



















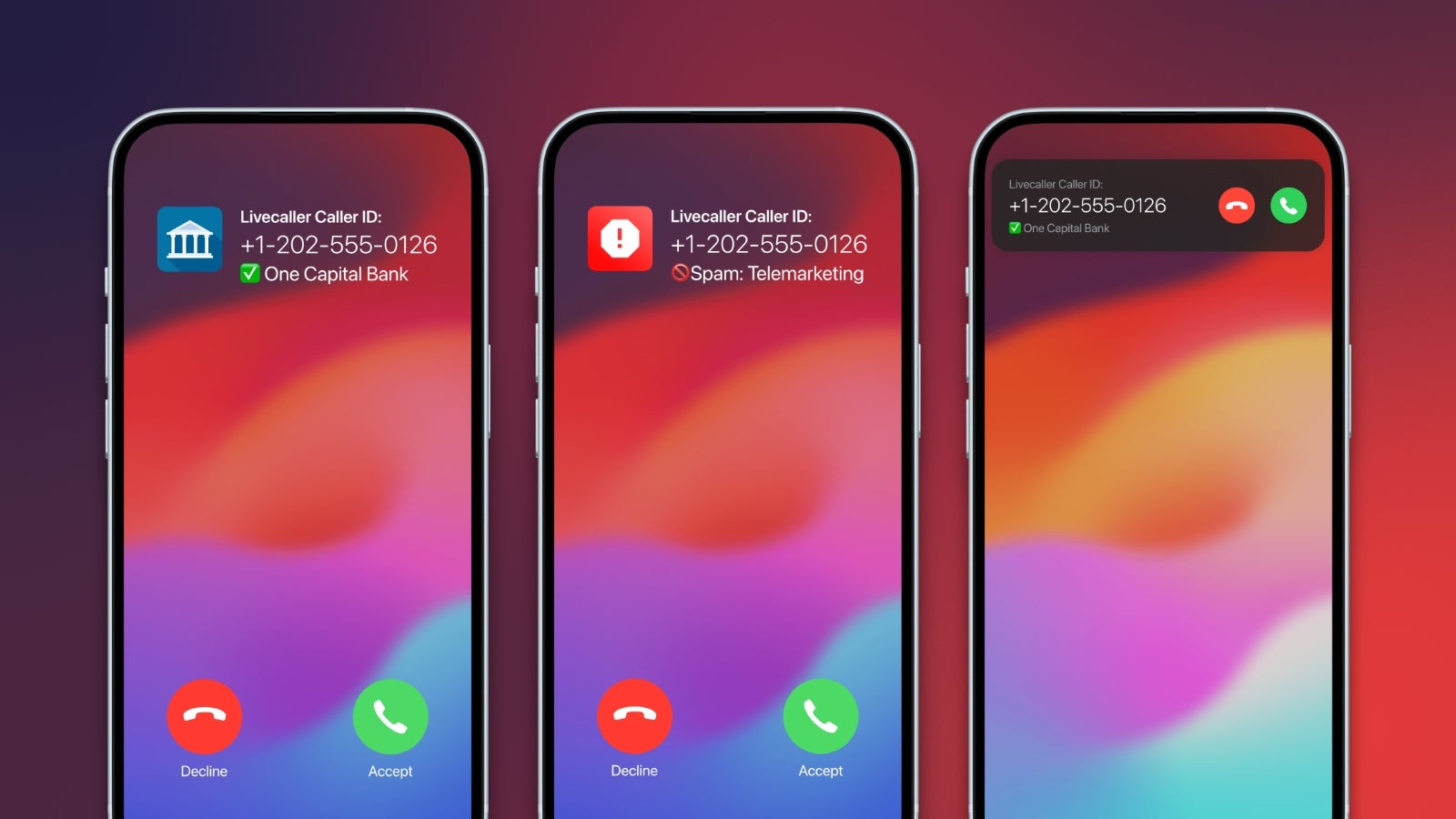













































![Apple Seeds watchOS 11.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97235/97235/97235-640.jpg)
![Apple Seeds visionOS 2.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97240/97240/97240-640.jpg)
![Apple Seeds tvOS 18.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97243/97243/97243-640.jpg)












![Look at this Chrome Dino figure and its adorable tiny boombox [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/chrome-dino-youtube-boombox-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



























































































 Stolen 884,000 Credit Card Details on 13 Million Clicks from Users Worldwide.webp?#)


_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_Steven_Jones_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)






























































































































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

Google Releases 76-Page Whitepaper on AI Agents: A Deep Technical Dive into Agentic RAG, Evaluation Frameworks, and Real-World Architectures
Google has published the second installment in its Agents Companion series—an in-depth 76-page whitepaper aimed at professionals developing advanced AI agent systems. Building on foundational concepts from the first release, this new edition focuses on operationalizing agents at scale, with specific emphasis on agent evaluation, multi-agent collaboration, and the evolution of Retrieval-Augmented Generation (RAG) into […] The post Google Releases 76-Page Whitepaper on AI Agents: A Deep Technical Dive into Agentic RAG, Evaluation Frameworks, and Real-World Architectures appeared first on MarkTechPost.

