















































![Standalone Meta AI App Released for iPhone [Download]](https://www.iclarified.com/images/news/97157/97157/97157-640.jpg)









































































































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)


















































































































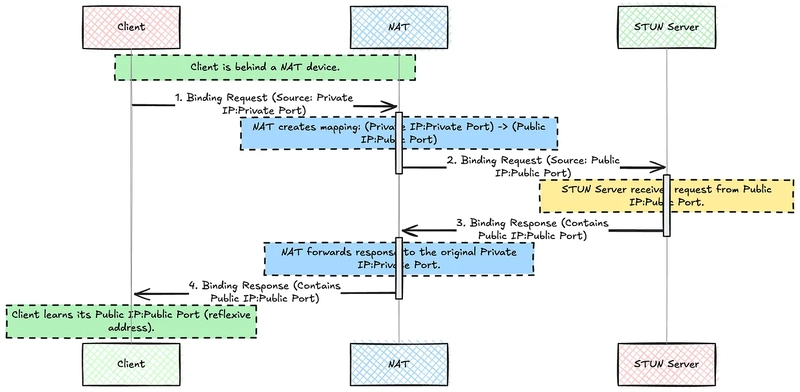















































































































































A Developer’s Guide to Retrieval Augmented Generation (RAG) — How It Actually Works
If you're building AI applications and concerned about outdated knowledge in your models, Retrieval Augmented Generation (RAG) offers a smarter solution. Instead of relying solely on static training data, RAG enables AI systems to retrieve real-time information and generate more contextually accurate outputs. This article breaks down what RAG is, why it's crucial, and how it actually works — especially from a developer’s point of view. Originally published on the Zestminds blog: What is Retrieval Augmented Generation What is Retrieval Augmented Generation (RAG)? At its core, RAG is a hybrid approach that combines: Retrieval: Finding relevant documents from an external knowledge base. Generation: Using a language model (like GPT) to produce coherent and context-rich responses based on the retrieved documents. In short: RAG = Search + Generate Instead of depending only on pre-trained knowledge, the model dynamically pulls information when needed — making outputs more reliable and up-to-date. Why Retrieval Augmented Generation Matters Traditional language models face several challenges: Knowledge cut-off dates restrict their information. Hallucination can occur when they lack verified facts. Static learning means they require costly re-training to update knowledge. RAG solves these problems by allowing models to: Fetch updated, external information dynamically. Reduce hallucination risks. Deliver more accurate and context-aware answers. Stay scalable without frequent re-training cycles. How a Basic RAG System Works Here’s how a typical RAG system handles a user query: User Input: A query or prompt is submitted by the user. Retriever Stage: The system searches a knowledge base or database to find relevant documents using methods like vector search. Passing to Generator: Retrieved documents are fed into a language model along with the original user query. Response Generation: The model uses both the query and retrieved data to produce a final, more accurate answer. Visualizing a Simple RAG Architecture Technologies commonly used: Retrieval: BM25 search, dense vector embeddings (e.g., OpenAI, Hugging Face), vector databases like Pinecone, Weaviate, FAISS. Generation: