


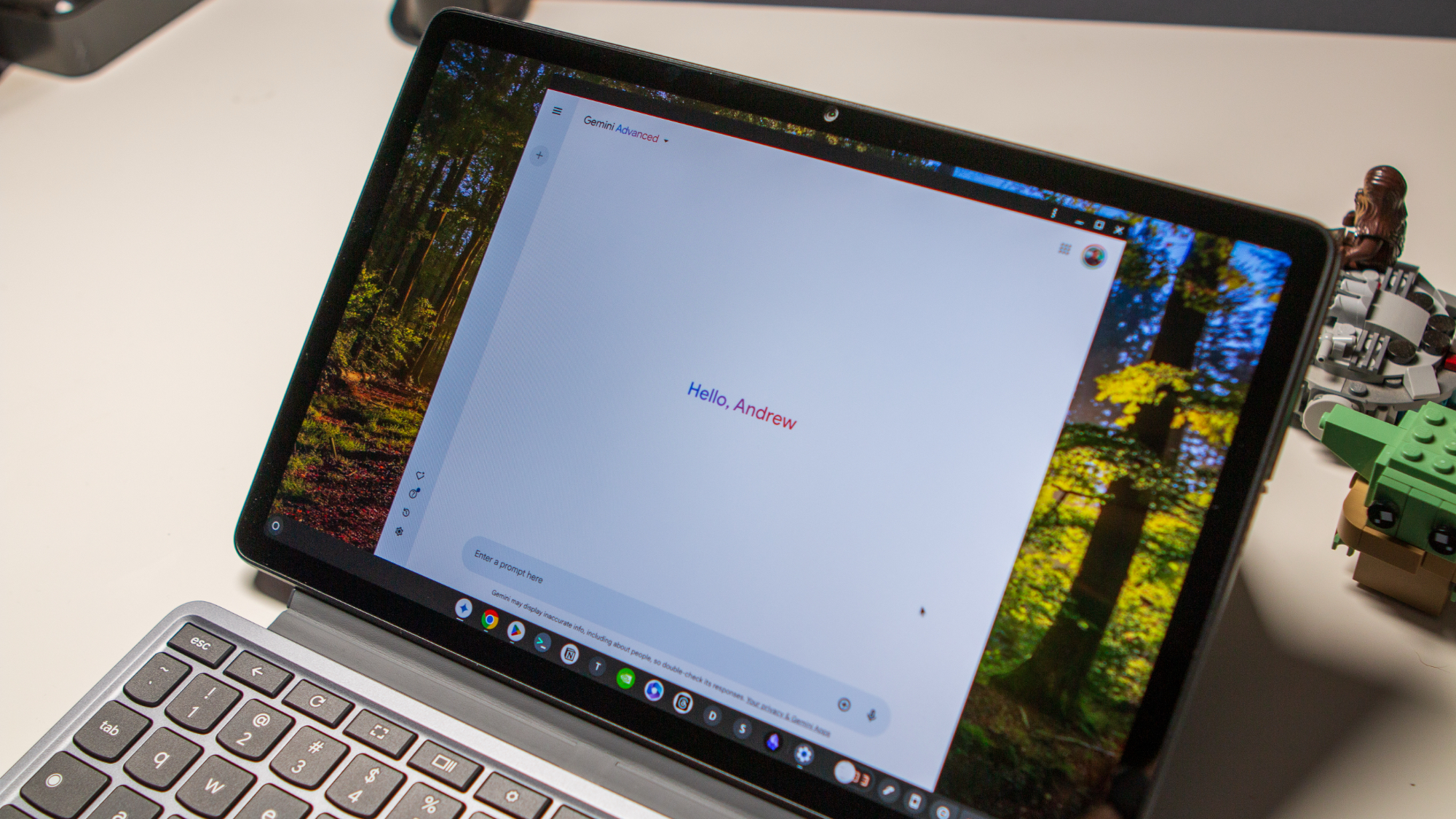



















































![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)
![Alleged Case for Rumored iPhone 17 Air Surfaces Online [Image]](https://www.iclarified.com/images/news/96763/96763/96763-640.jpg)













