script to support reproducibility and future Arabic text pre-processing applications. For English data, the researchers adopted the filtering pipeline from the BLOOM project, which promotes clean, diverse content.
The meticulous attention to data quality, particularly for Arabic, creates a foundation for effective model training that respects the language's unique characteristics while maintaining consistency and clarity.
A Two-Pronged Approach: Layer Extension and Vocabulary Expansion
Strategic Layer Addition: Building Upon Existing Knowledge
Inspired by Llama-Pro, the researchers developed a layer extension approach that adds new capabilities while preserving the original model's knowledge. This technique involves inserting new layers into an existing model architecture rather than retraining the entire model.
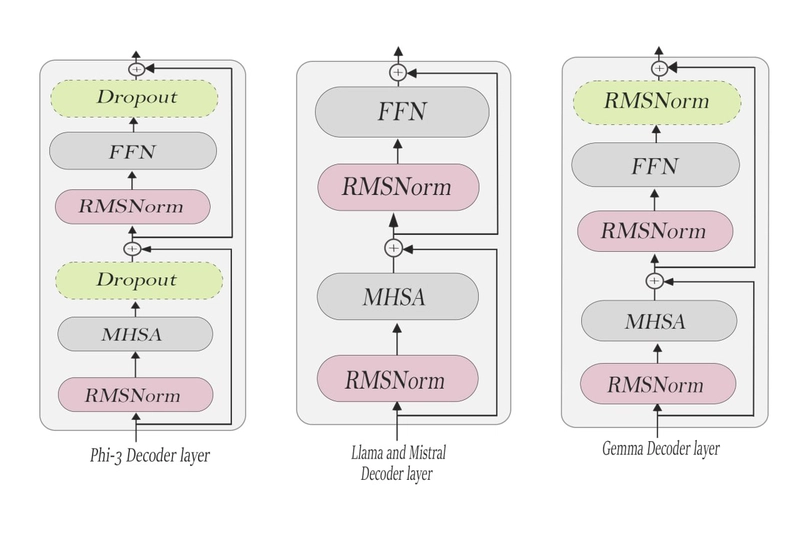
Models decoder architecture showing the typical structure of decoder layers in foundation models.
The technical foundation of this approach builds on the standard decoder block structure used in popular models like Llama, Mistral, Phi-3, and Gemma-2. These models share similar decoder architectures with minor variations, consisting of multi-head self-attention (MHSA), feed-forward networks (FFN), and normalization layers.
To extend the model, the researchers introduced additional identity blocks that initially preserve the model's original behavior. These identity blocks are achieved by initializing the additional weight matrices to zero, ensuring they don't disrupt existing functionalities. During training, only these newly added layers and the final layer of the original model are updated, keeping most of the original parameters frozen.
This strategic approach:
- Preserves the base model's knowledge
- Reduces training time and computational requirements
- Allows for targeted learning of new language features
- Minimizes the risk of catastrophic forgetting
Arabic-Optimized Tokenization: Speaking a New Language
Extending a tokenizer's vocabulary is critical when adapting a model to a new language, especially when the original tokenizer isn't well-suited for that language. Many open-source models like LLaMA-2, Phi-3, and Mistral include only 28 Arabic tokens—just enough to cover the Arabic alphabet. This limited representation fails to capture Arabic's morphological richness and lexical diversity.
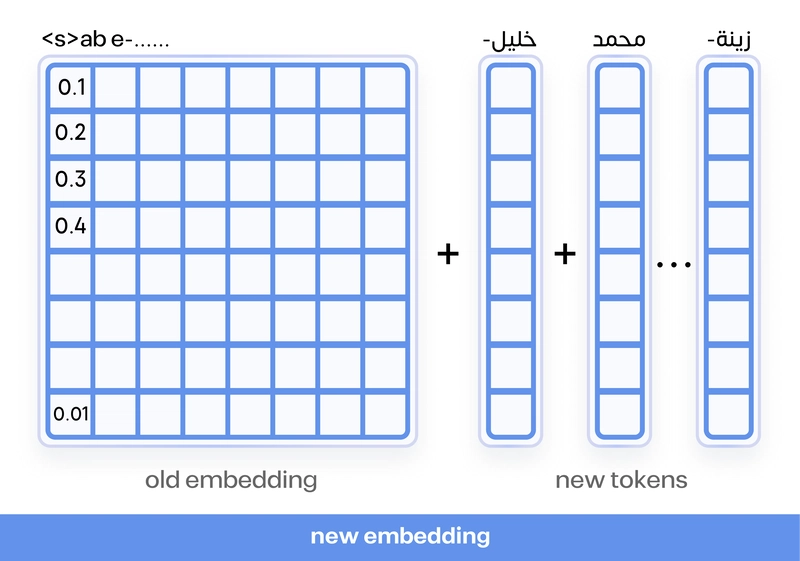
Vocabulary expansion by adding new Arabic tokens to the tokenizer.
