


































































![3DMark Launches Native Benchmark App for macOS [Video]](https://www.iclarified.com/images/news/97603/97603/97603-640.jpg)
![Craig Federighi: Putting macOS on iPad Would 'Lose What Makes iPad iPad' [Video]](https://www.iclarified.com/images/news/97606/97606/97606-640.jpg)
![Apple Releases Updated Build of iOS 26 Beta 1 [Download]](https://www.iclarified.com/images/news/97608/97608/97608-640.jpg)












![Google Play Store not showing Android system app updates [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2021/08/google-play-store-material-you.jpeg?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
















































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)










































































































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
Introducing AutoPatchBench: A Benchmark for AI-Powered Security Fixes
We are introducing AutoPatchBench, a benchmark for the automated repair of vulnerabilities identified through fuzzing. By providing a standardized benchmark, AutoPatchBench enables researchers and practitioners to objectively evaluate and compare the effectiveness of various AI program repair systems. This initiative facilitates the development of more robust security solutions, and also encourages collaboration within the community [...] Read More... The post Introducing AutoPatchBench: A Benchmark for AI-Powered Security Fixes appeared first on Engineering at Meta.

- We are introducing AutoPatchBench, a benchmark for the automated repair of vulnerabilities identified through fuzzing.
- By providing a standardized benchmark, AutoPatchBench enables researchers and practitioners to objectively evaluate and compare the effectiveness of various AI program repair systems.
- This initiative facilitates the development of more robust security solutions, and also encourages collaboration within the community to address the critical challenge of software vulnerability repair.
- AutoPatchBench is available now on GitHub.
AI is increasingly being applied to solve security challenges, including repairing vulnerabilities identified through fuzzing. However, the lack of a standardized benchmark for objectively assessing AI-driven bug repair agents specific to fuzzing has impeded progress in academia and the broader community. Today, we are publicly releasing AutoPatchBench, a benchmark designed to evaluate AI program repair systems. AutoPatchBench sits within CyberSecEval 4, Meta’s new benchmark suite for evaluating AI capabilities to support defensive use cases. It features 136 fuzzing-identified C/C++ vulnerabilities in real-world code repos along with verified fixes sourced from the ARVO dataset.
AutoPatchBench provides a standardized evaluation framework for assessing the effectiveness of AI-assisted vulnerability repair tools. This benchmark aims to facilitate a comprehensive understanding of the capabilities and limitations of various AI-driven approaches to repairing fuzzing-found bugs. By offering a consistent set of evaluation criteria, AutoPatchBench fosters transparency and reproducibility in research, enabling both academic and industry professionals to identify best practices and areas for improvement.
Fixing fuzzing-found vulnerabilities with AI
Fuzzing is a cornerstone in automated testing, renowned for its effectiveness in uncovering security vulnerabilities. By bombarding a target program with vast amounts of pseudo-random input data, fuzz testing exposes critical security and reliability issues, such as memory corruption, invalid pointer dereference, integer overflow, and parsing errors.
However, resolving a fuzzing crash is often a labor intensive task, demanding intricate debugging and thorough code review to pinpoint and rectify the underlying cause. This process can be both time-consuming and resource-intensive. Unlike regular test failures, fuzzing bugs frequently reveal security vulnerabilities that pose severe threats to system integrity and user data. Given these stakes, automating the repair of fuzzing bugs with AI becomes not just advantageous but essential. AI’s ability to swiftly analyze patterns and propose solutions significantly reduces the time and effort required for repairs, making it an invaluable ally in safeguarding our digital environments.
