
































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)












![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































































Understanding Terraform Lifecycle Management: A Comprehensive Guide
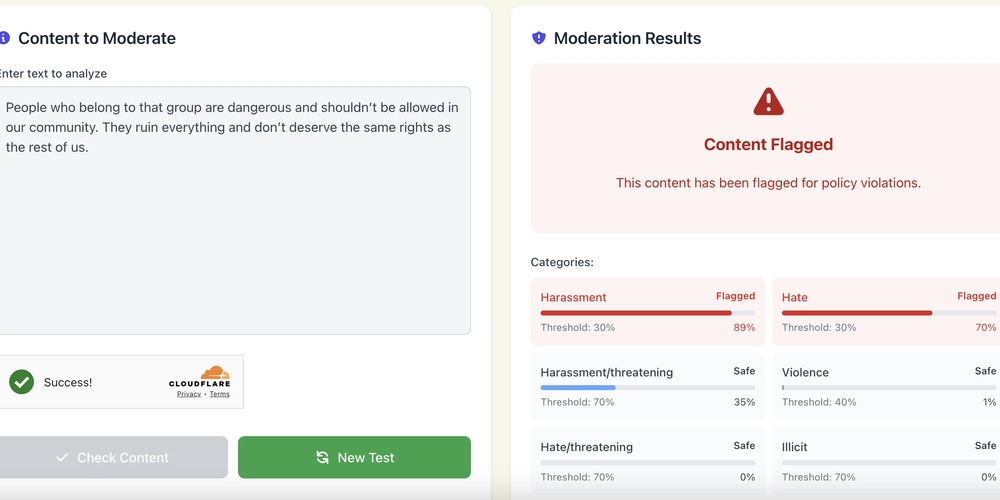
In the world of Infrastructure as Code (IaC), Terraform has emerged as one of the most powerful tools for managing cloud resources. However, as infrastructure grows in complexity, managing how resources are created, updated, and destroyed becomes increasingly challenging. This is where Terraform's lifecycle management features come into play. What is Terraform Lifecycle Management? Lifecycle management in Terraform refers to a set of directives that control how Terraform handles resource creation, updates, and destruction during the deployment process. These directives give you fine-grained control over resource behavior, helping you manage complex dependencies and avoid unintended changes or downtime. The lifecycle Block The lifecycle block is added to resource blocks in your Terraform configuration and supports several arguments that modify Terraform's default behavior: resource "aws_instance" "example" { ami = "ami-0c55b159cbfafe1f0" instance_type = "t2.micro" lifecycle { create_before_destroy = true prevent_destroy = true ignore_changes = [ tags, ami ] replace_triggered_by = [ aws_security_group.example.id ] } } Let's explore each of these lifecycle arguments in detail. 1. create_before_destroy When set to true, this argument instructs Terraform to create a new resource before destroying the old one. This is particularly useful for scenarios where you want to minimize downtime during infrastructure updates. Use Cases: Zero-downtime deployments: Create a new instance of a resource before taking down the old one. Blue-green deployments: Set up a new environment before transitioning traffic from the old one. Resource dependencies: When a resource has many dependent resources, creating the new version first helps maintain those dependencies. Example: resource "aws_instance" "web" { ami = "ami-0c55b159cbfafe1f0" instance_type = "t2.micro" lifecycle { create_before_destroy = true } } 2. prevent_destroy This argument, when set to true, prevents accidental destruction of critical resources. If someone runs terraform destroy or attempts to change an attribute that requires resource recreation, Terraform will raise an error. Use Cases: Critical production databases: Prevent accidental deletion of databases containing important data. Storage resources: Protect storage accounts or buckets that contain critical information. Shared infrastructure: Safeguard resources that are shared across multiple applications. Example: resource "aws_db_instance" "production" { allocated_storage = 100 engine = "mysql" instance_class = "db.m5.large" lifecycle { prevent_destroy = true } } 3. ignore_changes This powerful argument tells Terraform to ignore changes to specific attributes during updates. This is especially useful when external systems modify your resources, or when you have attributes that change frequently but don't want to trigger updates. Use Cases: Auto-scaling resources: Ignore changes to instance counts when auto-scaling adjusts the number. External tagging: Ignore tags that might be added by other automation or monitoring tools. Generated values: Ignore fields that are automatically generated or modified by the provider. Example: resource "aws_autoscaling_group" "example" { name = "example-asg" max_size = 10 min_size = 2 desired_capacity = 2 lifecycle { ignore_changes = [ desired_capacity ] } } In this example, Terraform will not attempt to reset the desired_capacity if it changes due to auto-scaling events. 4. replace_triggered_by Added in Terraform 1.2, this argument forces a resource to be replaced when a specified resource or attribute changes, even if the resource itself doesn't need replacement. Use Cases: Dependent configurations: Force recreation of a resource when its upstream dependency changes significantly. Configuration invalidation: Ensure proper initialization when backing services are replaced. Breaking changes: Handle scenarios where changes in dependent resources break functionality. Example: resource "aws_lambda_function" "example" { function_name = "example-function" role = aws_iam_role.lambda_exec.arn handler = "index.handler" lifecycle { replace_triggered_by = [ aws_s3_bucket.lambda_bucket.id ] } } This configuration will recreate the Lambda function whenever the S3 bucket that stores its code changes, ensuring that the function picks up the new code correctly. Real-World Scenarios Let's explore some real-world scenarios where these lifecycle directives are particularly useful: Scenario 1: Database with Auto-Backup Tags Ima

