



























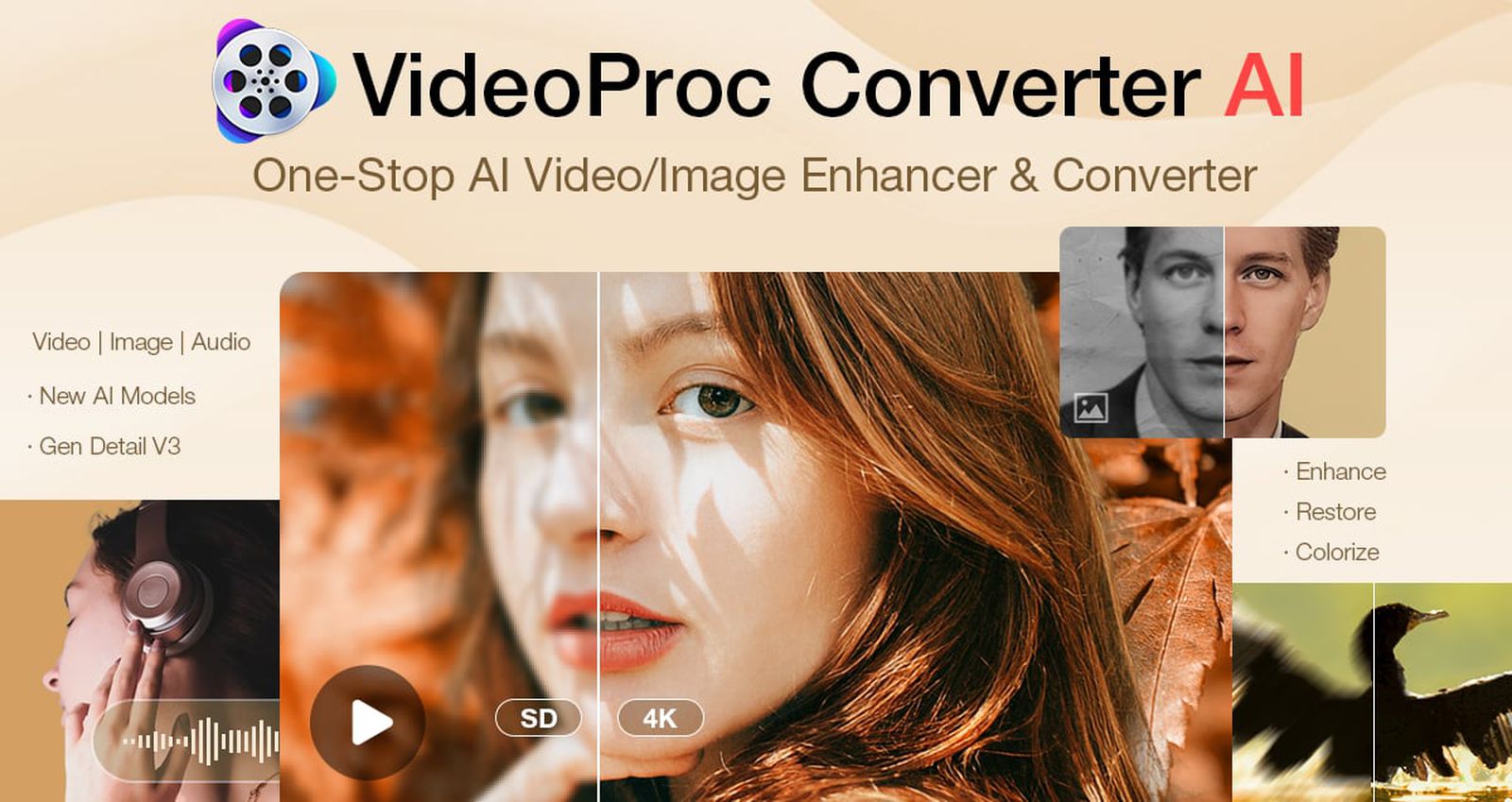




































![Sonos Father's Day Sale: Save Up to 26% on Arc Ultra, Ace, Move 2, and More [Deal]](https://www.iclarified.com/images/news/97469/97469/97469-640.jpg)













































































































.webp?#)


_Delphotos_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































































![[The AI Show Episode 150]: AI Answers: AI Roadmaps, Which Tools to Use, Making the Case for AI, Training, and Building GPTs](https://www.marketingaiinstitute.com/hubfs/ep%20150%20cover.png)
![[The AI Show Episode 149]: Google I/O, Claude 4, White Collar Jobs Automated in 5 Years, Jony Ive Joins OpenAI, and AI’s Impact on the Environment](https://www.marketingaiinstitute.com/hubfs/ep%20149%20cover.png)























































































































































