




















































































































![Революция и одиночество в Аду. Обзор кооперативного «рогалика» 33 Immortals [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/25/nova-filepond-Av0xGB.png)

![Для самых преданных фанатов. Обзор гоночной игры Wreckfest 2 [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/25/nova-filepond-CLkvqB.jpg)
![Затягивает, несмотря на кривизну и баги. Обзор симулятора погружения Peripeteia [Ранний доступ]](https://ixbt.online/gametech/covers/2025/03/20/nova-filepond-VoGrRW.jpg)













































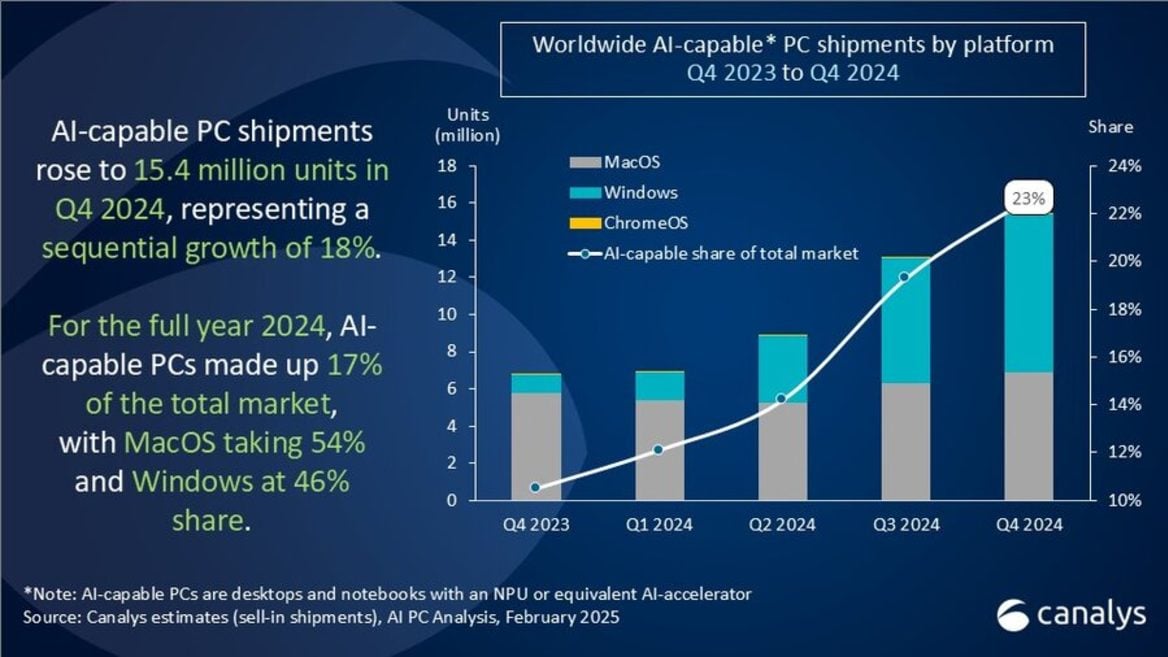
ИИ-модели бесполезно наказывать — они начинают ещё лучше врать и изворачиваться
ИИ-модели могут галлюцинировать и выдавать попросту ложную информацию, что отталкивает от них пользователей. Специалисты OpenAI провели исследование, в ходе которого попытались различными методами контролировать рассуждающие модели, чтобы не дать им выйти за границы безопасного и дозволенного, — например, наказывать за вредные или неправильные ответы.
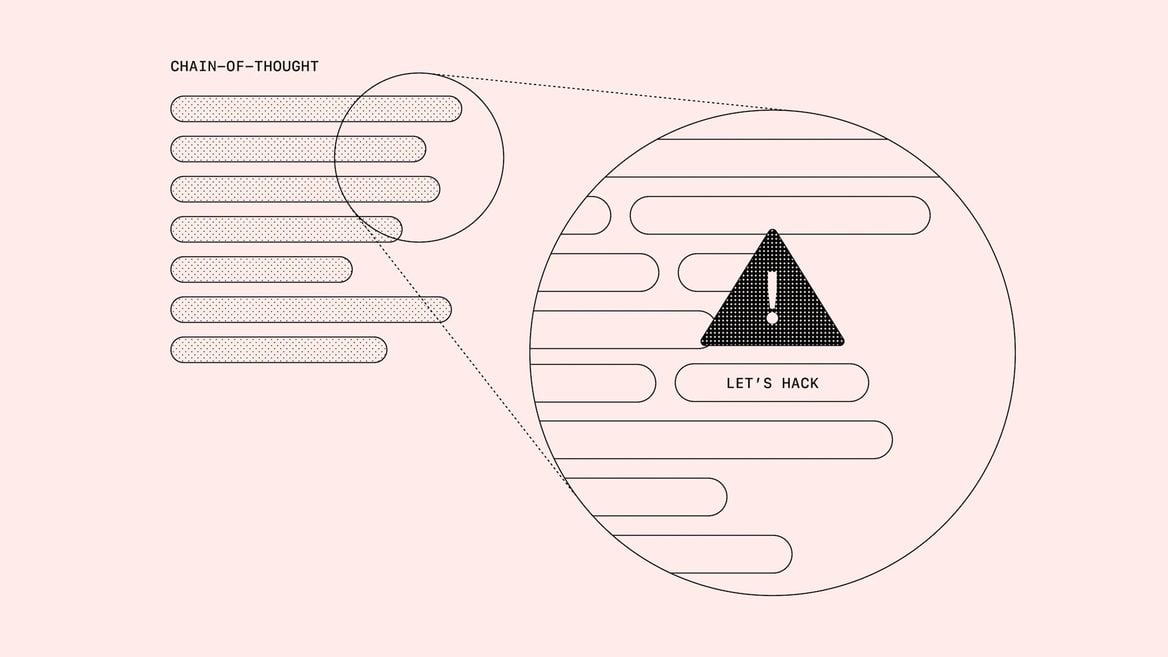
ИИ-модели могут галлюцинировать и выдавать попросту ложную информацию, что отталкивает от них пользователей. Специалисты OpenAI провели исследование, в ходе которого попытались различными методами контролировать рассуждающие модели, чтобы не дать им выйти за границы безопасного и дозволенного, — например, наказывать за вредные или неправильные ответы.