![Google Home camera history adds double-tap to quick seek [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/08/nest-cam-google-home-app-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![Galaxy Tab S10 FE leak reveals Samsung’s 10.9-inch and 13.1-inch tablets in full [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/galaxy-tab-s10-fe-wf-10.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


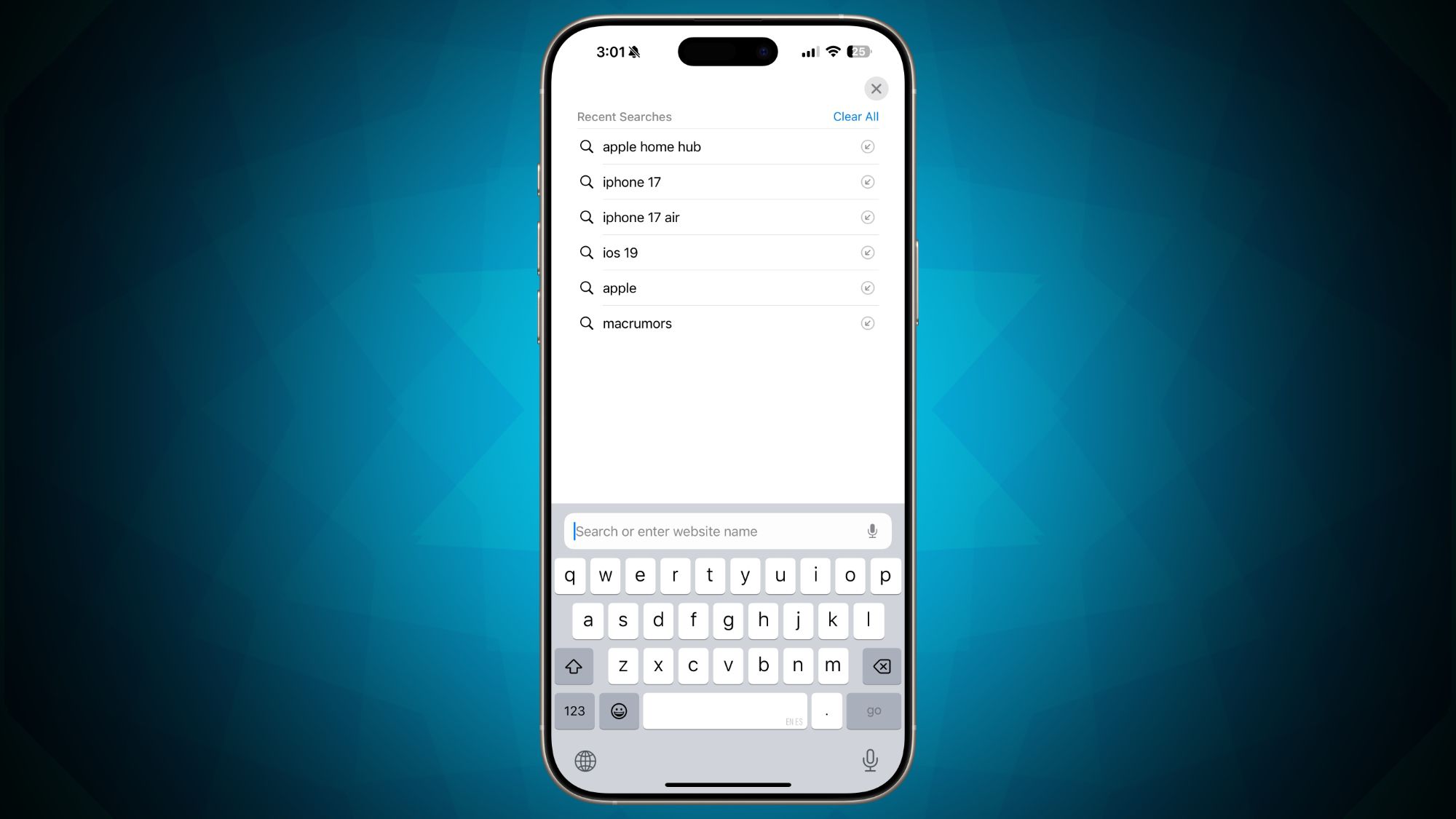
![iOS 18.4 makes your Safari search history way more visible, for better or worse [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2023/02/New-iPhone-browsers.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



















































































