
















![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)













![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)

























































































_Weyo_alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)


















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

























































































































![BPMN-procesmodellering [closed]](https://i.sstatic.net/l7l8q49F.png)
















































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






























































Communication-Efficient Learning of Deep Networks from Decentralized Data - By Alex Nguyen
The advent of communication-efficient learning of deep networks from decentralized data has revolutionized the way we train machine learning models, especially in scenarios where data privacy and network bandwidth are critical considerations. This approach, often realized through techniques like Federated Learning (FL), allows for the training of sophisticated deep networks without the need to centralize raw data, thereby reducing communication overhead significantly while respecting user privacy. By keeping data local on devices such as mobile phones or IoT systems, and only sharing model updates, models can be trained efficiently across a distributed network of devices. The concept not only addresses issues related to data privacy but also tackles the challenge of managing large volumes of data across numerous heterogeneous devices, making it a pivotal advancement in modern machine learning. Introduction to Communication-Efficient Learning of Deep Networks from Decentralized Data Communication-efficient learning of deep networks from decentralized data has emerged as a cornerstone in the field of machine learning, particularly with the rise of edge computing and the increasing importance of data privacy. This method fundamentally transforms how we approach model training by allowing for the aggregation of knowledge gleaned from multiple data sources without the necessity of centralizing the data itself. Such an approach not only enhances privacy and reduces communication overhead but also fosters a more scalable and inclusive learning environment. Overview of Communication-Efficient Learning Communication-efficient learning primarily focuses on reducing the amount of data transferred during the training process of deep neural networks. Traditional centralized learning requires all data to be pooled at a single location, which can be both impractical and inefficient due to privacy concerns and bandwidth limitations. In contrast, communication-efficient techniques like Federated Learning enable each device to process its local data and only share model updates, drastically reducing the data that needs to be transmitted across the network. This method also supports the training of large models across geographically dispersed devices, leveraging their combined computational power without compromising user privacy. By minimizing the data transfer, it not only conserves network resources but also makes training feasible in environments with limited connectivity or high latency. Definition and Importance of Decentralized Deep Network Training Decentralized deep network training refers to the process where multiple devices or nodes participate in training a collective model, but each keeps its data private and solely shares the results of its local computations. This is crucial in scenarios where data cannot legally or ethically be moved or shared, such as healthcare applications where patient confidentiality must be maintained, or in mobile environments where users' personal data should not leave their devices. The importance of this approach lies in its ability to harness the power of big data while safeguarding individual privacy. It enables organizations to train robust models on datasets that are otherwise unattainable due to regulatory constraints or logistical challenges. Moreover, it opens up possibilities for new types of applications that can leverage real-time data from edge devices, making it a transformative technology in the era of IoT and smart devices. Privacy Preservation by Keeping Raw Data Local A key advantage of communication-efficient learning is its inherent capability to preserve privacy. By training models locally on devices such as smartphones or IoT gadgets, raw data never leaves these devices. Only the model updates, which do not reveal specific details about the training data, are sent over the network. This approach counters potential data breaches and complies with stringent data protection regulations like GDPR, enabling industries such as finance and healthcare to utilize machine learning technologies securely. The privacy preservation aspect not only protects users but also builds trust in technology providers, encouraging broader adoption of innovative solutions powered by machine learning. It represents a significant shift towards a more ethical use of technology, ensuring that the benefits of AI can be realized without encroaching on individual rights. Reduction of Communication Overhead Compared to Centralized Training Compared to traditional centralized training where all data must be gathered in one location, communication-efficient methods significantly reduce the amount of data transmitted. This reduction in communication overhead is achieved by sending only model updates rather than entire datasets, which can lead to substantial savings in bandwidth and energy consumption. For instance, in scenarios involving millions of mobile devices
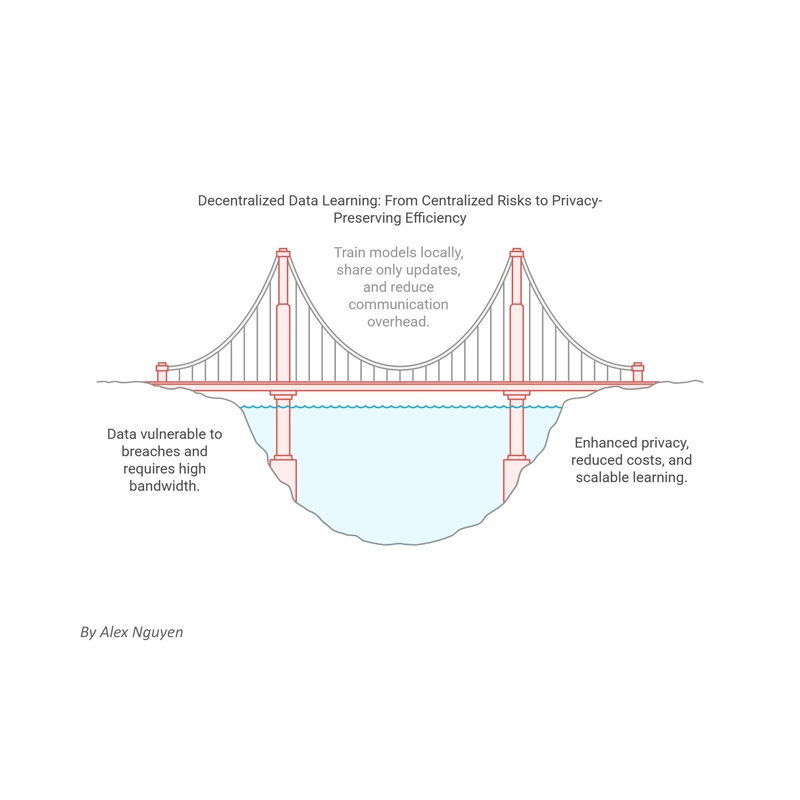
The advent of communication-efficient learning of deep networks from decentralized data has revolutionized the way we train machine learning models, especially in scenarios where data privacy and network bandwidth are critical considerations.
This approach, often realized through techniques like Federated Learning (FL), allows for the training of sophisticated deep networks without the need to centralize raw data, thereby reducing communication overhead significantly while respecting user privacy.
By keeping data local on devices such as mobile phones or IoT systems, and only sharing model updates, models can be trained efficiently across a distributed network of devices.
The concept not only addresses issues related to data privacy but also tackles the challenge of managing large volumes of data across numerous heterogeneous devices, making it a pivotal advancement in modern machine learning.
Introduction to Communication-Efficient Learning of Deep Networks from Decentralized Data
Communication-efficient learning of deep networks from decentralized data has emerged as a cornerstone in the field of machine learning, particularly with the rise of edge computing and the increasing importance of data privacy.
This method fundamentally transforms how we approach model training by allowing for the aggregation of knowledge gleaned from multiple data sources without the necessity of centralizing the data itself.
Such an approach not only enhances privacy and reduces communication overhead but also fosters a more scalable and inclusive learning environment.
Overview of Communication-Efficient Learning
Communication-efficient learning primarily focuses on reducing the amount of data transferred during the training process of deep neural networks.
Traditional centralized learning requires all data to be pooled at a single location, which can be both impractical and inefficient due to privacy concerns and bandwidth limitations.
In contrast, communication-efficient techniques like Federated Learning enable each device to process its local data and only share model updates, drastically reducing the data that needs to be transmitted across the network.
This method also supports the training of large models across geographically dispersed devices, leveraging their combined computational power without compromising user privacy.
By minimizing the data transfer, it not only conserves network resources but also makes training feasible in environments with limited connectivity or high latency.
Definition and Importance of Decentralized Deep Network Training
Decentralized deep network training refers to the process where multiple devices or nodes participate in training a collective model, but each keeps its data private and solely shares the results of its local computations.
This is crucial in scenarios where data cannot legally or ethically be moved or shared, such as healthcare applications where patient confidentiality must be maintained, or in mobile environments where users' personal data should not leave their devices.
The importance of this approach lies in its ability to harness the power of big data while safeguarding individual privacy. It enables organizations to train robust models on datasets that are otherwise unattainable due to regulatory constraints or logistical challenges.
Moreover, it opens up possibilities for new types of applications that can leverage real-time data from edge devices, making it a transformative technology in the era of IoT and smart devices.