Let’s explore the process of addressing bugs identified through fuzzing by examining a demonstrative example. Consider the following C function, which harbors a read/write buffer overflow vulnerability:
#include
#include
void process_input(const char *input) {
char buffer[8];
strcpy(buffer, input); // Potential buffer overflow
printf("Processed: %s\n", buffer);
}
In this scenario, a fuzzing harness might supply an input that surpasses the buffer’s capacity, leading to a crash due to buffer overflow. A typical stack trace from such a crash might appear as follows:
== Fuzzer Crash Report ==
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7af1223 in strcpy () from /lib/x86_64-linux-gnu/libc.so.6
(gdb) bt
#0 0x00007ffff7af1223 in strcpy ()
#1 0x0000555555555140 in process_input (input=0x7fffffffe695 "AAAAAA...")
#2 0x0000555555555162 in main (argc=2, argv=0x7fffffffe5f8)Here, the process_input function invokes strcpy on a string that exceeds the eight-character buffer, causing a segmentation fault. A straightforward patch involves ensuring the copy operation remains within the buffer’s limits. This can be achieved by using a bounded copy function like strncpy or implementing a length check before copying:
void process_input(const char *input) {
char buffer[8];
strncpy(buffer, input, sizeof(buffer) - 1);
buffer[sizeof(buffer) - 1] = '\0';
printf("Processed: %s\n", buffer);
}
This patch ensures that the string remains within the buffer’s limits, effectively preventing out-of-bounds writes. Its correctness can be confirmed by verifying that the fuzzing input, which previously caused the crash, no longer does so. Additional checks can be conducted to ensure the patch doesn’t introduce any unintended side effects.
As illustrated, fixing a fuzzing crash involves:
- Analyzing the crash stack trace and the target code.
- Pinpointing the root cause.
- Patching the vulnerable code.
- Verifying the fix’s accuracy.
An AI-based solution can automate these steps by utilizing an LLM’s capability to understand and generate code.
Why we developed AutoPatchBench
AutoPatchBench is informed by key advancements in the field of AI-driven program repair, particularly those focusing on fuzzing-found vulnerabilities. Among the notable contributions is Google’s tech report on AI-powered patching, which pioneered the use of LLMs for addressing fuzzing crashes, achieving a 15% fix rate with their proprietary dataset. Subsequently, Google’s study on generic program repair agents introduced the GITS-Eval benchmark, encompassing 178 bugs across various programming languages.
In the realm of AI software engineering agents, benchmarks like SWE-Bench and SWE-Bench Verified have gained widespread acceptance for evaluating generic AI SWE agents. However, these benchmarks do not specifically tackle the unique challenges posed by fuzzing-found vulnerabilities, which demand specialized approaches that utilize fuzzing-specific artifacts and address security concerns.
AutoPatchBench addresses this gap by offering a dedicated benchmark focused on a wide variety of C/C++ vulnerabilities of 11 crash types identified through fuzzing with automated verification capability. Unlike the broader focus of GITS-Eval and SWE-Bench, AutoPatchBench is specifically designed to assess the effectiveness of AI-driven tools in repairing security-critical bugs typically uncovered by fuzzing. This targeted approach enables a more precise evaluation of AI capabilities in meeting the complex requirements of fuzzing-found vulnerabilities, thereby advancing the field of AI-assisted program repair in a focused manner.
Inside AutoPatchBench
We’re making AutoPatchBench publicly available as part of CyberSecEval 4 to encourage community collaboration in tackling the challenge of automating fuzzing crash repairs. This benchmark is specifically designed for AI program repair agents focusing on C/C++ bugs identified through fuzzing. It includes real-world C/C++ vulnerabilities with verified fixes sourced from the ARVO dataset, and incorporates additional verification of AI-generated patches through fuzzing and white-box differential testing.
ARVO dataset
The ARVO dataset serves as the foundation for AutoPatchBench, offering a comprehensive collection of real-world vulnerabilities that are essential for advancing AI-driven security research. Sourced from C/C++ projects identified by Google’s OSS-Fuzz, ARVO includes over 5,000 reproducible vulnerabilities across more than 250 projects. Each entry is meticulously documented with a triggering input, a canonical developer-written patch, and the capability to rebuild the project in both its vulnerable and patched states.
However, there are notable challenges when using the ARVO dataset as a benchmark for AI patch generation:
- While reproducibility is vital for a reliable benchmark, the ARVO dataset includes samples where crashes are not consistently reproducible. Some samples lack crash stack traces, making it exceedingly difficult to address the crash.