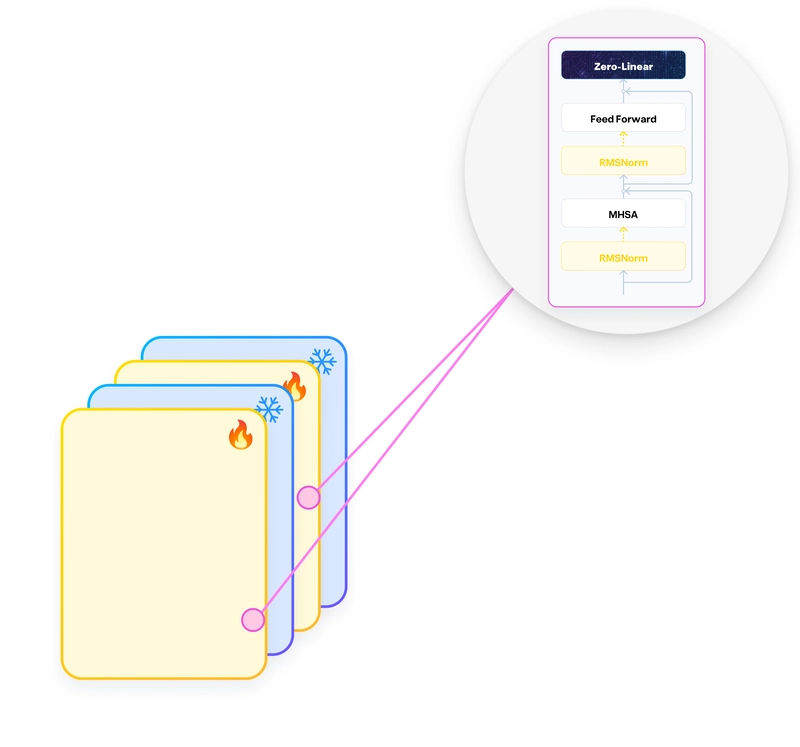
Extension of model layers, where newly added layers were trainable while the original layers remained frozen.
The researchers trained a specialized tokenizer using SentencePiece with their Arabic training data, resulting in 26,000 additional tokens optimized for Arabic. This expanded vocabulary was integrated with the base model's tokenizer, creating a final vocabulary of 54,000 tokens.
This vocabulary expansion improves tokenization efficiency, enabling the model to represent Arabic more effectively. The benefits extend beyond performance improvements to include:
- Shorter training time due to more efficient token representation
- Increased effective context length for better handling of Arabic text
- Better capture of Arabic morphological patterns and word formations
- Reduced computational resources needed for training
The combination of strategic layer extension and vocabulary expansion forms the technical core of Kuwain's approach, enabling efficient adaptation to Arabic while preserving English capabilities.
Experimental Design: Finding the Optimal Configuration
Finding the Perfect Layer Arrangement
The researchers conducted extensive experiments to determine both the ideal number and optimal placement of additional layers. They explored configurations ranging from 6 to 10 layers, running each experiment for 20,000 training steps on a subset of the dataset.
