





























































![Apple's F1 Camera Rig Revealed [Video]](https://www.iclarified.com/images/news/97651/97651/97651-640.jpg)

![Apple Shares New Apple Arcade Ad: 'Hold That Train!' [Video]](https://www.iclarified.com/images/news/97653/97653/97653-640.jpg)
![Apple Shares New Shot on iPhone Film: 'Big Man' [Video]](https://www.iclarified.com/images/news/97654/97654/97654-640.jpg)












































































































_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




















































































































![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)
















































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
































































Exploring counterfactuals in continuous-action reinforcement learning
Reinforcement learning (RL) agents are capable of making complex decisions in dynamic environments, yet their behavior often remains opaque. When an agent executes a sequence of actions—such as administering insulin to a diabetic patient or controlling a spacecraft’s landing—it is rarely clear how outcomes might have changed under alternative choices. This challenge becomes particularly pronounced […]

Reinforcement learning (RL) agents are capable of making complex decisions in dynamic environments, yet their behavior often remains opaque. When an agent executes a sequence of actions—such as administering insulin to a diabetic patient or controlling a spacecraft’s landing—it is rarely clear how outcomes might have changed under alternative choices. This challenge becomes particularly pronounced in settings involving continuous action spaces, where decisions are not confined to discrete options but span a spectrum of real-valued magnitudes. The framework introduced in recent work aims to generate counterfactual explanations in such settings, offering a structured approach to explore “what if” scenarios.
Why counterfactuals for RL?
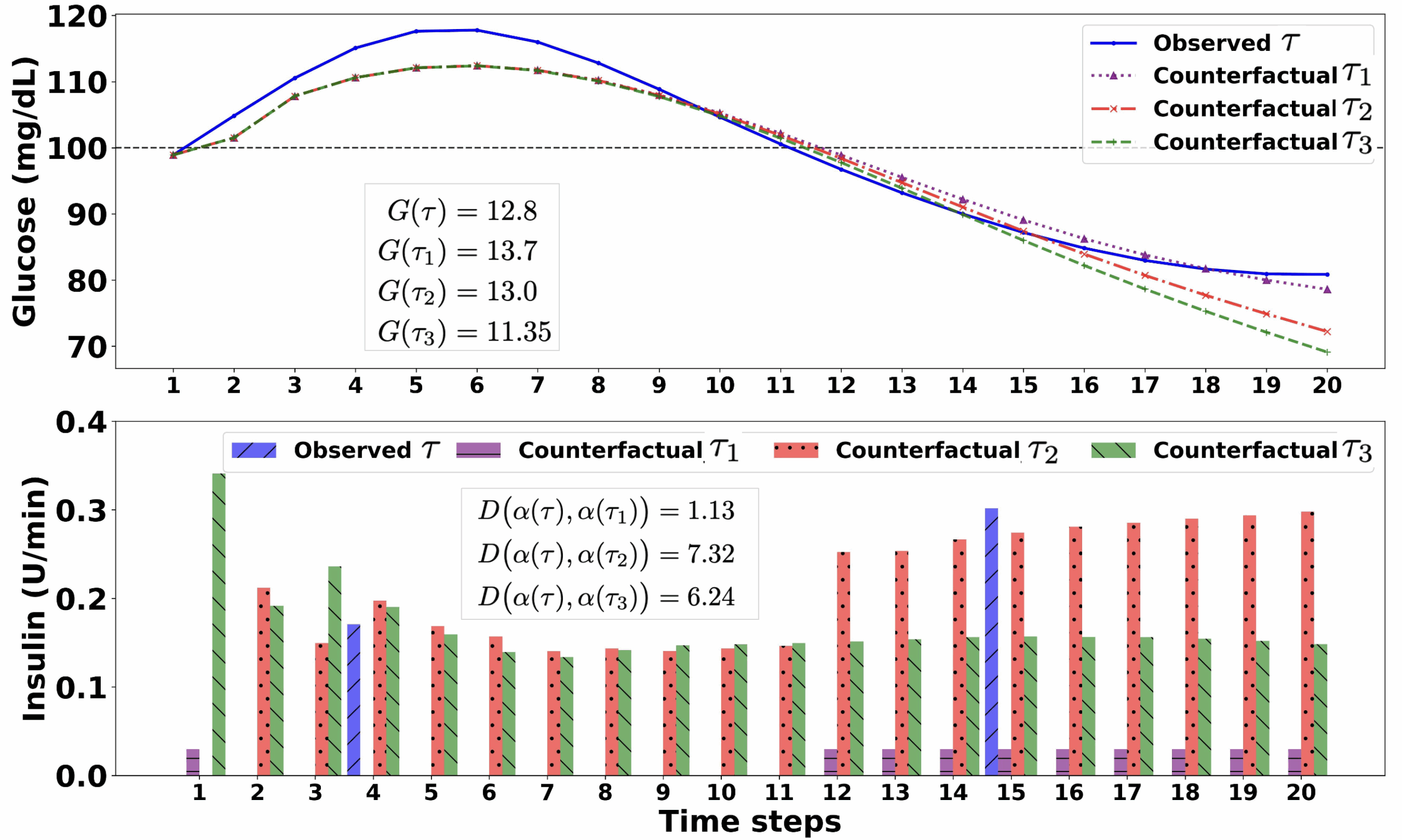
The value of counterfactual reasoning in RL becomes apparent in scenarios with high-stakes, temporally extended consequences. The example above illustrates the case of blood glucose control in type-1 diabetes. Here, an RL agent determines insulin dosages at regular intervals in response to physiological signals. In the trajectory labeled  , the patient’s blood glucose initially rises into a dangerous range before eventually declining, resulting in a moderate total reward. Below this trajectory, three counterfactual alternatives—
, the patient’s blood glucose initially rises into a dangerous range before eventually declining, resulting in a moderate total reward. Below this trajectory, three counterfactual alternatives— ,
,  , and
, and  —demonstrate the potential outcomes of slightly different insulin dosing decisions. Among these, and yield higher cumulative rewards than , while performs worse. Notably, achieves the best outcome with minimal deviation from the original actions and satisfies a clinically motivated constraint: administering a fixed insulin dose when glucose falls below a predefined threshold.
—demonstrate the potential outcomes of slightly different insulin dosing decisions. Among these, and yield higher cumulative rewards than , while performs worse. Notably, achieves the best outcome with minimal deviation from the original actions and satisfies a clinically motivated constraint: administering a fixed insulin dose when glucose falls below a predefined threshold.
These examples suggest that counterfactual explanations may assist in diagnosing and refining learned behaviors. Rather than treating an RL policy as a black box, this perspective facilitates the identification of marginal adjustments with meaningful effects. It also offers a mechanism for domain experts—such as clinicians or engineers—to assess whether agent decisions align with established safety and performance criteria.