In the world of Infrastructure as Code (IaC), Terraform has emerged as one of the most powerful tools for managing cloud resources. However, as infrastructure grows in complexity, managing how resources are created, updated, and destroyed becomes increasingly challenging. This is where Terraform's lifecycle management features come into play.
What is Terraform Lifecycle Management?
Lifecycle management in Terraform refers to a set of directives that control how Terraform handles resource creation, updates, and destruction during the deployment process. These directives give you fine-grained control over resource behavior, helping you manage complex dependencies and avoid unintended changes or downtime.
The lifecycle Block
The lifecycle block is added to resource blocks in your Terraform configuration and supports several arguments that modify Terraform's default behavior:
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
lifecycle {
create_before_destroy = true
prevent_destroy = true
ignore_changes = [
tags,
ami
]
replace_triggered_by = [
aws_security_group.example.id
]
}
}
Let's explore each of these lifecycle arguments in detail.
1. create_before_destroy
When set to true, this argument instructs Terraform to create a new resource before destroying the old one. This is particularly useful for scenarios where you want to minimize downtime during infrastructure updates.
Use Cases:
- Zero-downtime deployments: Create a new instance of a resource before taking down the old one.
- Blue-green deployments: Set up a new environment before transitioning traffic from the old one.
- Resource dependencies: When a resource has many dependent resources, creating the new version first helps maintain those dependencies.
Example:
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
lifecycle {
create_before_destroy = true
}
}
2. prevent_destroy
This argument, when set to true, prevents accidental destruction of critical resources. If someone runs terraform destroy or attempts to change an attribute that requires resource recreation, Terraform will raise an error.
Use Cases:
- Critical production databases: Prevent accidental deletion of databases containing important data.
- Storage resources: Protect storage accounts or buckets that contain critical information.
- Shared infrastructure: Safeguard resources that are shared across multiple applications.
Example:
resource "aws_db_instance" "production" {
allocated_storage = 100
engine = "mysql"
instance_class = "db.m5.large"
lifecycle {
prevent_destroy = true
}
}
3. ignore_changes
This powerful argument tells Terraform to ignore changes to specific attributes during updates. This is especially useful when external systems modify your resources, or when you have attributes that change frequently but don't want to trigger updates.
Use Cases:
- Auto-scaling resources: Ignore changes to instance counts when auto-scaling adjusts the number.
- External tagging: Ignore tags that might be added by other automation or monitoring tools.
- Generated values: Ignore fields that are automatically generated or modified by the provider.
Example:
resource "aws_autoscaling_group" "example" {
name = "example-asg"
max_size = 10
min_size = 2
desired_capacity = 2
lifecycle {
ignore_changes = [
desired_capacity
]
}
}
In this example, Terraform will not attempt to reset the desired_capacity if it changes due to auto-scaling events.
4. replace_triggered_by
Added in Terraform 1.2, this argument forces a resource to be replaced when a specified resource or attribute changes, even if the resource itself doesn't need replacement.
