

























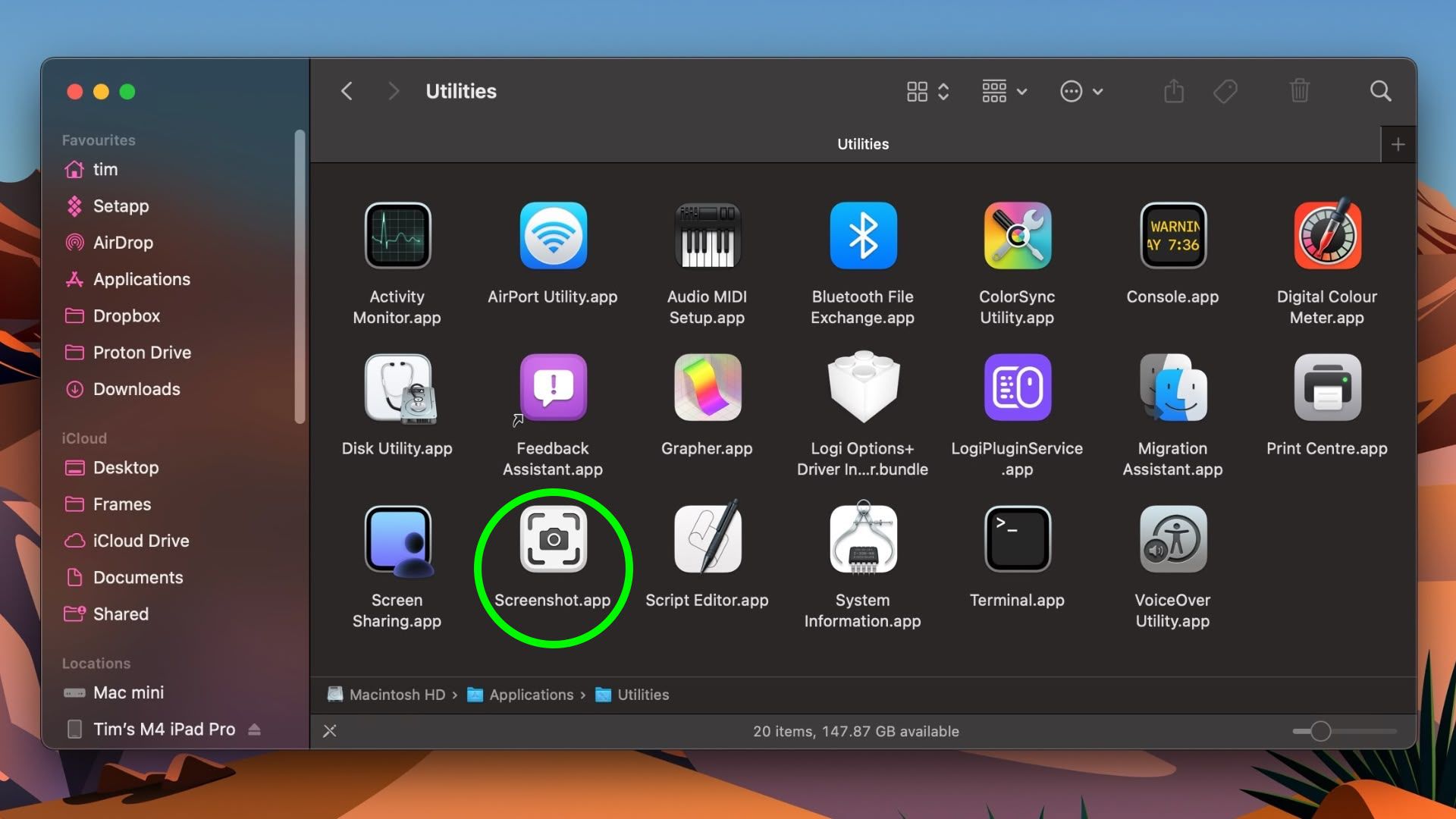







































![WWDC 2025 May Disappoint on AI [Gurman]](https://www.iclarified.com/images/news/97473/97473/97473-640.jpg)


![M4 MacBook Air Hits New All-Time Low of $837.19 [Deal]](https://www.iclarified.com/images/news/97480/97480/97480-640.jpg)





























































































































































































































![[The AI Show Episode 150]: AI Answers: AI Roadmaps, Which Tools to Use, Making the Case for AI, Training, and Building GPTs](https://www.marketingaiinstitute.com/hubfs/ep%20150%20cover.png)
![[The AI Show Episode 149]: Google I/O, Claude 4, White Collar Jobs Automated in 5 Years, Jony Ive Joins OpenAI, and AI’s Impact on the Environment](https://www.marketingaiinstitute.com/hubfs/ep%20149%20cover.png)






































































































































![Z buffer problem in a 2.5D engine similar to monument valley [closed]](https://i.sstatic.net/OlHwug81.jpg)


















































































































What Happens When You Don't Hire Data Scientists
Many organizations focus their data investments to hire data scientists, assuming that analytical talent alone will unlock the value in their data.