Privacy Preservation by Keeping Raw Data Local
A key advantage of communication-efficient learning is its inherent capability to preserve privacy.
By training models locally on devices such as smartphones or IoT gadgets, raw data never leaves these devices.
Only the model updates, which do not reveal specific details about the training data, are sent over the network.
This approach counters potential data breaches and complies with stringent data protection regulations like GDPR, enabling industries such as finance and healthcare to utilize machine learning technologies securely.
The privacy preservation aspect not only protects users but also builds trust in technology providers, encouraging broader adoption of innovative solutions powered by machine learning.
It represents a significant shift towards a more ethical use of technology, ensuring that the benefits of AI can be realized without encroaching on individual rights.
Reduction of Communication Overhead Compared to Centralized Training
Compared to traditional centralized training where all data must be gathered in one location, communication-efficient methods significantly reduce the amount of data transmitted.
This reduction in communication overhead is achieved by sending only model updates rather than entire datasets, which can lead to substantial savings in bandwidth and energy consumption.
For instance, in scenarios involving millions of mobile devices contributing to a model's training, the cumulative effect of reduced communication can result in significant performance improvements and cost savings.
It also makes training possible in regions with poor internet connectivity, thus democratizing access to advanced AI technologies.
Historical Context and Motivation
The motivation for developing communication-efficient learning stems from the growing complexity of data environments and the increasing demand for privacy-aware technologies.
The introduction of Federated Learning by McMahan et al. in 2016/2017 marked a pivotal moment, demonstrating that it was possible to reduce communication rounds dramatically (up to 10-100 times fewer than traditional synchronized Stochastic Gradient Descent) while still achieving effective model training.
This breakthrough opened up new research avenues focused on handling unbalanced and non-IID data distributions at scale, which are common in real-world settings.
Subsequent studies have built upon this foundation, exploring ways to enhance the efficiency, robustness, and applicability of these methods in various domains.
Emergence of Federated Learning (FL)
Federated Learning quickly became a focal point for research in communication-efficient learning due to its promise of privacy-preserving, scalable model training.
As a pioneering technique, FL not only addressed the immediate need for reducing communication overhead but also set the stage for further innovations in decentralized training methodologies.
The emergence of FL was driven by the need to leverage the vast amounts of data generated at the edge without compromising user privacy.
It represented a paradigm shift in how machine learning could be applied in real-world settings, influencing subsequent developments in the field and laying the groundwork for the next generation of distributed AI systems.
The Dramatic Communication Reduction
One of the most compelling aspects of FL is its ability to train models with far fewer communication rounds compared to traditional methods.
This dramatic reduction, often cited as being 10 to 100 times less, directly translates into lower operational costs and faster model deployment times.
For businesses looking to implement AI solutions, this efficiency can be a deciding factor in adopting federated approaches over conventional centralized training.
The reduction in communication frequency does not come at the expense of model quality, as demonstrated in various studies.
Instead, it highlights the potential of FL to revolutionize how AI models are developed and deployed in practical scenarios, particularly where real-time decision-making is required.
Addressing Unbalanced and Non-IID Data Distributions at Scale
Real-world data often exhibits imbalances and non-IID (independent and identically distributed) characteristics, which pose significant challenges for traditional learning algorithms.
FL, with its decentralized nature, offers a promising solution by inherently accommodating such data distributions.
By training models on diverse datasets from multiple devices and then aggregating these updates, FL can improve the generalization and performance of models on varied inputs.
This capability is crucial for applications that require robust performance across different contexts and user demographics, making FL a key enabler for building truly inclusive AI systems.
1. Fundamentals of Federated Learning (FL)
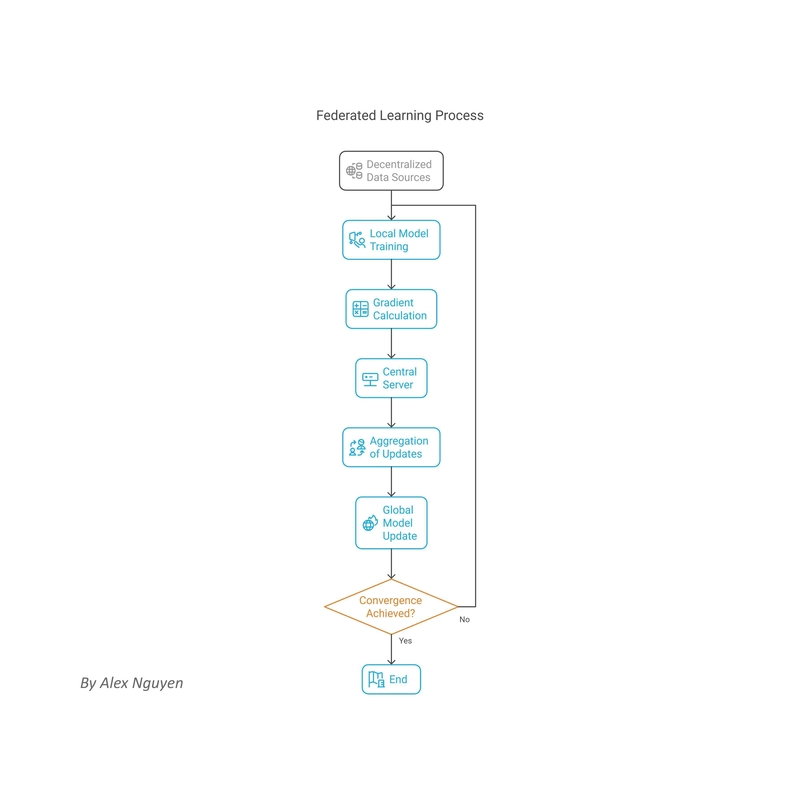
Federated Learning stands as a revolutionary approach to training deep networks across decentralized data sources.
It embodies a shift towards privacy-preserving machine learning by allowing multiple devices to collaboratively train a shared model while keeping all data localized.
This method not only addresses the significant challenges of data privacy but also tackles the issue of communication efficiency, making it a fundamental tool for modern AI applications.
Core Concept and Rationale
At its core, FL operates on the principle of training a global model by aggregating locally computed updates from many clients.
This decentralized approach ensures that sensitive data remains on the devices that generated it, enhancing privacy.
By transmitting only model updates instead of raw data, FL achieves efficient bandwidth usage, which is particularly advantageous when dealing with large-scale deployments on heterogeneous edge devices.
The rationale behind FL is twofold: firstly, to protect user privacy by avoiding data centralization, and secondly, to optimize the utilization of computational resources spread across numerous devices.
This method leverages the ubiquity of edge devices, turning them into active participants in the learning process rather than mere data generators.
Training a Global Model by Aggregating Locally Computed Updates
FL works by iteratively refining a global model through updates provided by participating devices.
Each device trains the model on its local data, calculates the gradient, and sends only these updates back to a central server, where they are aggregated to form a new version of the global model.
This process repeats until the model converges to a satisfactory level of performance.
This aggregation step is crucial as it synthesizes the learning from all participating devices without exposing any individual's data.
It also allows the model to benefit from diverse datasets, potentially improving its generalizability and robustness.
Ensuring Data Privacy and Efficient Bandwidth Usage
By design, FL ensures that raw data never leaves the originating device, thereby providing a strong layer of privacy protection.
This is particularly important in sectors like healthcare, where data sensitivity is paramount.
Moreover, since only model updates are transmitted, the bandwidth required for training is significantly reduced compared to traditional methods that necessitate transferring entire datasets.
This efficient use of bandwidth not only makes FL feasible in environments with limited connectivity but also decreases the environmental impact of data transmission, aligning well with sustainable computing initiatives.
Scalability on Heterogeneous Edge Devices
One of the standout features of FL is its ability to scale across a wide range of devices with varying computational capabilities.
From powerful servers to resource-constrained smartphones, FL can harness the collective power of these devices to train complex models.
This scalability is achieved through adaptive training strategies that consider the hardware limitations of each device, allowing for flexible participation schedules and workload distributions.
As a result, FL can support large-scale applications that would be infeasible under traditional centralized approaches.
Key Motivations
The motivations driving the development and adoption of FL are deeply rooted in the evolving landscape of data privacy, communication efficiency, and system scalability.
Data Privacy: Sensitive User Data Stays On-Device
In an era where data breaches are increasingly common and public concern over privacy is growing, FL offers a compelling solution.
By ensuring that raw data stays on the user’s device, FL aligns with modern privacy regulations and consumer expectations, making it an attractive option for organizations keen on building trust with their users.
This focus on privacy not only safeguards individual rights but also opens up new opportunities for using personal data in innovative ways that were previously restricted due to privacy concerns.
Communication Efficiency: Transmitting Model Parameters Rather Than Raw Data
The efficiency of FL in terms of communication is one of its most transformative aspects.
By sending only model parameters rather than the actual data, FL drastically cuts down on the amount of data that needs to be transferred.
This is particularly beneficial in scenarios where network connectivity is a bottleneck, such as in remote areas or developing regions.
The reduction in data transmission not only speeds up the training process but also lowers the operational costs associated with data movement, making FL a financially viable option for many organizations.
System Scalability: Enabling Large-Scale Learning Across Numerous Devices
FL's ability to scale across millions of devices makes it a powerful tool for large-scale learning tasks.