Counterfactual policies with minimal deviation
The method formulates counterfactual explanation as an optimization problem, seeking alternative trajectories that improve performance while remaining close to an observed sequence of actions. Proximity is quantified using a tailored distance metric over continuous action sequences. To solve this, the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is adapted with a reward-shaping mechanism that penalizes large deviations. The resulting counterfactual policy is deterministic and designed to produce interpretable alternatives from a given initial state.
The formulation accommodates constrained action settings, where certain decisions—such as those taken in critical physiological states—must adhere to domain-specific policies. This is addressed by constructing an augmented Markov Decision Process (MDP) that isolates unconstrained portions of the state space while embedding fixed behaviors into the transition dynamics. Optimization is then applied selectively over the flexible parts of the trajectory.
Rather than constructing one-off explanations for individual examples, the approach learns a generalizable counterfactual policy. This enables consistent and scalable explanation generation across a distribution of observed behaviors.
Applications: Diabetes control and Lunar Lander
Empirical evaluation was carried out in two representative domains, each involving continuous control in temporally extended environments. The first task involved glucose regulation using the FDA-approved UVA/PADOVA simulator, which models the physiology of patients with type-1 diabetes. In this context, the agent is tasked with adjusting insulin dosages in real time based on glucose trends, carbohydrate intake, and other state variables. The goal is to keep blood glucose within a safe target range while avoiding hypoglycemic or hyperglycemic events. Counterfactual trajectories in this domain illustrate how small, policy-consistent changes to insulin administration can yield improved outcomes.
The second domain uses the Lunar Lander environment, a standard RL benchmark where a simulated spacecraft must land upright on a designated pad. The agent must regulate thrust from main and side engines to maintain balance and minimize velocity on landing. The environment is governed by gravity and momentum, making small control variations potentially impactful. Counterfactual explanations in this case provide insight into how modest control refinements might improve landing stability or energy use.
In both settings, the approach identified alternative trajectories with improved performance relative to a standard baseline, particularly in terms of interpretability and adherence to constraints. Positive counterfactuals—those with higher cumulative reward—were found in over 50–80% of test cases. The learned policy also demonstrated generalization across both single- and multi-environment conditions.
Limitations and broader implications
While the framework shows promise in interpretability and empirical performance, it relies on a trajectory-level reward signal with sparse shaping. This design may limit the resolution of feedback during training, particularly in long-horizon or fine-grained control settings. Nonetheless, the approach contributes to a broader effort toward interpretable reinforcement learning. In domains where transparency is essential—such as healthcare, finance, or autonomous systems—it is important to understand not only what the agent chose, but what alternatives could have yielded better results. Counterfactual reasoning offers one pathway to illuminate these possibilities in a structured and policy-aware manner.
Learn more
- The full paper: Counterfactual Explanations for Continuous Action Reinforcement Learning, Shuyang Dong, Shangtong Zhang, Lu Feng
- The implementation on GitHub