The Hidden Costs of Data Engineering Neglect
Many organizations focus their data investments to hire data scientists, assuming that analytical talent alone will unlock the value in their data. This approach consistently leads to disappointment, frustration, and significant opportunity costs. Without proper data engineering infrastructure, even the most talented data scientists find themselves spending 80% of their time on data preparation rather than analysis and insight generation.
The costs of ignoring data engineering are not readily apparent. Systems may function in the short term with small data sets and basic use cases, but issues snowball quickly as data quantities increase and complexities demand more. What begins as small annoyances become significant operational issues that can devastate data initiatives and erode business trust in analytics.
Companies that hire data scientists but don't invest in data engineering end up stuck in a technical debt cycle where every new initiative is more challenging and costly than the previous one, and anticipated business value keeps eluding them.
The Data Quality Nightmare
Without good data engineering principles, data quality is an ongoing issue that negates all analytical endeavors. Inconsistent formatting, missing values, redundant records, and stale data provide a sand foundation that makes sound analysis almost impossible.
Data scientists waste huge amounts of time scrubbing and preparing data per project, repeatedly redoing the same work as there is no central system for keeping track of data quality. Not only does this duplicated effort squander resources, but it introduces inconsistencies when multiple analysts treat the same data differently.
The business consequence is significant. Decision-makers are provided with contradictory reports since various analyses operate on varied data preparation techniques. The confidence in data-driven conclusions deteriorates as stakeholders face inconsistent figures and unreliable data. Key business decisions are delayed as teams waste weeks solving data inconsistency issues.
Scalability Walls and Performance Bottlenecks
Data systems constructed without sound engineering principles reach scalability limits rapidly and unexpectedly. What is perfectly acceptable with thousands of records crashes with millions. Query performance slows exponentially as volumes of data increase, making previously speedy reports excruciating multi-hour experiences.
These performance issues have cascading implications throughout the organization. Real-time dashboards turn into batch reports. Interactive analysis is impossible. Business users become frustrated with slow systems and go back to manual processes or simplified analysis missing vital insights.
Firms that hire data scientists to drive machine learning projects suffer especially from scalability challenges. Models that perform flawlessly in test environments break when deployed in production since the underlying data infrastructure is not designed to address the computational needs of real-world deployments.
Security and Compliance Vulnerabilities
Data engineering is not only about efficiently moving data; it's about securely doing so in accordance with regulatory requirements. Ad-hoc solutions developed by organizations lacking good data engineering practices create serious security risks and compliance hazards.
Sensitive information gets fragmented across several systems with varying access controls. Audit trails become unviable when data flows through ad-hoc processes. Compliance with regulations becomes a nightmare when there is no process-driven mechanism for governance, retention, and deletion of data.
The financial penalties can be substantial. Regulatory penalties, security incidents, and compliance breakdowns usually end up costing many times more than the data engineering investments that could have avoided them. The reputational harm of data mismanagement can affect business relationships and customer trust over the long term.
The Integration Impossibility
Today's companies are built on dozens of disparate systems, each with important information that can lead to improved decision-making. Without effective data engineering, merging these systems is harder and more costly as the number of points of connection expands exponentially.
Point-to-point integrations produce fragile systems that shatter as soon as any piece of it alters. Manual data export and import steps create latency and inaccuracies, rendering real-time decision-making impossible. Important business information is stored in silos, not allowing holistic analysis and strategic insights.
Companies that hire data scientists for end-to-end analytics discover that the inability to integrate capabilities seriously restricts the scope and worth of their analytics. Decisions resulting from partial data lead to incomplete knowledge and second-best decisions.
Innovation Stagnation
Arguably the most serious long-term expense of ignoring data engineering is innovation stalling. Without trustworthy data infrastructure, organizations are unable to try new analytical methods, adopt sophisticated machine learning frameworks, or innovate on how they leverage their data assets.
Data science organizations turn into maintenance shops, dedicating all their energy to keeping current systems running instead of creating new possibilities. Advanced methods such as real-time machine learning, automated decision-making, and intelligent automation remain inaccessible because the underlying infrastructure is not capable of supporting them.
Competitive disadvantages buildup as time goes on as organizations that have adequate data engineering capacity keep moving forward while those that do not are increasingly left behind. It becomes harder to bridge the gap as technical debt piles up and skilled professionals become disenchanted with unproductive systems.
The Cascading Business Impact
The business costs of bad data engineering go far beyond the technical structure. Strategic efforts do not bring promised value. Customer experiences deteriorate from lack of personalization and smart automation. Operative efficiency is stuck because process optimization depends on trustworthy data systems.
Market possibilities are lost because the organization is unable to react fast to shifts in circumstances. Competitive intelligence is limited because full data analysis is too arduous and time-consuming. Innovation cycles are delayed since new ideas can't be tested and proven quickly enough.
Firms that hire data scientists without backing them up with appropriate data engineering capabilities tend to have their analytics spending turn into cost centers instead of value drivers, and organizational doubts regarding data projects that might take years to get over.
The Recovery Challenge
Organizations that recognize their data engineering deficits face significant challenges in recovery. Technical debt accumulated over years can't be resolved quickly. Existing systems must be maintained while new infrastructure is built. Cultural resistance develops when users have been burned by previous data system failures.
Most effective recovery strategies entail disciplined investments in data engineering skills alongside current analytics capabilities. Such a combined effort is resource-intensive and leadership-heavy but ultimately helps organizations unlock the maximum value from their data assets and analytics investments.