- Although ARVO provides a ground-truth fix for each identified vulnerability, it lacks an automated mechanism to verify the correctness of a generated patch. Objective automated verification is essential for a benchmark focused on patch generation.
AutoPatchBench addresses these challenges by creating a curated subset and by employing a comprehensive and automated verification process.
Selection criteria
To ensure the reliability and effectiveness of AutoPatchBench, we meticulously filtered the ARVO dataset samples based on the following criteria:
- Valid C/C++ vulnerability: The ground-truth fix shall edit one or more C/C++ source files that are not fuzzing harnesses.
- Dual-container setup: Each vulnerability is accompanied by two containers—one that contains vulnerable code and another for the fixed code—that build without error.
- Reproducibility: The crash must be consistently reproducible within the vulnerable container.
- Valid stack trace: A valid stack trace must be present within the vulnerable container to facilitate accurate diagnosis and repair.
- Successful compilation: The vulnerable code must compile successfully within its designated container, ensuring that the environment is correctly set up for testing.
- Fixed code verification: The fixed code must also compile successfully within its respective container, confirming that the patch does not introduce new build issues.
- Crash resolution: The crash must be verified as resolved within the fixed container, demonstrating the effectiveness of the patch.
- Fuzzing pass: The fixed code must pass a comprehensive fuzzing test without finding new crashes, ensuring that the ground-truth patch maintains the integrity and functionality of the software.
After applying these rigorous selection criteria, we retained 136 samples for AutoPatchBench that fulfill the necessary conditions for both patch generation and verification. From this refined set, we created a down-sampled subset of 113 AutoPatchBench-Lite samples to provide a focused benchmark for testing AI patch generation tools. These subsets preserves the diversity and complexity of real-world vulnerabilities including 11 distinct crash types, offering a solid foundation for advancing AI-driven security solutions.
Patch verification
In the process of patch generation, the patch generator utilizes two automated methods to verify the viability of a generated patch before submitting it for evaluation. The first method involves attempting to build the patched program, which checks for syntactic correctness. The second method involves attempting to reproduce the crash by running the input that initially triggered it. If the crash no longer occurs, it suggests that the issue has been resolved. However, these steps alone are insufficient to guarantee the correctness of the patch, as a patch might not maintain the program’s intended functionality, rendering it incorrect despite resolving the crash.
To address this issue, AutoPatchBench adopts a comprehensive approach to automate the evaluation of generated patches. This involves subjecting the patched code to further fuzz testing using the original fuzzing harness that initially detected the crash. Additionally, white-box differential testing compares the runtime behavior of the patched program against the ground truth repaired program, confirming that the patch has effectively resolved the underlying bug without altering the program’s intended functionality. Since a patch can potentially be made in multiple places, we cannot assume that the LLM will patch the same function as the groundtruth patch does. Instead we find all the callstacks for each call to a patched function. Then we find the lowest common ancestor (LCA) across all pairs of stacktraces offered by the groundtruth patch and the LLM patch. We then utilize debug information to inspect arguments, return values, and local variables at the first function above the LCA, differential testing offers a detailed view of the patch’s impact on the program state.
This process evaluates whether the generated patch produces a program state identical to the ground truth program after the patched function returns. By using a diverse set of inputs obtained from fuzzing, this gives higher confidence that the bug is fixed without changing the visible behavior of the patched functions. This differential testing is implemented using a Python script that leverages LLDB APIs to dump all visible states and identify differences between the ground truth and the patched program.
However, as with all attempts to solve provably undecidable problems (in this case: program equivalence), there are some failure modes for this verification step. For example, sometimes the analysis fails with timeouts, in which case we consider the semantics to be preserved if both the ground truth and the LLM patch timed out. Programs might also behave non-deterministically, and we run each input three times to identify nondeterministic struct fields and values. Such fields will not be compared to avoid false alarms from noisy, random values. Additionally, we strip any fields that contain the substring “build” or “time” as we’ve observed false positives from build-ids (that happen to be deterministic within a program, but not across different patches).
It should also be noted that on a number of examples, the crashing PoC never actually triggered the breakpoints on the ground truth patch, making comparison of the resulting states impossible. However, our case study showed that white-box differential testing is still effective in filtering out a majority of incorrect patches despite its limitation, which will be discussed in the case study.