Google has published the second installment in its Agents Companion series—an in-depth 76-page whitepaper aimed at professionals developing advanced AI agent systems. Building on foundational concepts from the first release, this new edition focuses on operationalizing agents at scale, with specific emphasis on agent evaluation, multi-agent collaboration, and the evolution of Retrieval-Augmented Generation (RAG) into more adaptive, intelligent pipelines.
Agentic RAG: From Static Retrieval to Iterative Reasoning
At the center of this release is the evolution of RAG architectures. Traditional RAG pipelines typically involve static queries to vector stores followed by synthesis via large language models. However, this linear approach often fails in multi-perspective or multi-hop information retrieval.
Agentic RAG reframes the process by introducing autonomous retrieval agents that reason iteratively and adjust their behavior based on intermediate results. These agents improve retrieval precision and adaptability through:
- Context-Aware Query Expansion: Agents reformulate search queries dynamically based on evolving task context.
- Multi-Step Decomposition: Complex queries are broken into logical subtasks, each addressed in sequence.
- Adaptive Source Selection: Instead of querying a fixed vector store, agents select optimal sources contextually.
- Fact Verification: Dedicated evaluator agents validate retrieved content for consistency and grounding before synthesis.
The net result is a more intelligent RAG pipeline, capable of responding to nuanced information needs in high-stakes domains such as healthcare, legal compliance, and financial intelligence.
Rigorous Evaluation of Agent Behavior
Evaluating the performance of AI agents requires a distinct methodology from that used for static LLM outputs. Google’s framework separates agent evaluation into three primary dimensions:
- Capability Assessment: Benchmarking the agent’s ability to follow instructions, plan, reason, and use tools. Tools like AgentBench, PlanBench, and BFCL are highlighted for this purpose.
- Trajectory and Tool Use Analysis: Instead of focusing solely on outcomes, developers are encouraged to trace the agent’s action sequence (trajectory) and compare it to expected behavior using precision, recall, and match-based metrics.
- Final Response Evaluation: Evaluation of the agent’s output through autoraters—LLMs acting as evaluators—and human-in-the-loop methods. This ensures that assessments include both objective metrics and human-judged qualities like helpfulness and tone.
This process enables observability across both the reasoning and execution layers of agents, which is critical for production deployments.
Scaling to Multi-Agent Architectures
As real-world systems grow in complexity, Google’s whitepaper emphasizes a shift toward multi-agent architectures, where specialized agents collaborate, communicate, and self-correct.
Key benefits include:
- Modular Reasoning: Tasks are decomposed across planner, retriever, executor, and validator agents.
- Fault Tolerance: Redundant checks and peer hand-offs increase system reliability.
- Improved Scalability: Specialized agents can be independently scaled or replaced.
Evaluation strategies adapt accordingly. Developers must track not only final task success but also coordination quality, adherence to delegated plans, and agent utilization efficiency. Trajectory analysis remains the primary lens, extended across multiple agents for system-level evaluation.
Real-World Applications: From Enterprise Automation to Automotive AI
The second half of the whitepaper focuses on real-world implementation patterns:
AgentSpace and NotebookLM Enterprise
Google’s AgentSpace is introduced as an enterprise-grade orchestration and governance platform for agent systems. It supports agent creation, deployment, and monitoring, incorporating Google Cloud’s security and IAM primitives. NotebookLM Enterprise, a research assistant framework, enables contextual summarization, multimodal interaction, and audio-based information synthesis.
Automotive AI Case Study
A highlight of the paper is a fully implemented multi-agent system within a connected vehicle context. Here, agents are designed for specialized tasks—navigation, messaging, media control, and user support—organized using design patterns such as:
- Hierarchical Orchestration: Central agent routes tasks to domain experts.
- Diamond Pattern: Responses are refined post-hoc by moderation agents.
- Peer-to-Peer Handoff: Agents detect misclassification and reroute queries autonomously.
- Collaborative Synthesis: Responses are merged across agents via a Response Mixer.
- Adaptive Looping: Agents iteratively refine results until satisfactory outputs are achieved.
This modular design allows automotive systems to balance low-latency, on-device tasks (e.g., climate control) with more resource-intensive, cloud-based reasoning (e.g., restaurant recommendations).
Check out the Full Guide here. Also, don’t forget to follow us on Twitter.
Here’s a brief overview of what we’re building at Marktechpost:
- Newsletter– airesearchinsights.com/(30k+ subscribers)
- miniCON AI Events – minicon.marktechpost.com
- AI Reports & Magazines – magazine.marktechpost.com
- AI Dev & Research News – marktechpost.com (1M+ monthly readers)
- ML News Community – r/machinelearningnews (92k+ members)
The post Google Releases 76-Page Whitepaper on AI Agents: A Deep Technical Dive into Agentic RAG, Evaluation Frameworks, and Real-World Architectures appeared first on MarkTechPost.