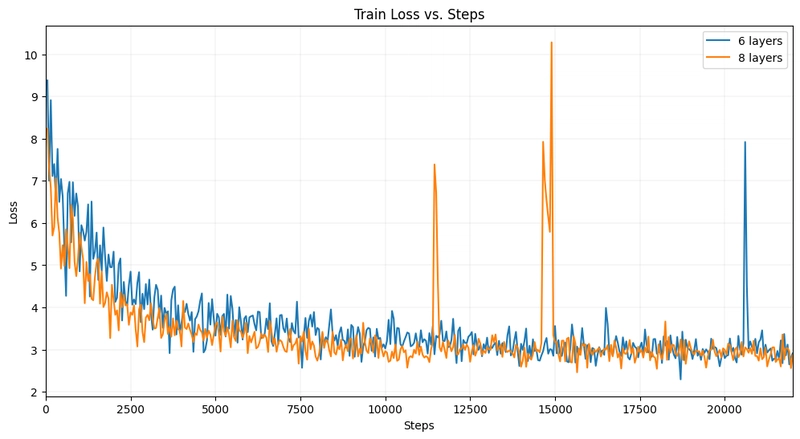
Training loss chart showing instability when freezing the last layer
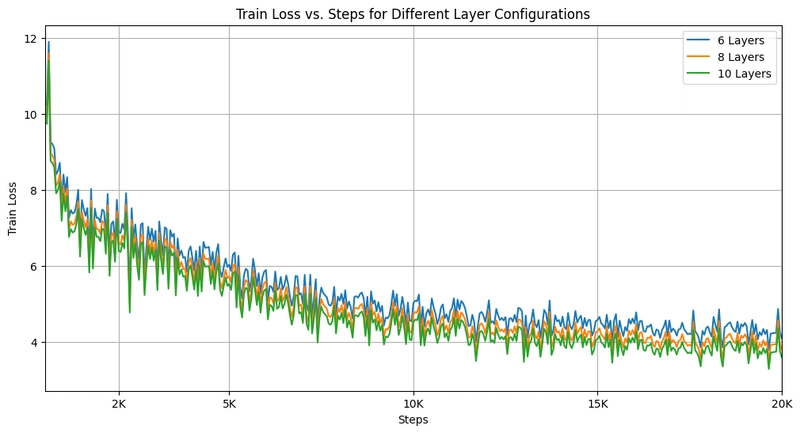
Training loss chart showing stable training when enabling the last layer and avoiding consecutive layers
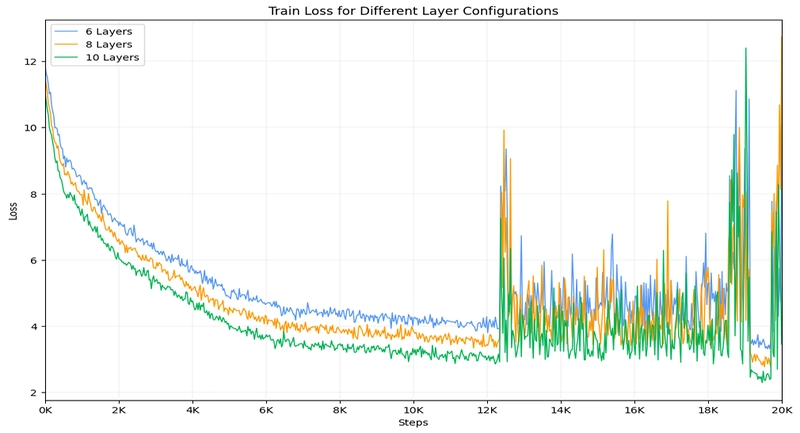
Training loss chart showing degraded performance when stacking new layers consecutively
Key findings from these experiments revealed several architectural principles:
- Avoid consecutive layer insertion - Placing new layers back-to-back led to training instability
- Keep the final encoder layer trainable - This proved essential for stable training outcomes
- Distribute new layers strategically - The optimal placement didn't follow a regular pattern or equal intervals
- Eight new layers proved optimal - While configurations with 8-10 layers performed similarly, 8 layers (a 30% increase in model size) delivered the best results
These experiments highlight the importance of architectural choices in model adaptation. As shown in the loss charts, freezing the last layer led to unstable training (chart a), while enabling the last layer and avoiding consecutive layer placement produced stable training dynamics (chart b). Stacking multiple new layers consecutively significantly worsened performance (chart c).
The distributed 8-layer configuration emerged as the most effective architecture, balancing added capacity with training stability and efficient knowledge transfer.
Tokenizer Optimization: Balancing Vocabulary Size and Expansion Ratio
The researchers evaluated their proposed tokenizer against two prominent Arabic language models: AraBERT and Jais. This analysis focused on two critical metrics:
- Vocabulary Size: The number of unique tokens in the tokenizer's vocabulary, affecting its ability to represent linguistic features
- Expansion Ratio: The ratio of tokenized text length to original text length, indicating how efficiently the tokenizer processes text
| Model | Expansion Ratio | Vocabulary Size |
|---|---|---|
| Kuwain Tokenizer | 2.30 | 26K |
| AraBERT | 2.51 | 54K |
| Jais | 2.19 | 44K |
Comparison of tokenization metrics across different Arabic language models. The vocab size used presents the Arabic vocab for each model, where the full vocab has a different number.