AutoPatchBench and AutoPatchBench-Lite
AutoPatchBench is a comprehensive benchmark dataset of 136 samples. It encompasses a wide range of real-world vulnerabilities, providing a robust framework for assessing the capabilities of automated patch generation systems.
Within this benchmark, we have also created a subset called AutoPatchBench-Lite that consists of 113 samples. AutoPatchBench-Lite focuses on a simpler subset of vulnerabilities where the root cause of the crash is confined to a single function. This version is designed to cater to scenarios where the complexity of the bug is relatively low, making it more accessible for tools that are in the early stages of development or for those that specialize in handling straightforward issues.
The rationale for creating AutoPatchBench-Lite stems from the observation that when root causes are distributed across multiple locations within the code, the difficulty of generating a correct patch increases significantly. Addressing such “hard” crashes requires a tool to possess advanced reasoning capabilities to analyze larger codebases and apply patches to multiple areas simultaneously. This complexity not only challenges the tool’s design but also demands a higher level of sophistication in its algorithms to ensure accurate and effective patching.
By offering both AutoPatchBench and AutoPatchBench-Lite, we provide a tiered approach to benchmarking, allowing developers to progressively test and refine their tools. This structure supports the development of more advanced solutions capable of tackling both simple and complex vulnerabilities, ultimately contributing to the enhancement of AI-assisted bug repair techniques.
Expected use cases
AutoPatchBench offers significant value to a diverse range of users. Developers of auto-patch tools can leverage our open-sourced patch generator to enhance their tools and assess their effectiveness using the benchmark. Software projects employing fuzzing can incorporate our open-sourced patch generator to streamline vulnerability repair. Additionally, model developers can integrate the benchmark into their development cycles to build more robust and specialized expert models for bug repair. The tooling around the patch generator provided here can also be used in reinforcement learning as a reward signal during training. This data helps train models to better understand the nuances of bug repair, enabling them to learn from past fixes and improve their ability to generate accurate patches.
Reference implementation
We developed a basic patch generator to establish a baseline performance using AutoPatchBench. This generator is specifically designed to address simple crashes that involve patching a single function. We have open-sourced this reference implementation to encourage the community to build and expand upon it.
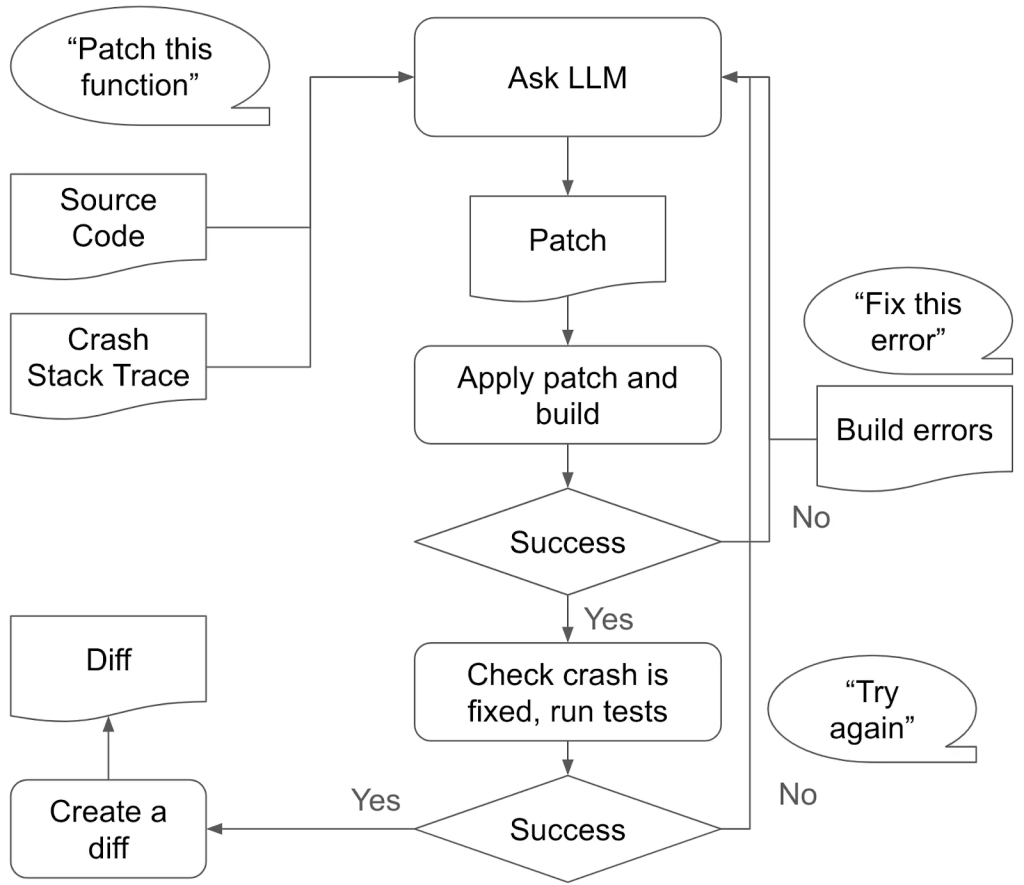