Whether it's training a language model on billions of sentences or a healthcare model on data from thousands of hospitals, FL can handle the scale and diversity of modern datasets.
This scalability extends beyond just the number of devices; it also encompasses the ability to integrate new types of data and learning scenarios as they emerge, ensuring that FL remains at the forefront of machine learning technology.
2. The Federated Averaging (FedAvg) Algorithm
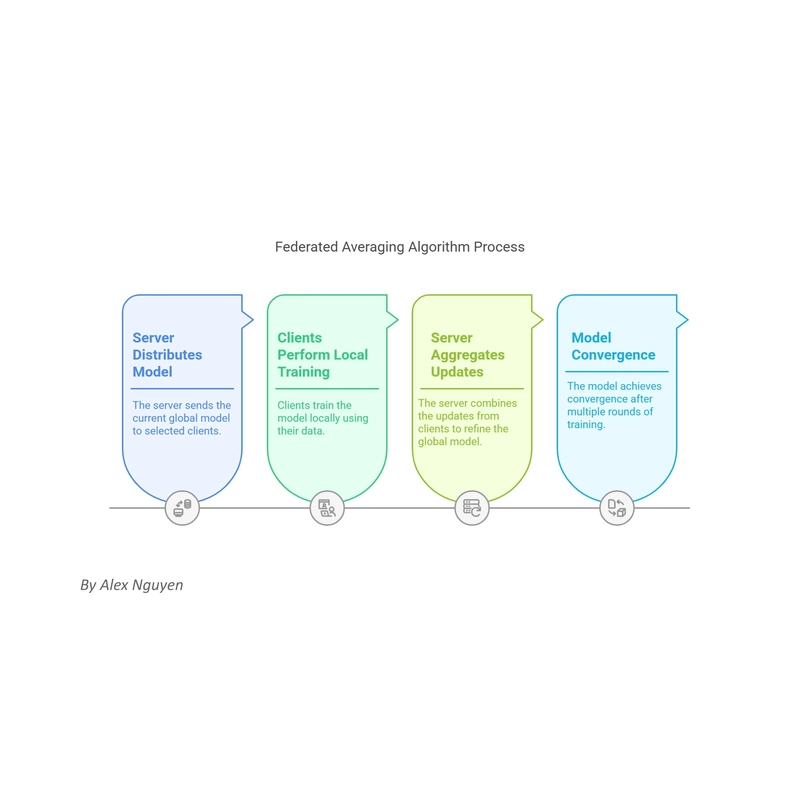
The Federated Averaging (FedAvg) algorithm is a cornerstone of Federated Learning, offering a straightforward yet powerful approach to training models across decentralized data sources.
Introduced by McMahan et al., FedAvg has become synonymous with communication-efficient learning due to its ability to reduce the number of communication rounds required for training, while maintaining model accuracy.
This section delves into the mechanics of the FedAvg algorithm, its key innovations, and the benefits it brings to the field of deep learning from decentralized data.
Algorithm Overview
FedAvg operates through a series of communication rounds between a central server and participating clients.
The process begins with the server distributing the current global model weights to a subset of clients, followed by local training on each client's data, and culminated by aggregating these local updates to refine the global model.
Client Selection: Random Selection of a Fraction C of Clients in Each Communication Round
The algorithm starts by randomly selecting a fraction C of available clients to participate in each round.
This random selection helps ensure fair representation across different data distributions and prevents over-reliance on any single client or subset of clients.
The choice of C balances participation against communication overhead, with larger values of C potentially leading to more robust models at the cost of increased communication.
Local Training: Each Selected Client Performs E Epochs of SGD with Batch Size B on Its Local Data
Once selected, each client performs local training on its own dataset.
This involves running E epochs of Stochastic Gradient Descent (SGD) with a specified batch size B.
The number of epochs (E) and the batch size (B) are critical hyperparameters that influence the trade-off between local computation and communication efficiency.
Larger values of E increase the amount of local computation but decrease the frequency of needed communication.
Server Aggregation: Weighted Model Update Computed as:
The final step in each round is the aggregation of updates from participating clients.
The server computes a weighted average of the updated model parameters from all clients, with weights proportional to the number of data samples each client used in training.This aggregation is formalized as:
[ w_ n_k ), ( w_t^k ) represents the local update from client k at round t, ( n_k ) is the number of data samples used by client k, and K is the number of participating clients.
Key Innovations and Benefits
FedAvg introduced several innovations that have had a profound impact on the field of Federated Learning and communication-efficient learning of deep networks.
Significant Reduction in Communication Rounds (10-100× Fewer Rounds) Due to Increased Local Computation
One of the most significant contributions of FedAvg is its ability to reduce the number of communication rounds required for training by leveraging increased local computation.
By allowing clients to perform multiple epochs of local training before communicating updates, FedAvg can achieve convergence with far fewer interactions between the server and clients compared to traditional synchronous SGD.
This reduction can be as dramatic as 10 to 100 times fewer rounds, substantially decreasing the communication overhead.
Robustness to Non-IID Data Distributions (Demonstrated on Tasks Like MNIST and Language Modeling)
Another key innovation of FedAvg is its demonstrated robustness to non-IID (non-independent and identically distributed) data distributions.
Many real-world scenarios involve datasets that are not uniformly distributed across clients, which can pose challenges for centralized learning methods.
FedAvg's approach of averaging local updates from diverse clients helps mitigate these issues, as evidenced by successful applications on tasks ranging from image recognition on MNIST to language modeling.
Scalability Across Devices with Uneven Data Distributions
Finally, FedAvg showcases remarkable scalability across a wide range of devices, even when these devices possess uneven data distributions.
By allowing each device to contribute according to its capacity and data availability, FedAvg can effectively train models across millions of devices, from smartphones to IoT sensors.
This scalability makes it an ideal solution for large-scale applications that require integrating data from varied sources.
3. Experimental Validation and Key Findings
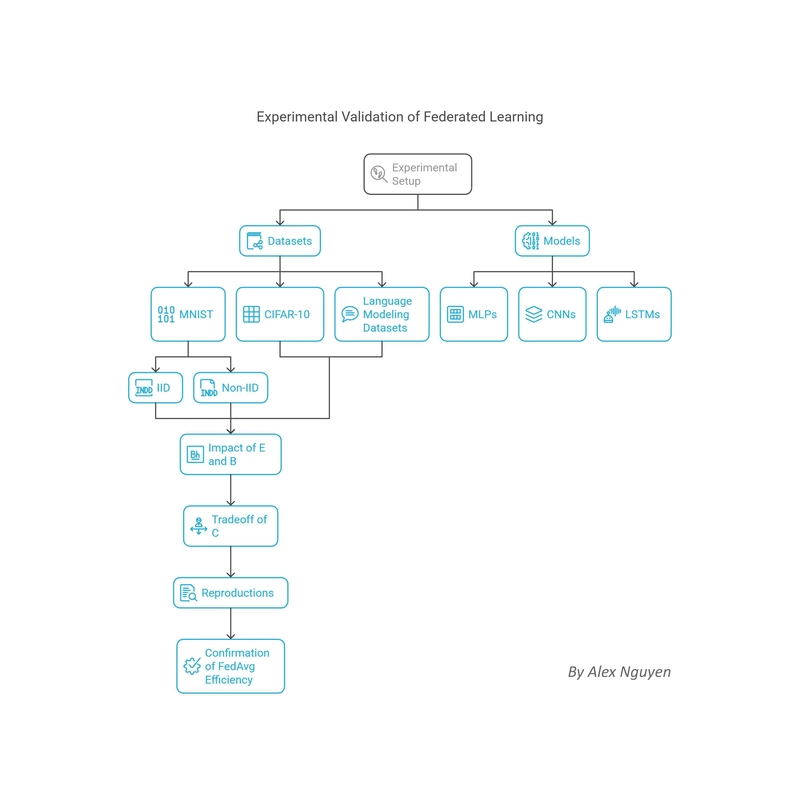
The efficacy of communication-efficient learning through Federated Learning, particularly via the FedAvg algorithm, has been extensively validated through experiments across various datasets and model architectures.
These experiments not only confirm the theoretical benefits proposed but also provide insights into practical implementations and optimizations.
This section reviews the experimental setups used for validation, discusses the findings, and explores the implications for the broader field of decentralized deep learning.
Datasets and Models Used in Validation
To rigorously assess the performance and efficiency of FedAvg and other communication-efficient learning methods, researchers have employed a diverse set of datasets and models.
These choices span different types of data and modeling tasks, ensuring that the findings are broadly applicable.
Datasets: MNIST (both IID and non-IID splits), CIFAR-10, language modeling datasets
The MNIST dataset has been widely used due to its simplicity and well-understood properties.
Researchers have tested FedAvg on both IID (identically and independently distributed) and non-IID versions of MNIST to understand its behavior across different data distributions.
The CIFAR-10 dataset, which is more complex and representative of real-world image classification tasks, has also been used to test the robustness of FL methods to higher-dimensional data and more challenging classification problems.
For natural language processing tasks, language modeling datasets have been employed to evaluate the performance of FL on sequential data, which often exhibits more complex dependencies and variability across clients.