An ideal tokenizer balances a reasonable expansion ratio with a manageable vocabulary size. While Jais achieves the best expansion ratio at 2.19, the Kuwain tokenizer demonstrates superior efficiency when considering the tradeoff between this metric and vocabulary size. With just 26K tokens, Kuwain achieves an expansion ratio of 2.30—very close to Jais's performance despite using 41% fewer tokens.
This analysis, based on tokenizing over one million examples, suggests that Kuwain's tokenizer achieves effective text representation without an expansive vocabulary, leading to more efficient model training and deployment.
The Minimum English Data Requirement
A crucial question in adapting models to new languages is how much original language data is needed to maintain performance. The researchers discovered that Kuwain requires only 20% of the original English data to maintain performance on English tasks—significantly less than the 50% ratio used in comparable approaches.
| Dataset | TinyLlama | Kuwain | Kuwain-lt-$\phi$ |
|---|---|---|---|
| HellaSwag | 59.20 | 57.79 | 55.79 |
| Obqa | 36.00 | 35.60 | 32.60 |
| ARC-c | 30.10 | 30.29 | 27.29 |
| ARC-e | 55.25 | 56.31 | 51.31 |
| boolq | 57.83 | 60.43 | 54.43 |
| piqa | 73.29 | 72.63 | 69.63 |
| WinoGrande | 59.12 | 59.99 | 55.99 |
| Avg | 52.99 | 53.28 | 49.56 |
Performance comparison on English benchmarks between TinyLlama and two variants of Kuwain: trained with 20% English data (Kuwain) and with less than 20% English data (Kuwain-lt-$\phi$). Results show how English performance varies with data proportion.
The results show that reducing English data below 20% (as in Kuwain-lt-φ) caused a notable decline in English benchmark performance, with the average score dropping from 52.99 to 49.56. In contrast, training with 20% English data maintained performance comparable to—and in some cases slightly better than—the original TinyLlama model.
This finding has significant implications for efficient multilingual model development: a minimal amount of original language data serves as an "anchor" that helps the model retain existing knowledge while efficiently learning new skills.
Traditional Methods vs. Layer Extension: A Clear Comparison
To evaluate the impact of their layer extension approach, the researchers created a baseline model (Kuwain-Naive) trained using conventional continued pre-training. This model used the same Arabic dataset and vocabulary expansion but without layer extension—the entire model was trained rather than just additional layers.
| Dataset | TinyLlama | Kuwain-Naive |
|---|---|---|
| HellaSwag | 59.20 | 45.35 |
| Obqa | 36.00 | 29.20 |
| ARC-c | 30.10 | 25.68 |
| ARC-e | 55.25 | 45.24 |
| boolq | 57.83 | 61.90 |
| piqa | 73.29 | 66.70 |
| WinoGrande | 59.12 | 53.91 |
| Avg | 52.99 | 46.85 |
English evaluation of TinyLlama vs. Kuwain-Naive (standard pre-training).
The results revealed a stark contrast: while Kuwain-Naive effectively learned Arabic, it suffered catastrophic forgetting of English knowledge. Its average performance on English benchmarks dropped significantly from 52.99 to 46.85.
In contrast, the layer extension approach (Kuwain) maintained strong English performance while achieving Arabic capabilities comparable to Kuwain-Naive:
| Dataset | Kuwain-Naive | Kuwain |
|---|---|---|
| HellaSwag | 32.59 | 33.20 |
| Obqa | 27.80 | 27.60 |
| ARC-c | 25.26 | 25.49 |
| ARC-e | 36.44 | 36.76 |
| boolq | 61.80 | 62.35 |
| piqa | 54.06 | 54.35 |
| copa | 57.30 | 56.17 |
| Avg | 42.17 | 42.27 |
Arabic evaluation of Kuwain-Naive vs. our model Kuwain.
This comparison highlights the power of the layer extension approach: it enables the model to acquire new language capabilities without sacrificing existing knowledge, providing a more robust foundation for multilingual applications.