Use Cases:
- Dependent configurations: Force recreation of a resource when its upstream dependency changes significantly.
- Configuration invalidation: Ensure proper initialization when backing services are replaced.
- Breaking changes: Handle scenarios where changes in dependent resources break functionality.
Example:
resource "aws_lambda_function" "example" {
function_name = "example-function"
role = aws_iam_role.lambda_exec.arn
handler = "index.handler"
lifecycle {
replace_triggered_by = [
aws_s3_bucket.lambda_bucket.id
]
}
}
This configuration will recreate the Lambda function whenever the S3 bucket that stores its code changes, ensuring that the function picks up the new code correctly.
Real-World Scenarios
Let's explore some real-world scenarios where these lifecycle directives are particularly useful:
Scenario 1: Database with Auto-Backup Tags
Imagine you have a database resource that gets automatically tagged with backup information:
resource "aws_db_instance" "database" {
identifier = "production-db"
allocated_storage = 100
engine = "postgres"
engine_version = "13.4"
lifecycle {
prevent_destroy = true
ignore_changes = [
tags["LastBackupTime"],
tags["BackupStatus"]
]
}
}
This configuration prevents accidental destruction of the database and ignores the backup-related tags that are updated by an external backup system.
Scenario 2: Web Application with Zero-Downtime Updates
For a web application that needs zero downtime during updates:
resource "aws_elastic_beanstalk_environment" "web_app" {
name = "production-web-app"
application = aws_elastic_beanstalk_application.web_app.name
solution_stack_name = "64bit Amazon Linux 2 v3.4.1 running Node.js 14"
lifecycle {
create_before_destroy = true
replace_triggered_by = [
aws_elastic_beanstalk_application_version.web_app.id
]
}
}
This ensures that a new environment is created before destroying the old one, and that the environment is replaced whenever a new application version is deployed.
Scenario 3: Auto-Scaling Group with External Scaling
For an auto-scaling group managed by an external scaling policy:
resource "aws_autoscaling_group" "web_tier" {
name = "web-tier"
launch_configuration = aws_launch_configuration.web.id
min_size = 2
max_size = 10
desired_capacity = 2
lifecycle {
ignore_changes = [
desired_capacity
]
create_before_destroy = true
}
}
This configuration allows the auto-scaling group to scale up and down without Terraform trying to reset it back to the original desired capacity.
Best Practices for Terraform Lifecycle Management
Document your lifecycle decisions: Add comments explaining why certain lifecycle rules exist to help other team members understand your reasoning.
Use
prevent_destroyjudiciously: Apply this to truly critical resources but avoid overusing it, as it can complicate legitimate destruction needs.Be specific with
ignore_changes: Target only the attributes that need to be ignored rather than using wildcards, to maintain Terraform's ability to manage other attributes.Test lifecycle behaviors in lower environments: Before applying lifecycle rules to production, test them in development or staging environments to understand their effects.
Consider resource recreation impacts: When using
create_before_destroyorreplace_triggered_by, be aware of temporary resource duplication and potential cost implications.Combine lifecycle settings strategically: Different lifecycle settings can work together to create sophisticated resource management behaviors.
Cloud-Specific Considerations
Different cloud providers have unique characteristics that may influence how you use lifecycle settings:
AWS
- Resources like S3 buckets often need
prevent_destroydue to their global namespaces and data persistence. - Auto Scaling Groups benefit from
ignore_changesondesired_capacity.
Azure
- Resources with unique naming requirements need careful handling with
create_before_destroy. - Azure often modifies resource tags automatically, making
ignore_changeson tags valuable.
Google Cloud
- GCP resources often have auto-generated values that benefit from
ignore_changes. - Resources with many dependencies benefit from
create_before_destroy.
Conclusion
Terraform's lifecycle management features provide powerful tools for controlling how your infrastructure evolves over time. By understanding and strategically applying these directives, you can create more resilient, maintainable infrastructure deployments that handle changes gracefully.
Whether you're managing critical databases that must never be accidentally destroyed, handling resources modified by external systems, or ensuring zero-downtime deployments, Terraform's lifecycle block gives you the control you need to implement sophisticated infrastructure management strategies.
As your infrastructure grows in complexity, mastering these lifecycle features becomes increasingly valuable, allowing you to manage change with confidence and precision.