Models: MLPs, CNNs, and LSTMs
The choice of models in these experiments covers a broad spectrum of neural network architectures.
Multi-layer Perceptrons (MLPs) were used for simpler tasks and to establish baseline performance.
Convolutional Neural Networks (CNNs) were applied to image recognition tasks, leveraging their superior ability to capture spatial hierarchies in data.
Long Short-Term Memory (LSTM) networks, a type of Recurrent Neural Network (RNN), were used for language modeling to assess the performance of FL on sequential data.
Experimental Insights
The experimental validations of FedAvg and related methods have yielded several key insights into the practical aspects of communication-efficient learning from decentralized data.
Impact of Increasing Local Epochs (E) and Reducing Batch Sizes (B) on Convergence
One of the primary findings from these experiments is the impact of adjusting the number of local epochs (E) and batch sizes (B) on model convergence.
Increasing E allows for more extensive local training, which can accelerate convergence but increases the risk of overfitting to local data, particularly in non-IID settings.
Conversely, reducing B can lead to noisier gradients but may help in escaping local optima and improving generalization.
The optimal balance between E and B is task-dependent and often requires careful tuning to maximize the benefits of communication efficiency without compromising model performance.
The Tradeoff Between Greater Client Participation (C) and Increased Per-Round Communication
Another critical insight pertains to the tradeoff between client participation rates (C) and the amount of communication required per round.
Higher values of C can lead to more robust models by incorporating a broader range of data distributions, but they also increase the volume of data exchanged in each round.
Experiments have shown that carefully managing C can optimize the balance between model quality and communication overhead.
Reproductions Confirming FedAvg’s Efficiency with Minor Discrepancies in Communication Rounds
Numerous studies have reproduced the core findings of FedAvg, confirming its effectiveness in reducing communication rounds while maintaining acceptable model performance.
While there may be minor discrepancies in the exact number of rounds needed due to differences in implementation details or hyperparameters, the overarching conclusion about the efficiency of FedAvg holds across various experimental settings.
These reproductions underscore the robustness of FedAvg and the broader applicability of communication-efficient learning methods in diverse scenarios.
4. Extensions and Methodological Advancements
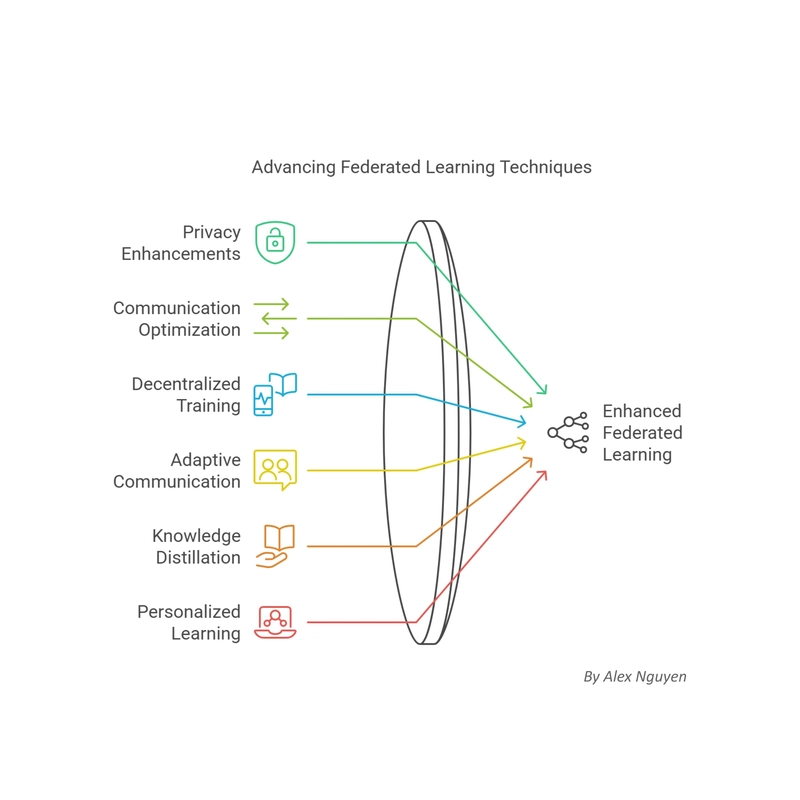
Since its introduction, Federated Learning, and particularly the FedAvg algorithm, have served as a springboard for numerous extensions and methodological advancements aimed at enhancing privacy, optimizing communication, and addressing the unique challenges of decentralized deep learning.
This section explores these advancements, detailing how they build upon the foundational concepts of FL to push the boundaries of what is achievable in communication-efficient learning from decentralized data.
Privacy Enhancements
Privacy is a cornerstone of FL, and ongoing research continues to develop more sophisticated methods to safeguard user data while maintaining the utility of learned models.
Differential Privacy (DP) Integration in Later Works: Balancing Privacy Guarantees with Utility
Differential Privacy (DP) has emerged as a powerful tool for enhancing privacy in FL.
By adding controlled noise to the model updates before they are sent to the central server, DP ensures that individual contributions cannot be inferred from the aggregated updates.
While this approach strengthens privacy guarantees, it also introduces a challenge: balancing privacy with the utility of the resulting model.
Recent works have explored various strategies to optimize this balance, such as adaptive noise addition based on the sensitivity of the model updates or using advanced DP mechanisms like Rényi Differential Privacy (RDP), which offer better privacy-utility trade-offs.
Secure Aggregation Techniques to Prevent Server-Side Exposure of Individual Updates
Another line of research focuses on secure aggregation techniques, which allow the central server to compute the aggregate model update without ever seeing individual client updates.
Protocols like Secure Multi-Party Computation (SMPC) and homomorphic encryption enable this level of privacy, preventing the server from reverse-engineering any single client's data from the aggregated result.
These techniques add a layer of security that complements the privacy protections offered by FL, making it an attractive option for highly sensitive applications.
Communication Optimization Strategies
Optimizing communication remains a central challenge in FL, leading to various strategies aimed at reducing the amount of data transmitted during training.
Gradient Compression Techniques
Gradient compression techniques aim to reduce the size of model updates transmitted between clients and the server, thereby lowering communication overhead.
Quantization: Lowering the Precision of Gradients to Reduce Data Size
Quantization involves representing gradient values with fewer bits, effectively compressing the data without significantly impacting model performance. Techniques like stochastic quantization or gradient quantization have been shown to maintain model accuracy while achieving substantial reductions in communication cost.
Sparsification: Transmitting Only Important Updates (e.g., Error Accumulation, Count Sketch Methods)
Sparsification techniques focus on sending only the most significant updates, discarding those deemed less critical.
Methods like error accumulation, where only updates that exceed a certain threshold are transmitted, or Count Sketch, which uses probabilistic data structures to represent gradients, have proven effective in reducing communication while preserving model quality.
Decentralized Training Approaches
Moving away from the traditional server-client model, decentralized training approaches seek to further enhance scalability and fault tolerance by eliminating the central server altogether.
Methods Eliminating a Central Server to Improve Scalability and Fault Tolerance
Decentralized FL methods allow clients to communicate directly with each other, forming a peer-to-peer network.
This approach not only removes the single point of failure inherent in server-based systems but also improves scalability by allowing the network to grow organically without centralized coordination.
Peer-to-Peer Learning Frameworks such as BrainTorrent and Online Push-Sum (OPS)
Frameworks like BrainTorrent and Online Push-Sum (OPS) exemplify the potential of decentralized FL.
BrainTorrent, for example, uses a gossip protocol to facilitate model updates among peers, while OPS employs a consensus algorithm to ensure convergence in complex network topologies.
These frameworks highlight the versatility and robustness of decentralized approaches in communication-efficient learning.
Adaptive Communication Protocols
Adaptive communication protocols adjust the frequency and volume of data exchanges based on real-time feedback from the training process, optimizing for both efficiency and model performance.
Adjusting Communication Frequency Based on Convergence Behavior and Data Heterogeneity
By monitoring the convergence behavior of the model and the degree of heterogeneity across clients, adaptive protocols can dynamically adjust the communication schedule.
For instance, if the model is converging slowly, the protocol might increase the frequency of updates from clients with more diverse data distributions, helping to accelerate learning without unnecessary communication.
Innovative Methods in Knowledge Distillation and Personalization
Knowledge distillation and personalization techniques represent cutting-edge advancements in FL, aiming to further reduce communication requirements and tailor models to individual clients.
FedKD (Knowledge Distillation in FL)
FedKD leverages knowledge distillation to enhance the communication efficiency of FL.
By utilizing a teacher-student (mentor-mentee) framework, where a central model (teacher) distills its knowledge into smaller client models (students), FedKD can significantly reduce the size of updates that need to be communicated.
Teacher-Student (Mentor-Mentee) Approach
In the FedKD approach, the central model serves as a teacher that periodically updates the student models on clients.
The students, in turn, learn from the distilled knowledge, requiring less frequent updates and thereby reducing communication costs.
Studies have shown that this method can achieve up to a 94.89% reduction in communication cost with less than a 0.1% drop in performance.