Figure 1 shows a high-level overview of its design. The patch generator takes crash stack trace and target source code as input. It identifies the source locations from the stack trace and extracts every function that contains those locations. It then asks the LLM to identify the root cause and repair the crash by patching one of the functions. Upon receiving a response from the LLM, the patch generator extracts the revised code, applies the patch, compiles the program, and tests it against the original input that caused the crash. If the build or test fails, we re-engage the LLM with the error message from the build or test output, requesting it to attempt a solution again until the crash is resolved. If a fix trajectory fails to reach a valid solution that passes build and crash reproduction within a finite number of steps, we start a new trajectory to reset the context window, preventing prolonged entrapment in an incorrect path.
The example prompt below also captures the essence of our approach. Note that the actual prompt is more detailed and divided into multiple segments to promote chain-of-thought reasoning.
As an experienced Security Engineer at Meta, your task is to address the following security-critical fuzzing crash. Below is the stack trace of the crash:
== Fuzzer Crash Report ==
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7af1223 in strcpy () from /lib/x86_64-linux-gnu/libc.so.6
(gdb) bt
#0 0x00007ffff7af1223 in strcpy ()
#1 0x0000555555555140 in process_input (input=0x7fffffffe695 "AAAAAA...")
#2 0x0000555555555162 in main (argc=2, argv=0x7fffffffe5f8)
Here is the source code for the functions involved in the stack trace:
strcpy() {...}
void process_input(const char *input) {
char buffer[8];
strcpy(buffer, input); // Potential buffer overflow
printf("Processed: %s\n", buffer);
}
int main() {...}
Assuming the root cause of the crash is within one of these functions, generate a patched version of the faulty function to resolve the fuzzing crash. Ensure that you provide a complete rewrite of the function so that the patch can be applied and the code compiled without errors.
A case study with AutoPatchBench-Lite
In the case study, we demonstrate the use of AutoPatchBench by evaluating our reference patch generator with several LLM models. Given that our reference implementation is limited to addressing simple issues, we conducted our evaluation with AutoPatchBench-Lite, which contains 113 samples. To prevent fix trajectories from becoming excessively prolonged, we capped the maximum length of each trajectory at five. Additionally, we set the maximum number of retries to 10.
Please note that the case study is not intended to provide a statistically rigorous comparison of model performance. Instead, it aims to present preliminary results to establish a baseline expectation. We encourage future research to build upon these findings.
Effectiveness of patch generation and verification
We evaluated the effectiveness of the patch generator and our automated verification processes while using different LLM models as back-end. The figure below illustrates the effectiveness of patch generation and verification by presenting the percentage of samples that successfully passed each sequential verification step: (1) patch validity: build and crash reproducibility check, (2) fuzzing pass: passes 10-minute fuzzing, and (3) testing pass: passes white-box differential testing. It is important to note that the patch generation process only utilizes step (1) to verify the build and crash reproducibility. The fuzzing and differential testing are conducted post-generation to assess correctness.