Performance Evaluation: Punching Above Its Weight
Kuwain demonstrates significant improvements in Arabic language understanding and generation compared to the base TinyLlama model. The performance gains are particularly impressive given the model's compact size and the efficiency of the training approach.
| Dataset | TinyLlama | Kuwain |
|---|---|---|
| HellaSwag | 29.90 | 37.14 |
| Obqa | 28.12 | 29.20 |
| ARC-c | 23.00 | 28.15 |
| ARC-e | 26.76 | 40.10 |
| boolq | 50.88 | 62.04 |
| piqa | 51.68 | 56.42 |
| copa | 48.31 | 58.38 |
| Avg | 36.95 | 44.49 |
Arabic Benchmark Evaluation of Kuwain and TinyLlama
Across all evaluated benchmarks, Kuwain outperforms TinyLlama on Arabic tasks, with an average improvement of 7.54 percentage points. This demonstrates the effectiveness of the language injection approach in developing substantial capabilities in a previously unsupported language.
To contextualize these results, the researchers evaluated Kuwain against a wide range of multilingual and Arabic-focused models on the Arabic language leaderboard. The results are remarkable:
| Model | Size | ARC-c | ARC-e | Boolq | Copa | HellaSwag | Obqa | Piqa | Avg |
|---|---|---|---|---|---|---|---|---|---|
| gemma | 2B | 27.67 | 27.66 | 52.76 | 46.67 | 25.61 | 34.75 | 49.37 | 37.784286 |
| falcon | 11B | 28.10 | 25.80 | 51.81 | 46.67 | 25.40 | 37.17 | 49.65 | 37.800000 |
| falcon | 7B | 27.93 | 25.34 | 57.52 | 43.33 | 25.20 | 36.16 | 50.68 | 38.022857 |
| ArabianGPT | 1.5B | 25.86 | 27.41 | 62.12 | 47.78 | 24.35 | 30.51 | 48.83 | 38.122857 |
| falcon | 40B | 26.55 | 25.76 | 52.85 | 50.00 | 25.37 | 36.77 | 50.08 | 38.197143 |
| bloom-1 | 7B | 28.62 | 25.85 | 62.12 | 44.44 | 25.31 | 35.56 | 50.95 | 38.978571 |
| jais | 13B | 28.53 | 28.43 | 62.12 | 48.89 | 25.67 | 35.35 | 54.56 | 40.507143 |
| Qwen1.5 | 4B | 29.31 | 28.09 | 62.76 | 52.22 | 25.07 | 36.16 | 50.85 | 40.637143 |
| AceGPT | 7B | 29.66 | 28.64 | 62.36 | 48.89 | 25.89 | 38.38 | 52.59 | 40.915714 |
| jais-adapted | 7B | 30.60 | 31.01 | 63.50 | 48.89 | 25.55 | 38.38 | 52.97 | 41.557143 |
| Qwen1.5 | 7B | 33.71 | 33.33 | 62.12 | 47.78 | 25.70 | 38.59 | 53.79 | 42.145714 |
| jais-v1 | 30B | 32.24 | 32.83 | 62.70 | 48.89 | 25.82 | 39.60 | 56.57 | 42.664286 |
| AceGPT | 13B | 33.36 | 33.76 | 63.74 | 51.11 | 25.09 | 39.19 | 54.17 | 42.917143 |
| jais-adapted | 13B | 33.62 | 34.90 | 65.03 | 47.78 | 26.41 | 39.39 | 54.99 | 43.160000 |
| AceGPT-v1.5 | 13B | 36.55 | 37.61 | 62.24 | 45.56 | 26.59 | 41.82 | 54.99 | 43.622857 |
| Meta-Llama-3.1 | 8B | 36.21 | 37.77 | 63.34 | 50.00 | 26.45 | 40.61 | 51.99 | 43.767143 |
| Qwen1.5 | 14B | 35.60 | 37.23 | 65.09 | 47.78 | 26.79 | 39.60 | 54.39 | 43.782857 |
| Meta-Llama-3 | 8B | 35.69 | 39.00 | 62.12 | 50.00 | 26.65 | 42.63 | 53.68 | 44.252857 |
| Kuwain | 1.5B | 28.15 | 40.10 | 62.04 | 58.38 | 37.14 | 29.20 | 56.42 | 44.490000 |
| jais-v3 | 30B | 36.98 | 41.46 | 75.25 | 52.22 | 26.66 | 42.02 | 56.63 | 47.317143 |
| gemma | 7B | 42.16 | 45.60 | 67.94 | 47.78 | 26.90 | 46.46 | 58.16 | 47.857143 |
| Qwen1.5 | 32B | 43.19 | 43.99 | 64.08 | 51.11 | 29.19 | 46.87 | 59.36 | 48.255714 |
| aya-23 | 8B | 40.09 | 40.31 | 77.91 | 54.44 | 30.86 | 44.44 | 64.70 | 50.392857 |
| jais-adapted | 70B | 47.67 | 51.73 | 74.14 | 44.44 | 28.44 | 47.47 | 63.07 | 50.994286 |
| Qwen1.5 | 72B | 49.05 | 46.40 | 65.61 | 51.11 | 34.02 | 47.27 | 64.76 | 51.174286 |
| gemma-2 | 9B | 53.28 | 55.80 | 64.33 | 51.11 | 29.11 | 51.52 | 60.23 | 52.197143 |
| Qwen1.5 | 110B | 51.81 | 51.18 | 62.12 | 50.00 | 36.65 | 50.91 | 63.72 | 52.341429 |
| Meta-Llama-3.1 | 70B | 52.93 | 52.28 | 62.15 | 56.67 | 35.38 | 50.10 | 63.72 | 53.318571 |
| Meta-Llama-3 | 70B | 54.91 | 55.80 | 62.18 | 56.67 | 35.03 | 51.72 | 62.79 | 54.157143 |