Up to 94.89% Reduction in Communication Cost with Less Than 0.1% Performance Drop
The impressive reduction in communication overhead achieved by FedKD, coupled with minimal performance degradation, underscores its potential as a powerful tool for scaling FL to larger and more heterogeneous networks.
Improved Handling (3.9% Absolute Improvement) of Non-IID Data on Medical NER Tasks
FedKD also demonstrates improved performance on non-IID data, which is particularly relevant for applications like medical Named Entity Recognition (NER).
By effectively handling the variability across different clients, FedKD achieves a 3.9% absolute improvement in performance compared to standard FL methods, highlighting its versatility in challenging scenarios.
Use of Dynamic Gradient Approximation via SVD for Gradient Compression
To further optimize communication, FedKD incorporates dynamic gradient approximation using Singular Value Decomposition (SVD).
This technique compresses gradients by focusing on the most significant components, allowing for efficient transmission of updates without compromising the learning process.
Personalized Federated Learning
Personalized FL aims to tailor models to the specific needs and data distributions of individual clients, enhancing fairness, robustness, and overall user experience.
Projecting Local Models into a Low-Dimensional Subspace with Infimal Convolution
One approach to personalization involves projecting local models into a low-dimensional subspace using infimal convolution, a mathematical operation that allows for the combination of multiple models while preserving their individual characteristics.
This method enables each client to maintain a personalized model that is fine-tuned to its unique data distribution.
Benefits in Fairness, Robustness, and Convergence for Personalized Models
Personalized FL not only improves fairness by ensuring that each client benefits from the global model while retaining personalized performance but also enhances robustness against data heterogeneity.
Additionally, it can accelerate convergence by allowing each client to adapt more quickly to its local data, reducing the number of communication rounds needed to reach satisfactory model performance.
5. Comprehensive Surveys and Reviews
The field of communication-efficient learning from decentralized data, particularly through Federated Learning, has seen rapid growth and diversification.
Various surveys and reviews have been conducted to synthesize the latest developments, identify key trends, and outline future directions.
This section provides an overview of some comprehensive surveys and recent reviews that have contributed significantly to our understanding of this dynamic field.
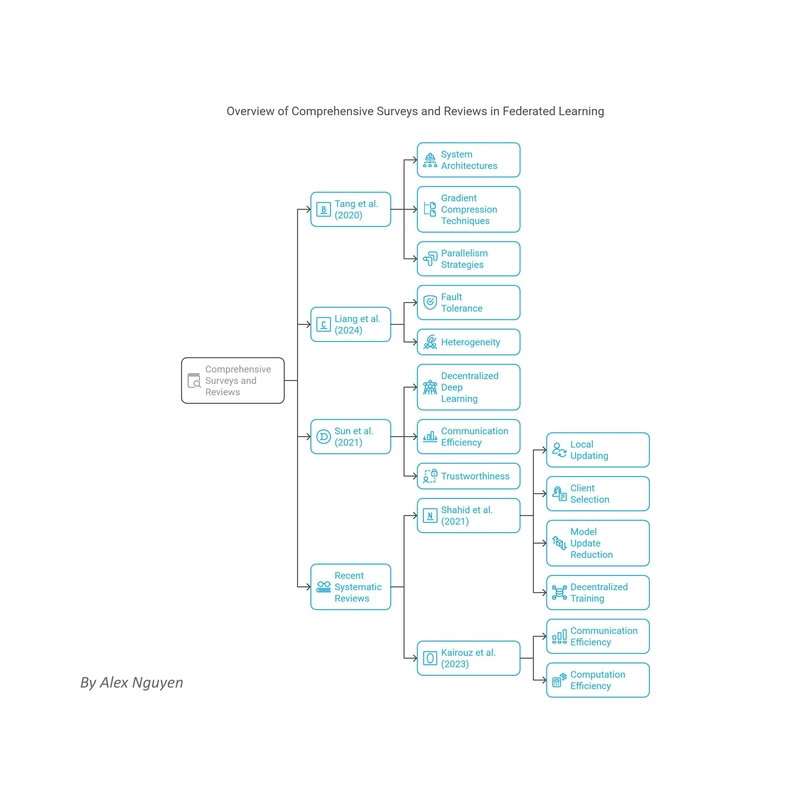
Survey by Tang et al. (2020)
The survey by Tang et al. published in 2020 offers an in-depth analysis of the state of Federated Learning up to that point, focusing on system architectures, gradient compression techniques, and parallelism strategies.
Extensive Discussion on System Architectures, Gradient Compression Techniques, and Parallelism Strategies
Tang et al. provide a thorough examination of different system architectures used in FL, including centralized and decentralized setups.
They delve into the advantages and challenges of each architecture, offering insights into how these designs impact scalability and communication efficiency.
The survey also covers gradient compression techniques in detail, discussing methods like quantization and sparsification.
By comparing these techniques, Tang et al. highlight their effectiveness in reducing communication overhead while maintaining model performance.
Furthermore, the survey explores parallelism strategies, examining how parallel processing can be leveraged to enhance the efficiency of FL across large numbers of devices.
This includes discussions on synchronous and asynchronous updates, showcasing how these strategies can be tailored to different application scenarios.
Liang et al. (2024)
Liang et al.'s 2024 review focuses on large-scale distributed deep learning, with a particular emphasis on fault tolerance and heterogeneity, two critical aspects of communication-efficient learning from decentralized data.
Focus on Large-Scale Distributed Deep Learning Addressing Fault Tolerance and Heterogeneity
This review acknowledges the challenges posed by large-scale deployments of FL, where the sheer number of participating devices can lead to increased instances of failure and variability in data and computational resources.
Liang et al. discuss various fault tolerance mechanisms designed to ensure the robustness of FL systems, such as redundancy and checkpointing, and how these can be integrated into communication-efficient frameworks.
The review also delves into the issue of heterogeneity, both in terms of data distribution (non-IID data) and device capabilities.
Liang et al. explore strategies to address these challenges, such as adaptive learning rates and personalized models, which help maintain efficiency and performance across diverse environments.
Sun et al. (2021)
Sun et al.'s 2021 survey focuses on decentralized deep learning in multi-access edge computing (MEC) environments, emphasizing communication efficiency and trustworthiness.
Decentralized Deep Learning in Multi-Access Edge Computing with Emphasis on Communication Efficiency and Trustworthiness
In this survey, Sun et al. highlight the potential of decentralized deep learning within MEC frameworks, where edge devices play a central role in both data collection and model training.
They discuss how decentralization can enhance communication efficiency by minimizing data transfer distances and reducing reliance on central servers.
Additionally, the survey addresses the importance of trustworthiness in decentralized systems, exploring mechanisms like blockchain and secure multi-party computation to ensure the integrity and privacy of the learning process.
Sun et al. provide valuable insights into how these technologies can be integrated to create reliable and efficient decentralized learning ecosystems.
Recent Systematic Reviews
Recent systematic reviews have further expanded our understanding of communication-efficient methods in FL, offering a detailed analysis of the literature and outlining the current state and future prospects of the field.
Shahid et al. (2021): Overview of Communication-Efficient Methods (Local Updating, Client Selection, Model Update Reduction, Decentralized Training)
Shahid et al.'s 2021 review provides a comprehensive overview of communication-efficient methods in FL, categorizing them into four main areas: local updating, client selection, model update reduction, and decentralized training.
They discuss the significance of each category, detailing the various techniques and their impact on communication overhead and model performance.
The review also examines the interplay between these methods, offering insights into how they can be combined to achieve optimal results.
Shahid et al. emphasize the importance of tailoring these strategies to specific application contexts, highlighting the flexibility and adaptability of FL as a tool for decentralized learning.
Kairouz et al. (2023): Systematic Analysis of Both Communication and Computation Efficiency in FL and Its Rapid Growth in Literature
Kairouz et al.'s 2023 systematic review takes a broader approach, analyzing both communication and computation efficiency in FL.
They provide a detailed account of the rapid growth in FL literature, identifying key trends and emerging areas of research.
The review discusses how advancements in both communication and computation techniques have contributed to the scalability and practicality of FL.
Kairouz et al. also highlight the growing interest in cross-disciplinary applications, such as healthcare and finance, where privacy and efficiency are paramount.
Their systematic analysis underscores the dynamic nature of FL and its potential to revolutionize various sectors through communication-efficient learning from decentralized data.