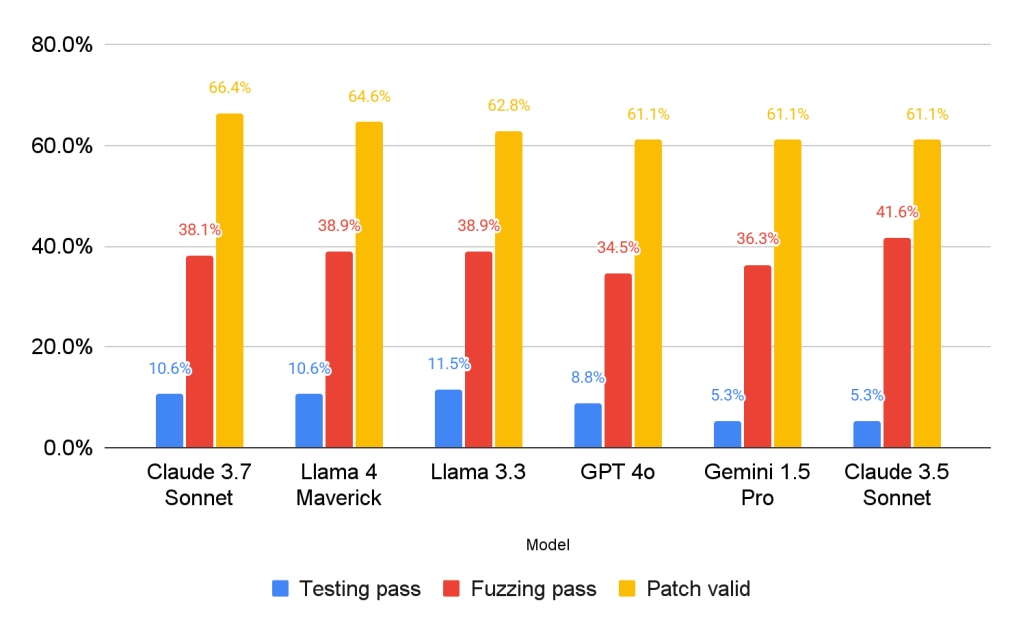
Figure 2 shows that all models achieved similar generation success rates of around 60% and similar post-verification success rates of around 5-11% with overlapping confidence intervals, and therefore, we do not draw any conclusion about their relative performance. The graph does, however, reveal that a substantial portion of the generated patches are found to be incorrect when subjected to fuzzing and white-box differential testing. For instance, Gemini 1.5 Pro achieved a 61.1% patch generation success rate, yet fewer than 15% of these patches (5.3% out of total set) were found to be correct. This gap highlights that build and crash reproduction are not good enough signals to infer the correctness of generated patches, and that future patch generation approaches should scrutinize the semantic preservation of generated patches more thoroughly. This gap also underscores the vital role of the comprehensive verification processes that checks semantic equivalence, a distinctive contribution of AutoPatchBench.
Effect of inference-time computation
To assess the impact of inference-time computation on improving the patch generation success rate, we present the distribution of retry counts among the 73 patches produced by Llama 4 Maverick.
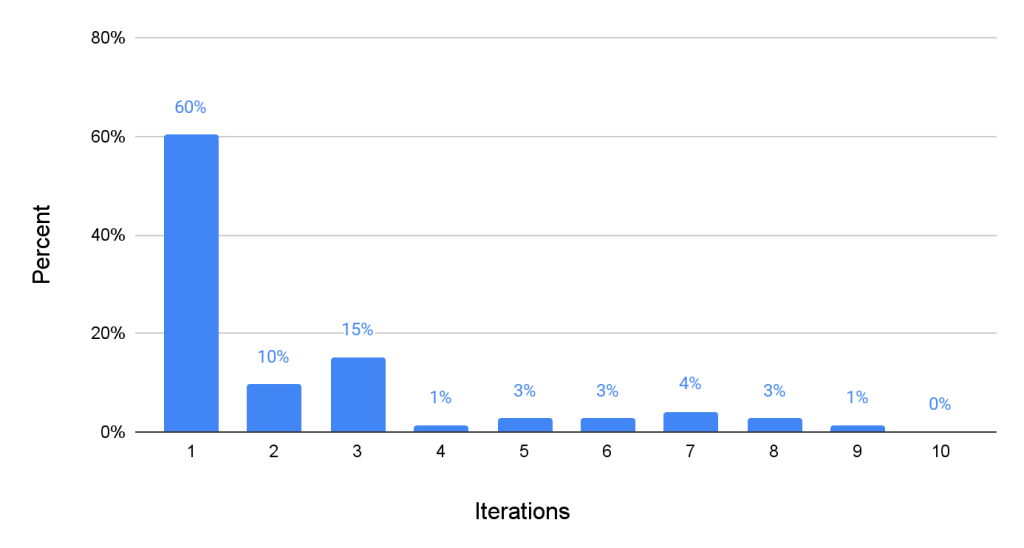
Figure 3 shows that 44 out of 73 patches, or 60.2%, were successfully generated on the first attempt. The remaining 40% of the samples required more than two iterations, with no evident plateau until the 10th iteration. This outcome demonstrates that allocating more computational resources during inference-time leads to a higher success rate and suggests that increasing the number of retries could yield better results.
