




































































![Apple M4 Mac Mini Back on Sale for $499 [Deal]](https://www.iclarified.com/images/news/97617/97617/97617-640.jpg)









































































































_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
















































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)











































































































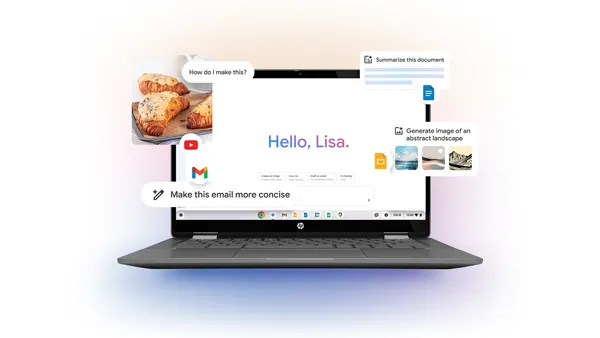

















![Designing a Robust Modular Hardware-Oriented Application in C++ [closed]](https://i.sstatic.net/f2sQd76t.webp)


















































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






























































Grafana - detecting abnormal behavior of applications
Have Grafana on premise with prometheus. Some anomalies can be detected by viewing a set of charts (slow requests, retries, pending transactions, etc.). SRE operators need to have the opportunity to see all information in one Grafana widget instead of multiple charts to manage incidents. They also need to be familiar with all services. Abnormal behavior can easily be recognized in one chart: but when trying to find a problem through 10 or more services in one chart, hopping in one graph loses sight of the others, and the problem can't be seen: The easiest workaround seems to be to convert the linear time series graphs into a single status history widget. I tried the rate() function with a zero, 15-minute, and 24-hour offset. I can also filter events by status: success="yes". For one service status history looks like this: But for all services, the recognition ability is still unacceptable: and some problems can't be resolved: The detector can occasionally be triggered by problems that happened 24 hours ago It doesn't detect zero events gaps as an incidents (should) The detector is triggered by events that are not present in the queries The LLM chatbots recommends to use "avg_over_time" conditions, but I don't know how to do that in PromQL. I don't include my formulas here on purpose so I won't judge the discussion before it goes in the right direction. Can't find the solutions I'm looking for here and in open resources, e.g. in play.grafana.org

Have Grafana on premise with prometheus.
Some anomalies can be detected by viewing a set of charts (slow requests, retries, pending transactions, etc.). SRE operators need to have the opportunity to see all information in one Grafana widget instead of multiple charts to manage incidents. They also need to be familiar with all services.
Abnormal behavior can easily be recognized in one chart:
but when trying to find a problem through 10 or more services in one chart, hopping in one graph loses sight of the others, and the problem can't be seen:

The easiest workaround seems to be to convert the linear time series graphs into a single status history widget. I tried the rate() function with a zero, 15-minute, and 24-hour offset. I can also filter events by status: success="yes". For one service status history looks like this:

But for all services, the recognition ability is still unacceptable:

and some problems can't be resolved:
- The detector can occasionally be triggered by problems that happened 24 hours ago
- It doesn't detect zero events gaps as an incidents (should)
- The detector is triggered by events that are not present in the queries
The LLM chatbots recommends to use "avg_over_time" conditions, but I don't know how to do that in PromQL.
I don't include my formulas here on purpose so I won't judge the discussion before it goes in the right direction. Can't find the solutions I'm looking for here and in open resources, e.g. in play.grafana.org
![Z buffer problem in a 2.5D engine similar to monument valley [closed]](https://i.sstatic.net/OlHwug81.jpg)