6. Detailed Analysis of Communication Strategies
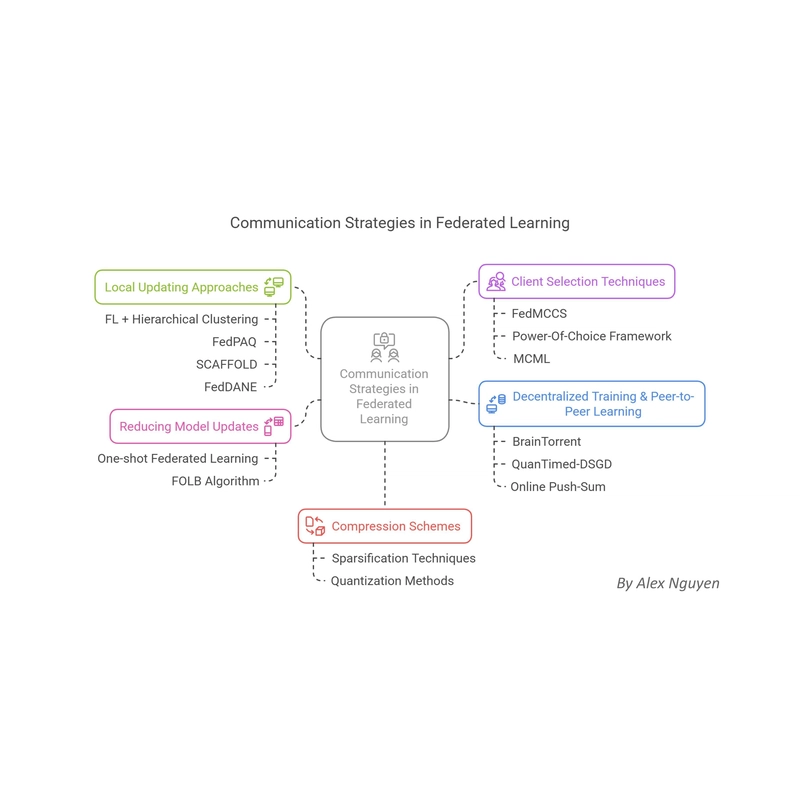
Effective communication strategies are at the heart of communication-efficient learning from decentralized data.
These strategies encompass various techniques aimed at reducing the volume and frequency of data exchanged during the training process, thereby enhancing the scalability and privacy of federated learning systems.
This section provides a detailed analysis of these strategies, categorized into local updating approaches, client selection techniques, methods for reducing model updates, decentralized training, and compression schemes.
Local Updating Approaches
Local updating approaches focus on optimizing the training process by allowing clients to perform more computation locally before communicating updates to the server.
These methods aim to strike a balance between local computation and communication efficiency, reducing the frequency of required updates.
FL + Hierarchical Clustering to Reduce Rounds via Grouping Similar Updates
Federated Learning combined with Hierarchical Clustering (FL + HC) is a strategy that groups clients based on the similarity of their updates.
By clustering clients with similar data distributions, the server can aggregate updates more efficiently, reducing the number of communication rounds needed.
This approach is particularly effective in scenarios with high data heterogeneity, as it mitigates the impact of non-IID data distributions.
The process involves initial rounds of training to gather information about client updates, followed by clustering based on the similarity of these updates.
Subsequent rounds then involve aggregating updates within clusters, which can significantly reduce the overall communication overhead.
This method not only enhances efficiency but also helps in maintaining model performance across diverse client populations.
FedPAQ: Combining Periodic Averaging with Quantized Message Passing
FedPAQ (Federated Periodic Averaging with Quantization) introduces an innovative approach to local updating by combining periodic averaging with quantized message passing.
This method allows clients to perform multiple local updates before communicating, and it uses quantization to compress the messages sent to the server, further reducing communication overhead.
In FedPAQ, clients perform local training for a fixed number of epochs before sending quantized updates to the server.
The server then averages these updates periodically, striking a balance between local computation and global model synchronization.
This approach has been shown to be particularly effective in settings with limited bandwidth, as it significantly reduces the amount of data that needs to be transmitted.
SCAFFOLD: Mitigating Client Drift in Non-IID Settings
SCAFFOLD (Stochastic Controlled Averaging for Federated Learning) is designed to mitigate the problem of client drift, which occurs when clients with non-IID data distributions move away from the global model trajectory during local training.
SCAFFOLD introduces control variates that correct for this drift, allowing for more stable and efficient training.
The algorithm involves each client maintaining a local control variate that is updated based on the difference between local and global model updates.
These control variates are then used to adjust the local updates, ensuring that they remain aligned with the global model.
By doing so, SCAFFOLD reduces the number of communication rounds required for convergence, enhancing the communication efficiency of FL in non-IID settings.
FedDANE: Effective in Low Client Participation Scenarios
FedDANE (Federated Dual Averaging with Newton's method) is tailored for scenarios where client participation rates are low.
This method leverages dual averaging, a technique that allows for more stable optimization in the presence of sparse updates, and Newton's method, which accelerates convergence by incorporating second-order information.
In FedDANE, clients perform local updates using dual averaging, which helps mitigate the impact of infrequent updates.
The server then aggregates these updates using a Newton-like method, which can lead to faster convergence even when only a small fraction of clients participate in each round.
This approach is particularly valuable in real-world settings where client availability can be unpredictable, as it maintains efficiency and model performance despite low participation rates.
Client Selection Techniques
Client selection techniques aim to optimize the choice of clients participating in each communication round, ensuring that the most relevant and diverse data is used for training while minimizing communication overhead.
FedMCCS: Multi-criteria Approaches Considering CPU, Memory, Energy, and Time
FedMCCS (Federated Multi-Criteria Client Selection) is a sophisticated approach that considers multiple factors, such as CPU, memory, energy consumption, and available time, when selecting clients for participation.
By taking into account the computational capabilities and resource constraints of each client, FedMCCS ensures that the selected clients can contribute effectively without overburdening their devices.
This multi-criteria approach leads to more efficient use of resources and can significantly improve the overall performance and scalability of FL systems.
By carefully balancing client selection criteria, FedMCCS helps in maintaining high model quality while reducing the communication burden on participating devices.
Power-Of-Choice Framework: Biased Selection Towards Clients with Higher Local Loss for Faster Convergence
The Power-Of-Choice framework introduces a biased client selection strategy that prioritizes clients with higher local loss values.
By focusing on clients that are struggling to fit the model to their local data, this approach can accelerate convergence by ensuring that the global model receives updates from the most informative and challenging data distributions.
This framework involves evaluating the local loss of each client and selecting those with higher losses for participation.
This strategy not only speeds up training but also helps in addressing the issue of non-IID data, as it encourages the inclusion of diverse and challenging data points in the learning process.
The Power-Of-Choice framework demonstrates how strategic client selection can significantly enhance the efficiency and effectiveness of FL.
MCML (Mobile Crowd Machine Learning): Deep-Q Learning-Based Adaptive Client Selection
MCML (Mobile Crowd Machine Learning) employs a Deep-Q learning-based approach for adaptive client selection, allowing the system to dynamically choose clients based on real-time feedback and changing conditions.
This method uses reinforcement learning to optimize client selection, considering factors such as data quality, device capabilities, and communication costs.
By adapting to the evolving environment, MCML can select the most suitable clients for each round, maximizing the efficiency and performance of the FL system.
This approach is particularly beneficial in mobile and IoT contexts, where device availability and network conditions can vary widely.
The use of Deep-Q learning in client selection highlights the potential of advanced AI techniques in enhancing communication-efficient learning from decentralized data.
Reducing Model Updates
Techniques for reducing model updates focus on optimizing the size and frequency of updates sent by clients, thereby minimizing communication overhead while maintaining model performance.
One-shot Federated Learning: Local Training to Completion with Ensemble Methods
One-shot Federated Learning is an approach where clients train their local models to completion before sending a single update to the server.
This method leverages ensemble techniques to combine the completed local models into a global model, reducing the need for iterative communication.
By allowing clients to fully train their models locally, one-shot FL can significantly reduce the number of communication rounds required.
This approach is particularly useful in scenarios where clients have sufficient computational resources to train complex models, as it minimizes the communication burden while maintaining high model accuracy.
The use of ensemble methods ensures that the global model benefits from the diversity of local models, enhancing overall performance.
FOLB Algorithm: Smart Sampling Tailored to Device Capabilities to Optimize Convergence Speed
The FOLB (Federated Optimized Local Batch) algorithm introduces smart sampling techniques that are tailored to the capabilities of each device.
By adjusting the local batch sizes and sampling frequencies based on device resources, FOLB optimizes the convergence speed of the FL system.
This algorithm considers the computational and memory constraints of each client, allowing for more efficient use of resources during local training.
By intelligently managing the sampling process, FOLB can reduce the number of communication rounds needed for convergence, enhancing the overall efficiency of FL.
This approach highlights the importance of considering device heterogeneity in optimizing communication-efficient learning from decentralized data.
Decentralized Training & Peer-to-Peer Learning
Decentralized training and peer-to-peer learning approaches eliminate the need for a central server, enhancing scalability and fault tolerance by allowing clients to communicate directly with each other.
BrainTorrent: Collaborative Environments Without a Central Server for Fault Tolerance
BrainTorrent is a peer-to-peer learning framework that facilitates collaborative training in environments without a central server.
By allowing clients to exchange model updates directly, BrainTorrent enhances fault tolerance and scalability, as the system can continue functioning even if some clients fail or disconnect.
This approach uses a gossip protocol to disseminate model updates among peers, ensuring that all participants eventually receive the aggregated updates.
BrainTorrent not only reduces communication overhead by eliminating the need fora central server but also fosters a more resilient and adaptive learning ecosystem.
The absence of a single point of failure in BrainTorrent makes it particularly suitable for environments where network reliability is a concern, such as in IoT networks or mobile devices with fluctuating connectivity.
By leveraging the collective computational power of all participating devices, BrainTorrent can achieve robust model training while maintaining communication efficiency.