Language models such as OpenAI GPT-3.5/GPT-4, Meta's LLaMA, Anthropic's Claude. Example Use Case Consider a financial advisory chatbot. Without RAG: It might suggest outdated regulations or products based on stale training data. With RAG: It retrieves the latest financial regulations, product information, or market news — providing users with updated advice. This makes the AI significantly more trustworthy for mission-critical domains. Benefits of Using RAG Real-time knowledge updates Reduced hallucinations Domain adaptability Lower operational costs (compared to re-training) Better user trust and reliability RAG vs Traditional Fine-Tuning: Quick Comparison Feature Fine-Tuning RAG Knowledge Update Requires retraining Dynamic, real-time retrieval Cost High Lower Flexibility Limited High Scalability Challenging Easier Getting Started with RAG Development Here are some tools and libraries to explore if you’re building your own RAG system: Frameworks LangChain (Python) Haystack (Python) Vector Databases Pinecone Weaviate FAISS Language Models OpenAI GPT Hugging Face Transformers LLaMA by Meta Web APIs / Backends FastAPI Flask You can build prototypes that combine these tools to suit your specific domain needs. Final Thoughts Retrieval Augmented Generation is a major advancement in AI. It bridges the gap between static pre-trained models and the dynamic, real-time world we live in. For developers building the next generation of intelligent apps — whether it's in legal tech, health, finance, or SaaS — RAG provides a powerful and scalable framework for delivering more reliable AI outputs. Originally published on Zestminds Blog: What is Retrieval Augmented Generation
If you're building AI applications and concerned about outdated knowledge in your models, Retrieval Augmented Generation (RAG) offers a smarter solution.
Instead of relying solely on static training data, RAG enables AI systems to retrieve real-time information and generate more contextually accurate outputs.
This article breaks down what RAG is, why it's crucial, and how it actually works — especially from a developer’s point of view.
Originally published on the Zestminds blog: What is Retrieval Augmented Generation
What is Retrieval Augmented Generation (RAG)?
At its core, RAG is a hybrid approach that combines:
- Retrieval: Finding relevant documents from an external knowledge base.
- Generation: Using a language model (like GPT) to produce coherent and context-rich responses based on the retrieved documents.
In short:
RAG = Search + Generate
Instead of depending only on pre-trained knowledge, the model dynamically pulls information when needed — making outputs more reliable and up-to-date.
Why Retrieval Augmented Generation Matters
Traditional language models face several challenges:
- Knowledge cut-off dates restrict their information.