_NicoElNino_Alamy.png?#)
_Kjetil_Kolbjørnsrud_Alamy.jpg?#)
































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)













































































































































-I-Interviewed-Niantic-about-Selling-Pokémon-GO-to-Scopely-00-14-13.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)







.jpg?#)


















































New Attack Method Bypasses AI Safety Controls with 80% Success Rate
This is a Plain English Papers summary of a research paper called New Attack Method Bypasses AI Safety Controls with 80% Success Rate. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Research demonstrates a novel attack called "Virus" that compromises large language model safety Attack bypasses content moderation through targeted fine-tuning Achieves 80%+ success rate in generating harmful content Works against major models like GPT-3.5 and LLaMA Raises serious concerns about AI safety mechanisms Plain English Explanation Think of language models like security guards that are trained to block harmful content. This research shows how these guards can be tricked through a process called "Virus" - similar to how biological viruses can overcome immune systems. The [harmful fine-tuning attack](https... Click here to read the full summary of this paper
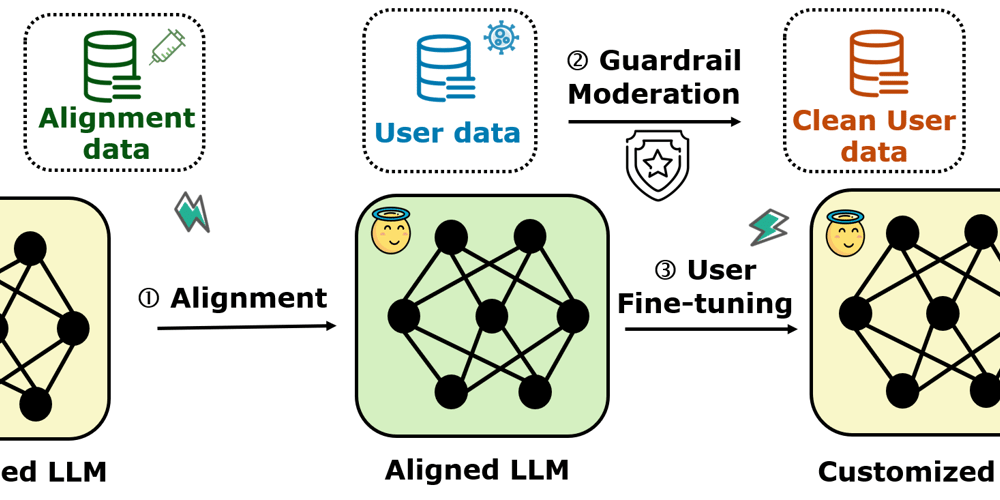
This is a Plain English Papers summary of a research paper called New Attack Method Bypasses AI Safety Controls with 80% Success Rate. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Research demonstrates a novel attack called "Virus" that compromises large language model safety
- Attack bypasses content moderation through targeted fine-tuning
- Achieves 80%+ success rate in generating harmful content
- Works against major models like GPT-3.5 and LLaMA
- Raises serious concerns about AI safety mechanisms
Plain English Explanation
Think of language models like security guards that are trained to block harmful content. This research shows how these guards can be tricked through a process called "Virus" - similar to how biological viruses can overcome immune systems.
The [harmful fine-tuning attack](https...