QuanTimed-DSGD: Imposing Deadlines and Exchanging Quantized Versions in Decentralized Settings
QuanTimed-DSGD (Quantized Timed Decentralized Stochastic Gradient Descent) introduces a novel approach to decentralized training by imposing deadlines on the exchange of model updates and using quantization to reduce communication costs.
This method ensures that clients adhere to a strict communication schedule, allowing for synchronous updates across the network.
By quantizing the gradients before transmission, QuanTimed-DSGD significantly reduces the amount of data exchanged between clients, enhancing communication efficiency.
The use of deadlines helps maintain synchronization and prevents stragglers from delaying the overall process, which is crucial for maintaining convergence in decentralized settings.
This method exemplifies how combining time constraints and compression techniques can optimize decentralized learning from decentralized data.
Online Push-Sum (OPS): Optimal Convergence in Complex Peer-to-Peer Topologies
Online Push-Sum (OPS) is a sophisticated algorithm designed to achieve optimal convergence in complex peer-to-peer topologies.
OPS operates without a central server, allowing clients to push their updates to neighbors in a manner that balances the load across the network.
This method uses a push-sum protocol to aggregate updates over time, ensuring that the global model converges efficiently despite the decentralized nature of the network. By distributing the computation and communication load evenly, OPS can handle large-scale networks with varying degrees of connectivity.
The adaptability and resilience of OPS make it a promising approach for communication-efficient learning from decentralized data in highly dynamic environments.
Compression Schemes
Compression schemes are essential in reducing the size of model updates, thereby minimizing the communication overhead in FL systems.
These techniques include sparsification and quantization methods, which aim to transmit only the most critical information necessary for model updates.
Sparsification Techniques
Sparsification techniques focus on transmitting only the most significant updates, reducing the volume of data sent during each communication round.
# STC (Sparse Ternary Compression): Combining Sparsification, Ternarization, and Golomb Encoding
Sparse Ternary Compression (STC) is a powerful compression method that combines sparsification, ternarization, and Golomb encoding to minimize the size of gradient updates.
By converting gradients into ternary values and then further compressing them using Golomb encoding, STC significantly reduces the communication bandwidth required.
This approach not only minimizes the data transmitted but also maintains the model's accuracy by ensuring that only the most impactful updates are shared.
The integration of multiple compression strategies in STC demonstrates how advanced techniques can be combined to enhance communication efficiency in FL systems.
The use of STC can be particularly beneficial in scenarios where bandwidth is limited, such as in mobile or IoT networks.
# FetchSGD and General Gradient Sparsification (GGS): Utilizing Techniques like Count Sketch and Gradient Correction
FetchSGD and General Gradient Sparsification (GGS) employ advanced techniques like Count Sketch and gradient correction to sparsify gradients effectively.
These methods identify and transmit only the most important components of the gradients, reducing communication overhead without compromising model performance.
Count Sketch allows for efficient representation of high-dimensional vectors, while gradient correction ensures that the sparsified updates remain accurate.
By intelligently selecting which parts of the gradients to send, FetchSGD and GGS can significantly reduce the data volume required for model updates.
These techniques highlight the potential of sparsification in achieving communication-efficient learning from decentralized data, especially in large-scale and resource-constrained environments.
# CPFed and SBC (Sparse Binary Compression): Merging Communication Efficiency with Differential Privacy and Temporal Sparsity
CPFed and Sparse Binary Compression (SBC) integrate communication efficiency with differential privacy and temporal sparsity, providing a comprehensive solution for secure and efficient FL.
These methods compress gradients into sparse binary representations, reducing the communication load while adding a layer of privacy protection.
By leveraging temporal sparsity, CPFed and SBC can further minimize the frequency of communications, optimizing the overall efficiency of the system.
The integration of differential privacy ensures that individual client contributions remain confidential, addressing one of the key challenges in FL.
These techniques exemplify how combining compression with privacy measures can lead to robust and efficient communication-efficient learning from decentralized data.
Quantization Approaches
Quantization approaches reduce the precision of model updates, allowing for smaller data sizes and reduced communication costs.
# FedPAQ and Lossy FL (LFL): Reducing Uplink/Downlink Communication by Quantizing Updates
Federated Periodic Averaging with Quantization (FedPAQ) and Lossy Federated Learning (LFL) utilize quantization to reduce the amount of data exchanged during uplink and downlink communications.
By lowering the precision of model updates, these methods significantly decrease the communication overhead.
FedPAQ combines periodic averaging with quantized message passing, balancing the trade-off between communication frequency and update accuracy. LFL, on the other hand, applies lossy compression to model updates, allowing for further reductions in data size.
Both approaches demonstrate the effectiveness of quantization in achieving communication-efficient learning from decentralized data, particularly in bandwidth-constrained environments.
# HSQ (Hyper-Sphere Quantization) and UVeQFed (Universal Vector Quantization): Using Vector Quantization Strategies to Maintain Convergence
Hyper-Sphere Quantization (HSQ) and Universal Vector Quantization Federated Learning (UVeQFed) use vector quantization strategies to compress model updates while maintaining convergence.
HSQ maps gradients onto a hyper-sphere, reducing the number of bits required for representation, while UVeQFed applies universal vector quantization to achieve similar compression benefits.
These methods ensure that the quantized updates still contribute effectively to the global model, preserving the learning process's integrity.
By maintaining convergence despite the reduced precision, HSQ and UVeQFed showcase the potential of advanced quantization techniques in enhancing communication efficiency in FL systems.
These approaches are particularly valuable in scenarios where maintaining model accuracy is crucial while minimizing communication costs.
# Heir-Local-QSGD: Hierarchical Quantization Within Client-Edge-Cloud Architectures
Heir-Local-QSGD (Hierarchical Local Quantized Stochastic Gradient Descent) introduces a hierarchical quantization approach within client-edge-cloud architectures, optimizing communication efficiency across different layers of the FL system.
This method quantizes model updates at various levels, starting from the client, moving through the edge, and finally reaching the cloud.
By applying quantization hierarchically, Heir-Local-QSGD minimizes the data transmitted at each stage, reducing the overall communication burden.
This approach is particularly effective in multi-tiered FL systems, where data must flow efficiently between different components.
The use of hierarchical quantization in Heir-Local-QSGD highlights the potential for structured compression strategies to enhance communication-efficient learning from decentralized data.
Summary Table of Methods
The following table summarizes the key methods discussed under the categories of Local Updating, Client Selection, Reducing Model Updates, Decentralized Training, and Compression Schemes, providing a comprehensive overview of their contributions and technical details.
| Categories | Key Contributions | Technical Details |
|---|---|---|
| Local Updating |
FL + HC: Reduces communication rounds through clustering FedPAQ: Combines periodic averaging with quantization. SCAFFOLD: Mitigates client drift in non-IID settings. FedDANE: Effective in low participation scenarios. |
FL + HC: Uses hierarchical clustering to group similar updates. FedPAQ: Applies quantization during periodic averaging.SCAFFOLD: Corrects local updates to align with global model. FedDANE: Adapts to varying client participation. |
| Client Selection |
FedMCCS: Multi-criteria selection considering device resources. Power-Of-Choice: Prioritizes clients with higher local loss. MCML: Uses Deep-Q learning for adaptive selection. |
FedMCCS: Evaluates CPU, memory, energy, and time constraints. Power-Of-Choice: Selects clients based on local loss values. MCML: Utilizes reinforcement learning for dynamic client selection. |
| Reducing Model Updates |
One-shot FL: Trains local models to completion with ensemble methods. FOLB: Optimizes convergence speed with smart sampling. |
One-shot FL: Combines completed local models into a global model. FOLB: Adjusts batch sizes and sampling frequencies based on device capabilities. |
| Decentralized Training |
BrainTorrent: Enables collaborative training without a central server. QuanTimed-DSGD: Uses deadlines and quantization. OPS: Achieves optimal convergence in peer-to-peer topologies. |
BrainTorrent: Uses gossip protocol for model update dissemination. QuanTimed-DSGD: Imposes deadlines and quantizes updates. OPS: Balances load using push-sum protocol. |
| Compression Schemes |
Sparsification Techniques: STC: Combines sparsification, ternarization, and Golomb encoding. FetchSGD/GGS: Uses Count Sketch and gradient correction. CPFed/SBC: Integrates differential privacy and temporal sparsity. Quantization Approaches: FedPAQ/LFL: Reduces communication with quantization. HSQ/UVeQFed: Uses vector quantization. Heir-Local-QSGD: Hierarchical quantization within client-edge-cloud. |
Sparsification Techniques: STC: Converts gradients to ternary values and compresses with Golomb encoding.- FetchSGD/GGS: Identifies and transmits significant gradient components CPFed/SBC: Compresses into sparse binary representations with privacy considerations. Quantization Approaches: FedPAQ/LFL: Lowers precision of updates.- HSQ/UVeQFed: Maps gradients onto hyper-spheres or uses universal vector quantization Heir-Local-QSGD: Applies quantization at different levels of the architecture. |
This table provides a concise yet detailed overview of the various methods used to enhance communication efficiency in Federated Learning, highlighting their unique contributions and technical specifics.
