




































































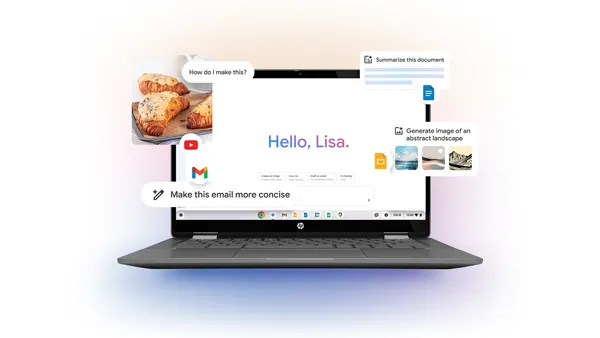
![Apple M4 Mac Mini Back on Sale for $499 [Deal]](https://www.iclarified.com/images/news/97617/97617/97617-640.jpg)








































































































_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

















































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)



























































































































![Designing a Robust Modular Hardware-Oriented Application in C++ [closed]](https://i.sstatic.net/f2sQd76t.webp)




















































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






























































Meta's Llama 3.1 Can Recall 42% of the First Harry Potter Book
Timothy B. Lee has written for the Washington Post, Vox.com, and Ars Technica — and now writes a Substack blog called "Understanding AI." This week he visits recent research by computer scientists and legal scholars from Stanford, Cornell, and West Virginia University that found that Llama 3.1 70BÂ(released in July 2024) has memorized 42% of the first Harry Potter book well enough to reproduce 50-token excerpts at least half the time... The paper was published last month by a team of computer scientists and legal scholars from Stanford, Cornell, and West Virginia University. They studied whether five popular open-weight models — three from Meta and one each from Microsoft and EleutherAI — were able to reproduce text from Books3, a collection of books that is widely used to train LLMs. Many of the books are still under copyright... Llama 3.1 70B — a mid-sized model Meta released in July 2024 — is far more likely to reproduce Harry Potter text than any of the other four models.... Interestingly, Llama 1 65B, a similar-sized model released in February 2023, had memorized only 4.4 percent of Harry Potter and the Sorcerer's Stone. This suggests that despite the potential legal liability, Meta did not do much to prevent memorization as it trained Llama 3. At least for this book, the problem got much worse between Llama 1 and Llama 3. Harry Potter and the Sorcerer's Stone was one of dozens of books tested by the researchers. They found that Llama 3.1 70B was far more likely to reproduce popular books — such as The Hobbit and George Orwell's 1984 — than obscure ones. And for most books, Llama 3.1 70B memorized more than any of the other models... For AI industry critics, the big takeaway is that — at least for some models and some books — memorization is not a fringe phenomenon. On the other hand, the study only found significant memorization of a few popular books. For example, the researchers found that Llama 3.1 70B only memorized 0.13 percent of Sandman Slim, a 2009 novel by author Richard Kadrey. That's a tiny fraction of the 42 percent figure for Harry Potter... To certify a class of plaintiffs, a court must find that the plaintiffs are in largely similar legal and factual situations. Divergent results like these could cast doubt on whether it makes sense to lump J.K. Rowling, Richard Kadrey, and thousands of other authors together in a single mass lawsuit. And that could work in Meta's favor, since most authors lack the resources to file individual lawsuits. Why is it happening? "Maybe Meta had trouble finding 15 trillion distinct tokens, so it trained on the Books3 dataset multiple times. Or maybe Meta added third-party sources — such as online Harry Potter fan forums, consumer book reviews, or student book reports — that included quotes from Harry Potter and other popular books..." "Or there could be another explanation entirely. Maybe Meta made subtle changes in its training recipe that accidentally worsened the memorization problem." Read more of this story at Slashdot.

Timothy B. Lee has written for the Washington Post, Vox.com, and Ars Technica — and now writes a Substack blog called "Understanding AI."
This week he visits recent research by computer scientists and legal scholars from Stanford, Cornell, and West Virginia University that found that Llama 3.1 70BÂ(released in July 2024) has memorized 42% of the first Harry Potter book well enough to reproduce 50-token excerpts at least half the time...
The paper was published last month by a team of computer scientists and legal scholars from Stanford, Cornell, and West Virginia University. They studied whether five popular open-weight models — three from Meta and one each from Microsoft and EleutherAI — were able to reproduce text from Books3, a collection of books that is widely used to train LLMs. Many of the books are still under copyright... Llama 3.1 70B — a mid-sized model Meta released in July 2024 — is far more likely to reproduce Harry Potter text than any of the other four models....
Interestingly, Llama 1 65B, a similar-sized model released in February 2023, had memorized only 4.4 percent of Harry Potter and the Sorcerer's Stone. This suggests that despite the potential legal liability, Meta did not do much to prevent memorization as it trained Llama 3. At least for this book, the problem got much worse between Llama 1 and Llama 3. Harry Potter and the Sorcerer's Stone was one of dozens of books tested by the researchers. They found that Llama 3.1 70B was far more likely to reproduce popular books — such as The Hobbit and George Orwell's 1984 — than obscure ones. And for most books, Llama 3.1 70B memorized more than any of the other models...
For AI industry critics, the big takeaway is that — at least for some models and some books — memorization is not a fringe phenomenon. On the other hand, the study only found significant memorization of a few popular books. For example, the researchers found that Llama 3.1 70B only memorized 0.13 percent of Sandman Slim, a 2009 novel by author Richard Kadrey. That's a tiny fraction of the 42 percent figure for Harry Potter... To certify a class of plaintiffs, a court must find that the plaintiffs are in largely similar legal and factual situations. Divergent results like these could cast doubt on whether it makes sense to lump J.K. Rowling, Richard Kadrey, and thousands of other authors together in a single mass lawsuit. And that could work in Meta's favor, since most authors lack the resources to file individual lawsuits.
Why is it happening? "Maybe Meta had trouble finding 15 trillion distinct tokens, so it trained on the Books3 dataset multiple times. Or maybe Meta added third-party sources — such as online Harry Potter fan forums, consumer book reviews, or student book reports — that included quotes from Harry Potter and other popular books..."
"Or there could be another explanation entirely. Maybe Meta made subtle changes in its training recipe that accidentally worsened the memorization problem."


Read more of this story at Slashdot.