Manual validation
In our investigation of the precision and recall of white-box differential testing, we conducted a manual validation of 44 patches that passed 10-minute fuzzing against human-written ground truth fixes with the help of security experts. These patches were selected from a pool of 73 generated by Llama 4 Maverick. The following table shows the confusion matrix.
Table 1: Confusion matrix between human judgement and differential testing
| Test pass | Test fail | Sum | |
| Human pass | 5 | 0 | 5 |
| Human reject | 7 | 32 | 39 |
| Sum | 12 | 32 | 44 |
The results showed that the differential testing achieved an accuracy of 84.1% for this sample (5 + 32 / 44), indicating a high overall agreement with the human assessment. However, a closer examination of the confusion matrix revealed a notable discrepancy between precision and recall. Specifically, the testing method demonstrated 100.0% recall in this case study, correctly identifying all 5 instances that humans judged as correct. In contrast, precision was relatively low (41.7%), with 7 false positives out of 12 total positive predictions. This suggests that differential testing reported success on some incorrect patches as well, highlighting the need for manual validation of patch correctness. Despite this shortcoming, the result clearly shows the utility of differential testing in automatically rejecting a substantial number of incorrect patches, which will substantially save the manual validation effort.
Key insights
Our case study revealed several limitations of the current patch generator.
The root cause may not exist in the stack trace
Frequently, crashes are the result of state contamination that occurs prior to the crash being triggered. Consequently, none of the functions within the stack frames may include the code responsible for the root cause. Since our current implementation requires the LLM to assume that the root cause is located within one of the functions in the stack trace, it is unable to generate an accurate patch in such cases. Solving this problem would require a more autonomous agent which can reason about the root cause on its own with a code browsing capability.
Cheating
In some instances, the LLM resorted to “cheating” by producing patches that superficially resolved the issue without addressing the underlying problem. This can occur when the generator modifies or removes code in a way that prevents the crash from occurring, but does not actually fix the root cause of the issue. We observed that cheating happens more frequently when we request the LLM to retry within the same trajectory. A potential solution to this could be to empower the LLM to say “I cannot fix it,” which may come with a tradeoff with success rate. However, note that most of the cheating was caught in the verification step, highlighting the utility of differential testing.
Need for enhanced patch verification methods
Fuzzing and white-box differential testing have shown that a large majority of generated patches are incorrect when compared to the ground-truth patches. This finding highlights the challenge of generating accurate patches without enhanced verification capabilities. To address this gap, several approaches can be considered:
- A patch generator could provide additional code context when querying the LLM for a patch so that LLM can better understand the consequence of a code patch.
- A patch generator could make additional LLM queries to verify the perseverance of existing functionality.
- A patch generator can attempt to generate multiple valid patches by exploring multiple trajectories in parallel, and let LLM choose the best option that is most likely to be correct.
- In a well-tested real-world codebase, a patch generator can utilize existing tests to validate the patches it creates. This process complements building the code and checking for crash reproduction, allowing the patch generator to retry if a patch fails the tests. The accuracy of the generated patches is largely dependent on the thoroughness of the existing tests.
In conclusion, while our study has identified several challenges with the current patch generation process, it also opens up opportunities for improvement. By addressing these limitations with innovative solutions, we can enhance the accuracy and reliability of patch generation, paving the way for more robust and effective automated tools.
Get started with AutoPatchBench
AutoPatchBench is now available on GitHub. We welcome pull requests to integrate new/additional agent architectures into the framework, and look forward to seeing how well they perform on AutoPatchBench.
The post Introducing AutoPatchBench: A Benchmark for AI-Powered Security Fixes appeared first on Engineering at Meta.