![How to Survive in Tech When Everything's Changing w/ 21-year Veteran Dev Joe Attardi [Podcast #174]](https://cdn.hashnode.com/res/hashnode/image/upload/v1748483423794/0848ad8d-1381-474f-94ea-a196ad4723a4.png?#)































































































This AI Paper from Microsoft Introduces WINA: A Training-Free Sparse Activation Framework for Efficient Large Language Model Inference
Large language models (LLMs), with billions of parameters, power many AI-driven services across industries. However, their massive size and complex architectures make their computational costs during inference a significant challenge. As these models evolve, optimizing the balance between computational efficiency and output quality has become a crucial area of research. The core challenge lies in […] The post This AI Paper from Microsoft Introduces WINA: A Training-Free Sparse Activation Framework for Efficient Large Language Model Inference appeared first on MarkTechPost.

Large language models (LLMs), with billions of parameters, power many AI-driven services across industries. However, their massive size and complex architectures make their computational costs during inference a significant challenge. As these models evolve, optimizing the balance between computational efficiency and output quality has become a crucial area of research.
The core challenge lies in how LLMs handle inference. Every time an input is processed, the entire model is activated, which consumes extensive computational resources. This full activation is unnecessary for most tasks, as only a small subset of neurons contribute meaningfully to the final output. Existing sparse activation methods attempt to address this by selectively deactivating less important neurons. However, these approaches often focus only on the magnitude of hidden states while ignoring the critical role of weight matrices in propagating errors through the network. This oversight leads to high approximation errors and deteriorates model performance, particularly at higher sparsity levels.

Sparse activation techniques have included methods like Mixture-of-Experts (MoE) used in models such as GPT-4 and Mistral, which rely on additional training to learn which experts to activate for each input. Other approaches, such as TEAL and CATS, aim to reduce computation by using the size of hidden activations to prune neurons, but they still leave room for improvement. These methods often struggle with balancing sparsity and accuracy, as they can mistakenly deactivate important neurons or retain those with minimal influence. Moreover, they require model-specific threshold tuning, making them less flexible across different architectures.
Researchers from Microsoft, Renmin University of China, New York University, and the South China University of Technology proposed a new method called WINA (Weight Informed Neuron Activation) to address these issues. WINA introduces a training-free sparse activation technique that uses both hidden state magnitudes and column-wise ℓ2 norms of weight matrices to determine which neurons to activate during inference. By considering the combined impact of input magnitudes and weight importance, WINA creates a more effective sparsification strategy that adapts to different layers of the model without requiring retraining or fine-tuning.

The WINA method is built on a simple yet powerful idea: neurons that have strong activations and large weight magnitudes are more likely to influence downstream computations. To operationalize this, WINA calculates the element-wise product of hidden states and weight norms, selecting the top-K components based on this combined metric. This strategy allows WINA to construct a sparse sub-network that preserves the most important signals while ignoring redundant activations. The method also includes a tensor transformation step that enforces column-wise orthogonality in weight matrices, ensuring theoretical error bounds translate effectively to real-world performance. By combining these steps, WINA maintains a tight approximation error while delivering significant computational savings.
The research team evaluated WINA on several large language models, including Qwen-2.5-7B, LLaMA-2-7B, LLaMA-3-8B, and Phi-4-14B, across various tasks and sparsity levels. WINA outperformed TEAL and CATS across all tested models and sparsity settings. For example, on Qwen-2.5-7B at 65% sparsity, WINA achieved up to 2.94% higher average performance than TEAL and 1.41% better than TEAL-Transform. On LLaMA-3-8B, WINA delivered gains of 1.06% at 50% sparsity and 2.41% at 65% sparsity. Even at high sparsity levels, WINA retained stronger performance on reasoning-intensive tasks like GSM8K and ARC Challenge. WINA also delivered consistent computational savings, reducing floating-point operations by up to 63.7% on LLaMA-2-7B and 62.7% on Phi-4-14B.

In summary, WINA offers a robust, training-free solution for sparse activation in large language models by combining hidden state magnitudes with weight matrix norms. This approach addresses the limitations of prior methods, such as TEAL, resulting in lower approximation errors, improved accuracy, and significant computational savings. The research team’s work represents an important step forward in developing more efficient LLM inference methods that can adapt to diverse models without requiring additional training.
Check out the Paper and GitHub Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post This AI Paper from Microsoft Introduces WINA: A Training-Free Sparse Activation Framework for Efficient Large Language Model Inference appeared first on MarkTechPost.





