




































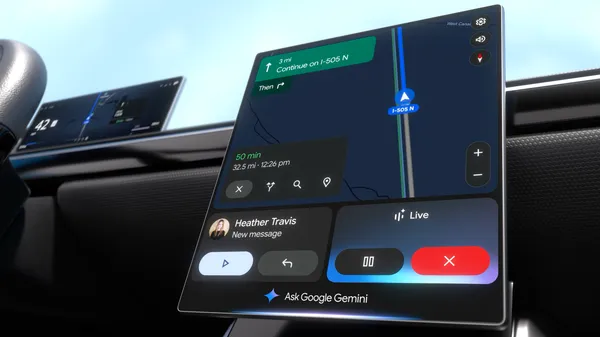








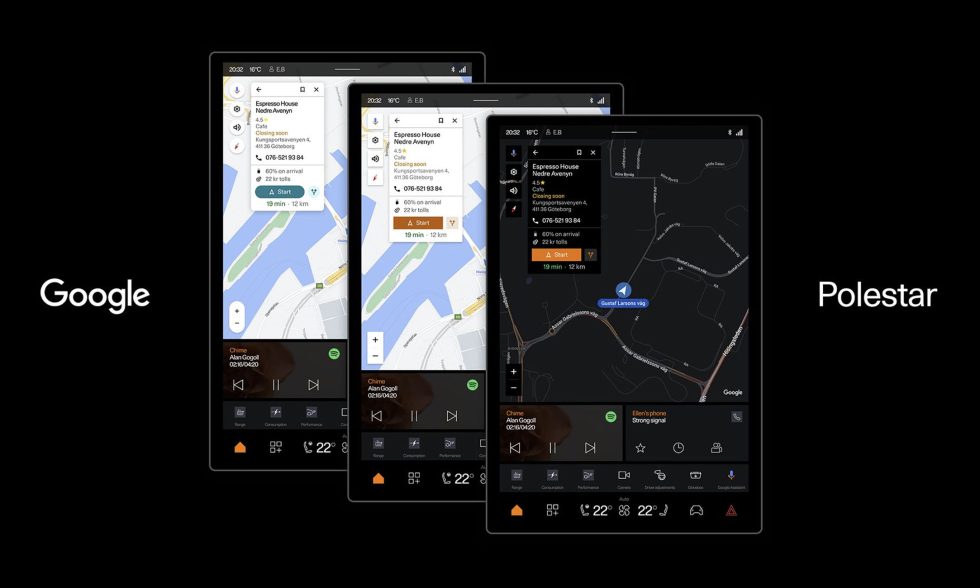
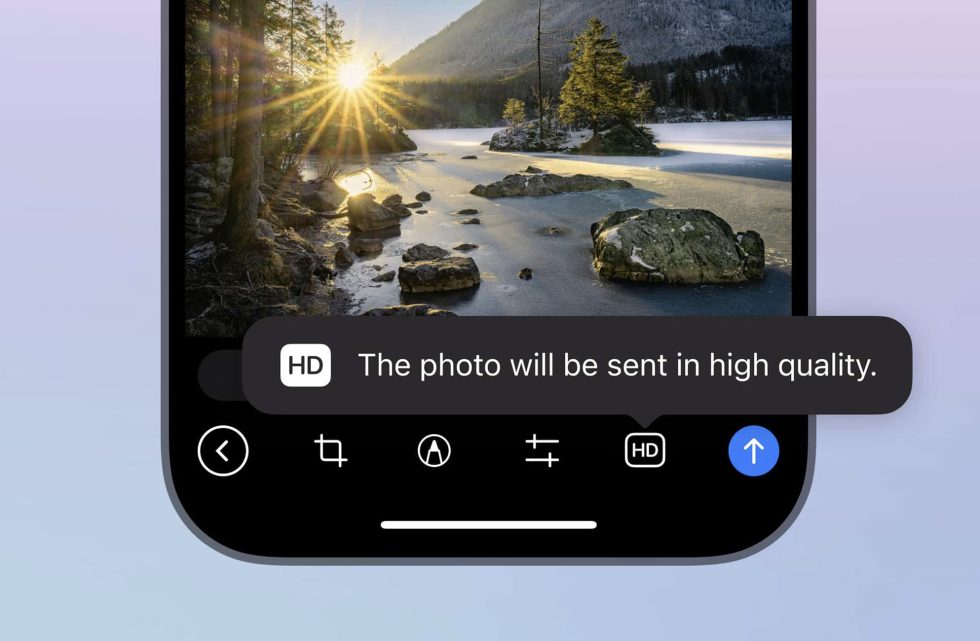