| gemma-2 | 27B | 56.55 | 59.09 | 65.58 | 55.56 | 28.43 | 52.93 | 62.96 | 54.442857 |
| aya-23 | 35B | 49.22 | 50.80 | 82.94 | 55.56 | 35.81 | 49.49 | 73.87 | 56.812857 |
| Qwen2 | 72B | 56.55 | 57.45 | 69.97 | 55.56 | 38.33 | 57.17 | 69.67 | 57.814286 |
| c4ai-command-r-v01 | 35B | 54.66 | 60.24 | 82.70 | 52.22 | 33.42 | 54.14 | 69.99 | 58.195714 |
| c4ai-command-r-plus | 104B | 57.76 | 60.87 | 85.00 | 52.22 | 37.88 | 52.73 | 70.92 | 59.625714 |
Arabic Leader board evaluation
Despite being the smallest model in the comparison at just 1.5B parameters, Kuwain achieves an average score of 44.49—outperforming many much larger models:
- It surpasses Falcon (7B, 11B, and even 40B variants)
- It outperforms BLOOM-1 (7B)
- It exceeds Jais (13B) and ArabianGPT (1.5B)
- It competes with Meta-Llama-3 (8B)
This performance is particularly impressive considering that many of these competing models were:
- Specifically designed for Arabic (like Jais, AceGPT, and ArabianGPT)
- Trained on vastly more data
- Much larger in parameter count (up to 40B parameters)
Kuwain's strong performance demonstrates the effectiveness of the language injection approach, showing that strategic architectural modifications and vocabulary expansion can achieve competitive results with significantly lower computational requirements.
Advancing Multilingual AI: Implications and Future Work
The research on Kuwain 1.5B demonstrates a novel and effective approach to expanding language models' linguistic capabilities while preserving their existing knowledge base. Through vocabulary expansion, strategic layer extension, and selective training, the researchers addressed a significant challenge in multilingual natural language processing.
Key achievements include:
Preservation of prior knowledge - The approach successfully maintained the model's performance on English tasks, avoiding the catastrophic forgetting seen with conventional training methods.
Effective acquisition of Arabic language - The model achieved strong performance on Arabic benchmarks comparable to conventional methods, without compromising its ability to learn new linguistic structures.
Computational efficiency - The approach reduced training costs by approximately 70% compared to retraining the entire model from scratch.
Minimal original language data - Just 20% of the original English data was sufficient to maintain performance, significantly less than previous approaches.
Looking forward, the researchers identified several promising directions for future work:
Large-scale Arabic data collection - Gathering and processing more Arabic data from diverse sources to create a richer training dataset for further improvements.
Scaling up the approach - Extending the method to larger models to test the hypothesis that new language performance correlates with the original performance of the base model.
The Kuwain approach has broad implications for multilingual AI development. It offers a practical pathway for extending language models to new languages without the prohibitive costs of training from scratch. This could democratize access to advanced language technologies for languages with fewer resources, helping to address the persistent language gap in AI systems.
By demonstrating that a small model can achieve competitive performance through targeted architectural modifications, this work challenges the assumption that larger models are always necessary for effective multilingual capabilities. The findings suggest that strategic, focused approaches can yield impressive results while conserving computational resources—an important consideration as AI systems continue to grow in size and complexity.