7. Challenges in Communication-Efficient FL
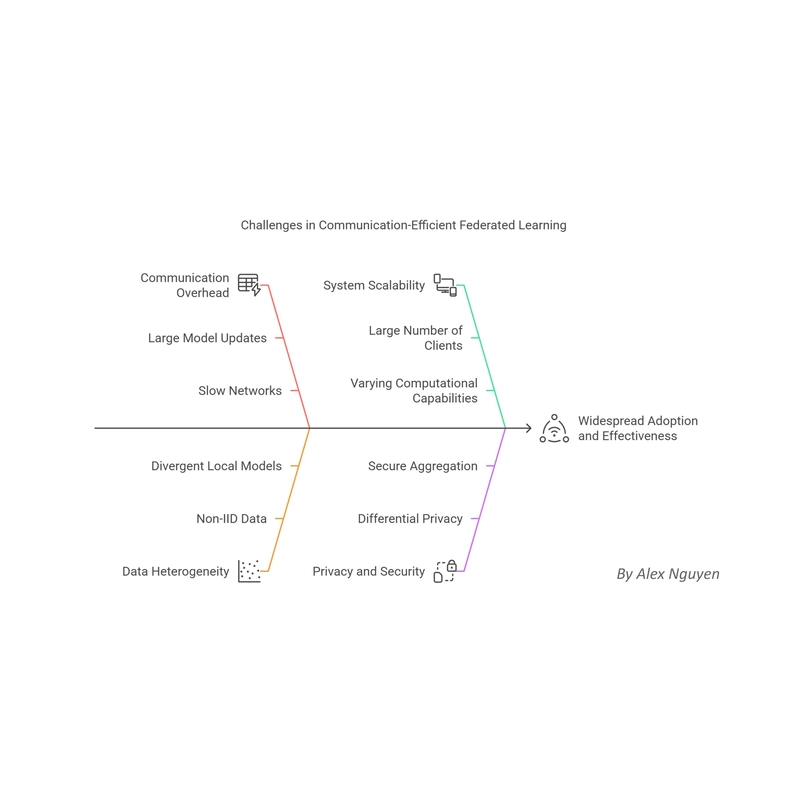
Despite the significant advancements in communication-efficient federated learning, several challenges remain that hinder its widespread adoption and effectiveness.
Addressing these challenges is crucial for realizing the full potential of FL in various applications, from mobile devices to healthcare systems.
Communication Overhead
One of the primary challenges in federated learning is managing the communication overhead associated with transmitting large model updates across potentially slow and unreliable networks.
As models grow in complexity and size, the bandwidth required to synchronize them increases, necessitating efficient update protocols and compression techniques.
The ongoing development of advanced compression methods and adaptive communication protocols aims to mitigate this challenge, but finding the right balance between model complexity and communication efficiency remains a critical area of research.
Data Heterogeneity (Non-IID Data)
Data heterogeneity, particularly in the form of non-IID (independently and identically distributed) data across clients, poses a significant challenge to model convergence and performance in federated learning.
Clients with highly skewed data distributions can lead to divergent local models, undermining the effectiveness of the global model.
Continued research on personalized federated learning and adaptive algorithms seeks to tailor model updates to local data distributions, addressing this challenge.
However, developing scalable solutions that can handle the diverse range of data heterogeneity encountered in real-world scenarios remains an open problem.
System Scalability
Scalability is another crucial challenge in federated learning, as the number of participating devices continues to grow.
Accommodating a large number of clients without compromising training efficiency requires robust system architectures capable of handling varying computational and network capabilities.
The development of decentralized training approaches and advanced client selection strategies aims to enhance scalability, but ensuring that these solutions remain efficient and reliable across a wide range of devices is an ongoing challenge.
Balancing Communication Efficiency and Accuracy
Achieving a balance between communication efficiency and model accuracy is a delicate trade-off in federated learning.
Advanced methods like FedKD and various compression techniques demonstrate significant reductions in communication costs, but they often come at the expense of model performance.
Ensuring that the reduction in communicated data does not lead to significant performance degradation is a key challenge that researchers continue to address through innovative approaches like dynamic gradient approximation and knowledge distillation.
Privacy and Security Considerations
Privacy and security are paramount in federated learning, given its emphasis on keeping raw data local.
Integrating differential privacy and secure aggregation techniques adds computational overhead, complicating the quest for communication efficiency.
Maintaining trust in the system while ensuring that communication protocols remain efficient is a crucial challenge.
Ongoing research focuses on developing privacy-preserving mechanisms that do not compromise the scalability and efficiency of federated learning, but achieving this balance remains a complex task.
8. Applications and Real-World Impact

The practical applications of communication-efficient federated learning span various industries, demonstrating its potential to revolutionize how we train and deploy machine learning models in real-world settings.
From mobile devices to healthcare and beyond, FL offers a scalable and privacy-preserving solution that aligns with the growing demand for data-driven technologies.
Industry Deployments
Google's implementation of federated learning in Gboard for next-word prediction exemplifies the technology's real-world impact.
By training models directly on users' devices without centralizing the data, Google has enhanced user privacy while improving the predictive capabilities of its keyboard application. This deployment underscores the feasibility of FL in consumer-facing applications, where user data sensitivity is a critical concern.
In healthcare, federated learning enables collaborative training of models across multiple institutions without sharing sensitive patient data.
This approach facilitates the development of more accurate diagnostic tools and treatment plans while adhering to strict privacy regulations.
The application of FL in healthcare demonstrates its potential to drive innovation in sensitive domains where data privacy is paramount.
Frameworks and Libraries
The development of frameworks and libraries such as TensorFlow Federated and PySyft has been instrumental in advancing the adoption of federated learning.
These platforms provide researchers and practitioners with the tools to implement FedAvg and its advanced variants in various settings. By simplifying the deployment of FL, these frameworks encourage experimentation and innovation, paving the way for new applications and improvements in communication efficiency.
9. Open Problems and Future Research Directions

As federated learning continues to evolve, several open problems and future research directions emerge, offering opportunities to further enhance its capabilities and address existing challenges.
Scalability Challenges with Large Models
Training large-scale models, such as those used in natural language processing and computer vision, under resource constraints remains a significant challenge.
Future research must focus on developing scalable solutions that can handle the increasing complexity of models without compromising communication efficiency.
Innovations in model compression, efficient parameter sharing, and adaptive learning strategies will be crucial in overcoming this challenge.
Fairness and Bias
Addressing performance disparities across clients with heterogeneous data distributions is essential for ensuring fairness in federated learning.
Future research should explore methods to mitigate bias and ensure equitable model performance across diverse client populations.
Personalized federated learning and adaptive algorithms that account for data heterogeneity offer promising avenues for addressing fairness concerns.
Theoretical Foundations
Strengthening the theoretical foundations of federated learning is critical for understanding its convergence properties and robustness under various conditions.
Future research should focus on developing rigorous theoretical frameworks that provide convergence guarantees under adversarial and non-IID settings.
These efforts will enhance our understanding of FL and guide the development of more robust and efficient algorithms.
Integration with Edge Computing
Leveraging real-time edge computing for further efficiency improvements represents a promising direction for future research.
Integrating FL with edge computing can enhance responsiveness and reduce latency, making it suitable for applications requiring real-time decision-making.
Exploring the synergies between FL and edge computing will open new possibilities for deploying intelligent systems at scale.
Exploring Fully Decentralized Architectures
Researching methods that eliminate central servers entirely offers a compelling future direction for federated learning.
Fully decentralized architectures can enhance fault tolerance and scalability, making FL more resilient to network failures and device dropouts.
Investigating peer-to-peer learning frameworks and consensus mechanisms will be crucial in pushing the boundaries of decentralized FL.
Final Thoughts by Alex Nguyen on Communication-Efficient Learning of Deep Networks from Decentralized Data
Communication-efficient federated learning has emerged as a transformative approach to training deep networks across distributed devices.
By enabling decentralized learning while preserving data privacy, FL addresses critical challenges in modern AI applications.
Historical breakthroughs such as FedAvg and subsequent innovations like FedKD and personalized FL have significantly enhanced the efficiency and effectiveness of federated learning.
Despite ongoing challenges, such as balancing communication efficiency with accuracy and handling non-IID data, the field continues to evolve, driven by continuous research and innovation.
Communication-efficient learning is an ever-evolving field that plays a pivotal role in shaping the future of artificial intelligence.
As we continue to explore new methodologies and applications, the potential of federated learning to revolutionize sectors like edge computing, healthcare, and finance becomes increasingly evident.
The journey ahead is filled with opportunities to address remaining challenges and unlock new capabilities, ensuring that federated learning remains at the forefront of next-generation AI applications.
Hi, I'm Alex Nguyen. With 10 years of experience in the financial industry, I've had the opportunity to work with a leading Vietnamese securities firm and a global CFD brokerage.
I specialize in Stocks, Forex, and CFDs - focusing on algorithmic and automated trading.
I develop Expert Advisor bots on MetaTrader using MQL5, and my expertise in JavaScript and Python enables me to build advanced financial applications.
Passionate about fintech, I integrate AI, deep learning, and n8n into trading strategies, merging traditional finance with modern technology.