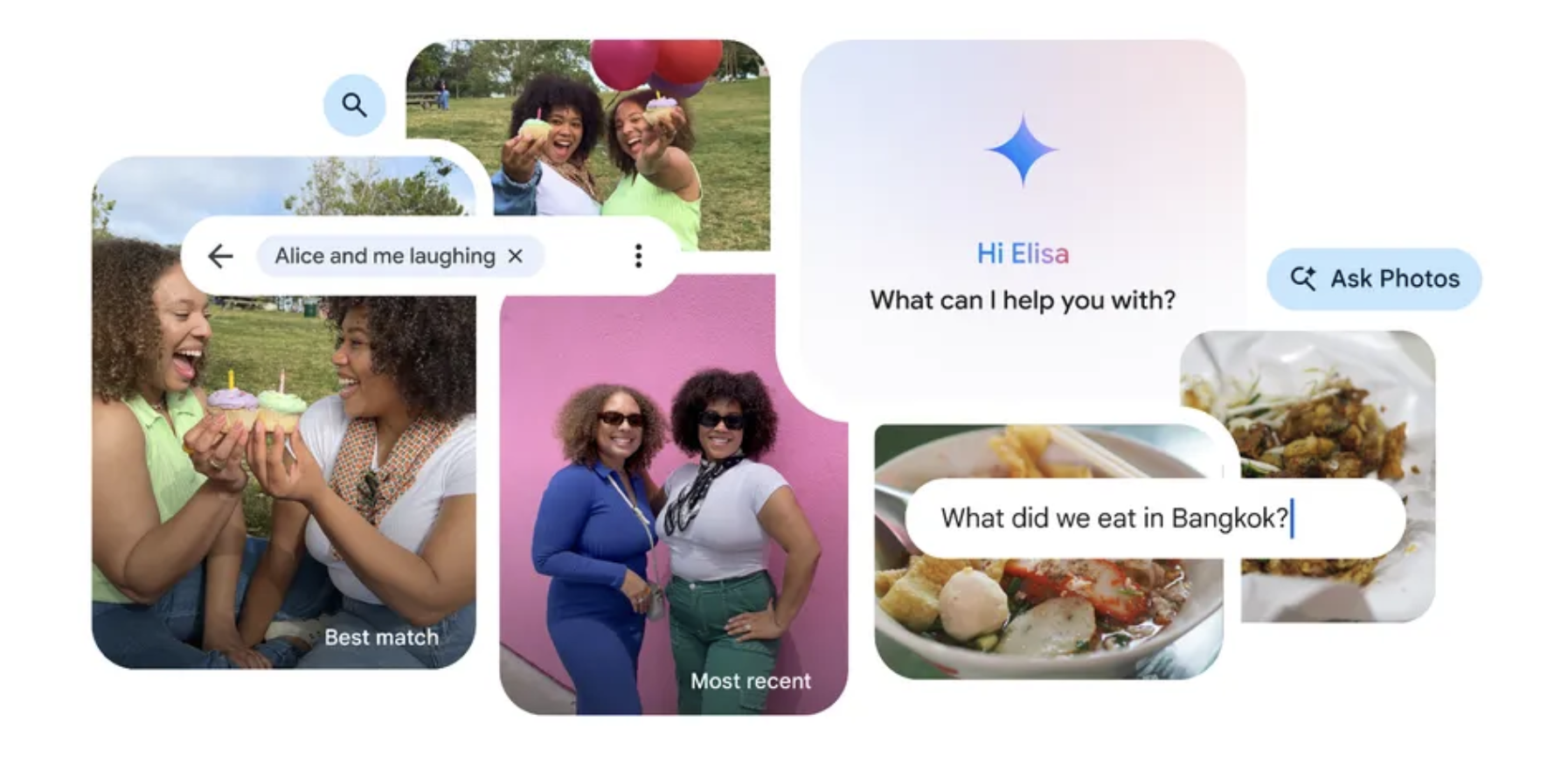



























![Samsung teases Galaxy Z Fold 7 with an absolutely bizarre ‘Ultra experience’ [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/galaxy-z-fold-7-teaser-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















































































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)





















































































































































































































































Vision Transformer on a Budget
Introduction The vanilla ViT is problematic. If you take a look at the original ViT paper [1], you’ll notice that although this deep learning model proved to work extremely well, it requires hundreds of millions of labeled training images to achieve this. Well, that’s a lot. This requirement of an enormous amount of data is definitely […] The post Vision Transformer on a Budget appeared first on Towards Data Science.

Introduction The vanilla ViT is problematic. If you take a look at the original ViT paper [1], you’ll notice that although this deep learning model proved to work extremely well, it requires hundreds of millions of labeled training images to achieve this. Well, that’s a lot. This requirement of an enormous amount of data is definitely […]
The post Vision Transformer on a Budget appeared first on Towards Data Science.