- Hallucination can occur when they lack verified facts.
- Static learning means they require costly re-training to update knowledge.
RAG solves these problems by allowing models to:
- Fetch updated, external information dynamically.
- Reduce hallucination risks.
- Deliver more accurate and context-aware answers.
- Stay scalable without frequent re-training cycles.
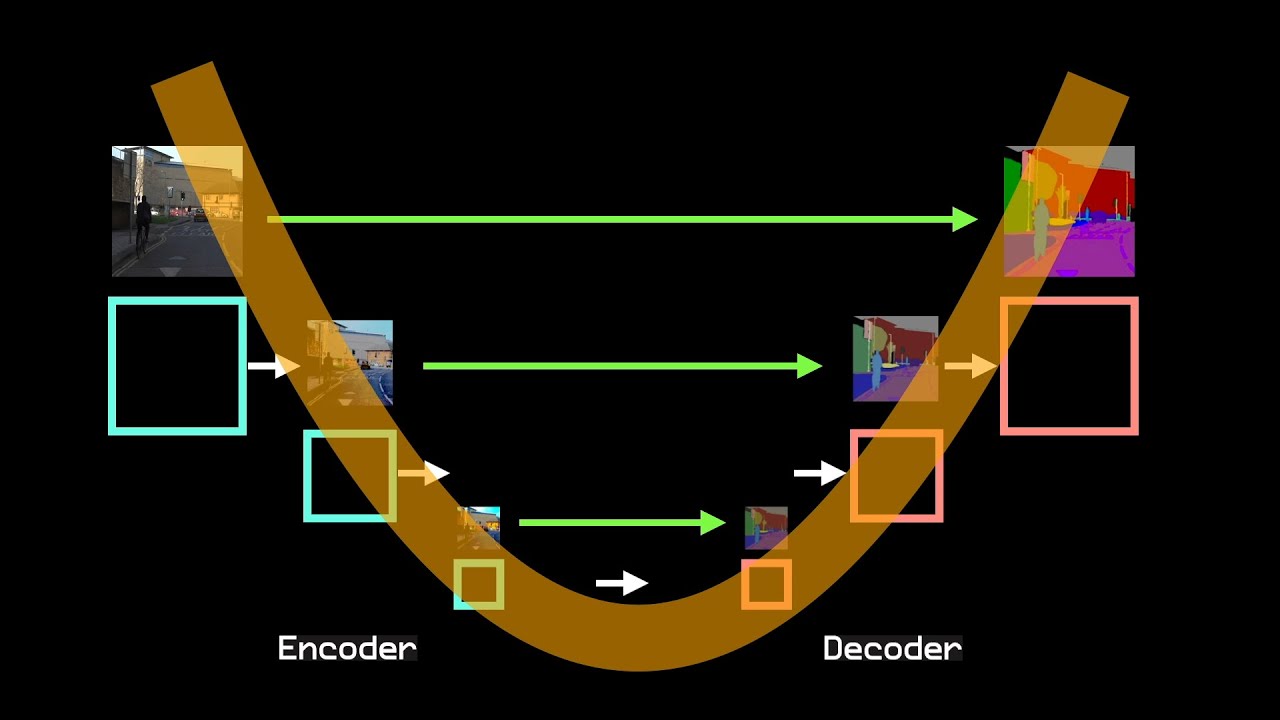
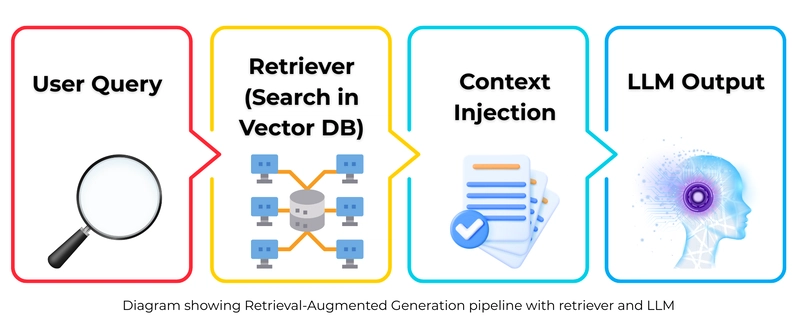
How a Basic RAG System Works
Here’s how a typical RAG system handles a user query:
User Input:
A query or prompt is submitted by the user.Retriever Stage:
The system searches a knowledge base or database to find relevant documents using methods like vector search.Passing to Generator:
Retrieved documents are fed into a language model along with the original user query.Response Generation:
The model uses both the query and retrieved data to produce a final, more accurate answer.
Visualizing a Simple RAG Architecture
Technologies commonly used:
- Retrieval: BM25 search, dense vector embeddings (e.g., OpenAI, Hugging Face), vector databases like Pinecone, Weaviate, FAISS.
- Generation: Language models such as OpenAI GPT-3.5/GPT-4, Meta's LLaMA, Anthropic's Claude.
Example Use Case
Consider a financial advisory chatbot.
Without RAG:
It might suggest outdated regulations or products based on stale training data.
With RAG:
It retrieves the latest financial regulations, product information, or market news — providing users with updated advice.
This makes the AI significantly more trustworthy for mission-critical domains.
Benefits of Using RAG
- Real-time knowledge updates
- Reduced hallucinations
- Domain adaptability
- Lower operational costs (compared to re-training)
- Better user trust and reliability
RAG vs Traditional Fine-Tuning: Quick Comparison
| Feature | Fine-Tuning | RAG |
|---|---|---|
| Knowledge Update | Requires retraining | Dynamic, real-time retrieval |
| Cost | High | Lower |
| Flexibility | Limited | High |
| Scalability | Challenging | Easier |
Getting Started with RAG Development
Here are some tools and libraries to explore if you’re building your own RAG system:
-
Frameworks
- LangChain (Python)
- Haystack (Python)
-
Vector Databases
- Pinecone
- Weaviate
- FAISS
-
Language Models
- OpenAI GPT
- Hugging Face Transformers
- LLaMA by Meta
-
Web APIs / Backends
- FastAPI
- Flask
You can build prototypes that combine these tools to suit your specific domain needs.
Final Thoughts
Retrieval Augmented Generation is a major advancement in AI. It bridges the gap between static pre-trained models and the dynamic, real-time world we live in.
For developers building the next generation of intelligent apps — whether it's in legal tech, health, finance, or SaaS — RAG provides a powerful and scalable framework for delivering more reliable AI outputs.
Originally published on Zestminds Blog: What is Retrieval Augmented Generation