






































































![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)
![Apple Seeds tvOS 18.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97153/97153/97153-640.jpg)
![Apple Releases macOS Sequoia 15.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97155/97155/97155-640.jpg)





































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






























































































































































































































































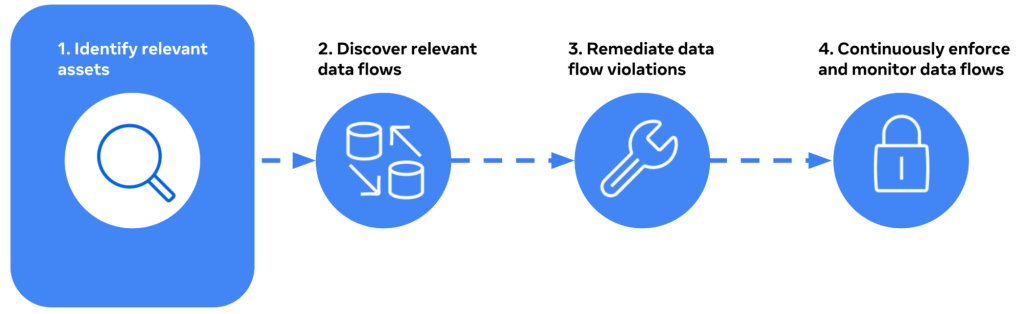
How Meta understands data at scale
Managing and understanding large-scale data ecosystems is a significant challenge for many organizations, requiring innovative solutions to efficiently safeguard user data. Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. To address these challenges, we made substantial investments in advanced data understanding technologies, as part of [...] Read More... The post How Meta understands data at scale appeared first on Engineering at Meta.

- Managing and understanding large-scale data ecosystems is a significant challenge for many organizations, requiring innovative solutions to efficiently safeguard user data. Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale.
- To address these challenges, we made substantial investments in advanced data understanding technologies, as part of our Privacy Aware Infrastructure (PAI). Specifically, we have adopted a “shift-left” approach, integrating data schematization and annotations early in the product development process. We also created a universal privacy taxonomy, a standardized framework providing a common semantic vocabulary for data privacy management across Meta’s products that ensures quality data understanding and provides developers with reusable and efficient compliance tooling.
- We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Meta’s products. Additionally, continuous collaboration between privacy and product teams was essential to unlock the value of data understanding at scale.
- We embarked on the journey of understanding data across Meta a decade ago with millions of assets in scope ranging from structured and unstructured, processed by millions of flows across many of the Meta App offerings. Over the past 10 years, Meta has cataloged millions of data assets and is classifying them daily, supporting numerous privacy initiatives across our product groups. Additionally, our continuous understanding approach ensures that privacy considerations are embedded at every stage of product development.
At Meta, we have a deep responsibility to protect the privacy of our community. We’re upholding that by investing our vast engineering capabilities into building cutting-edge privacy technology. We believe that privacy drives product innovation. This led us to develop our Privacy Aware Infrastructure (PAI), which integrates efficient and reliable privacy tools into Meta’s systems to address needs such as purpose limitation—restricting how data can be used while also unlocking opportunities for product innovation by ensuring transparency in data flows
Data understanding is an early step in PAI. It involves capturing the structure and meaning of data assets, such as tables, logs, and AI models. Over the past decade, we have gained a deeper understanding of our data, by embedding privacy considerations into every stage of product development, ensuring a more secure and responsible approach to data management.
We embarked on our data understanding journey by employing heuristics and classifiers to automatically detect semantic types from user-generated content. This approach has evolved significantly over the years, enabling us to scale to millions of assets. However, conducting these processes outside of developer workflows presented challenges in terms of accuracy and timeliness. Delayed classifications often led to confusion and unnecessary work, while the results were difficult to consume and interpret.
Data understanding at Meta using PAI
To address shortcomings, we invested in data understanding by capturing asset structure (schematization), describing meaning (annotation), and inventorying it into OneCatalog (Meta’s system that discovers, registers, and enumerates all data assets) across all Meta technologies. We developed tools and APIs for developers to organize assets, classify data, and auto-generate annotation code. Despite significant investment, the journey was not without challenges, requiring innovative solutions and collaboration across the organization.
| Challenge | Approach |
| Understanding at scale (lack of foundation)
At Meta, we manage hundreds of data systems and millions of assets across our family of apps. Each product features its own distinct data model, physical schema, query language, and access patterns. This diversity created a unique hurdle for offline assets: the inability to reuse schemas due to the limitations of physical table schemas in adapting to changing definitions. Specifically, renaming columns or making other modifications had far-reaching downstream implications, rendering schema evolution challenging, thus propagation required careful coordination to ensure consistency and accuracy across multiple systems and assets. |
We introduced a shared asset schema format as a logical representation of the asset schema that can be translated back and forth with the system-specific format. Additionally, it offers tools to automatically classify data and send out annotation changes to asset owners for review, effectively managing long-tail systems. |
| Inconsistent definitions (lack of shared understanding)
We encountered difficulties with diverse data systems that store data in various formats, and customized data labels that made it challenging to recognize identical data elements when they are stored across multiple systems. |
We introduced a unified taxonomy of semantic types, which are compiled into different languages. This ensured that all systems can share the same canonical set of labels. |
| Missing annotations (lack of quality)
A solution that relied solely on data scanning and pattern matching was prone to false positives due to limited contextual information. For instance, a 64-bit integer could be misclassified as either a timestamp or a user identifier without additional context. Moreover, manual human labeling is not feasible at scale because it relies heavily on individual developers’ expertise and knowledge. |
We shifted left by combining schematization together with annotations in code, in addition improving and utilizing multiple classification signals. Strict measurements provided precision/recall guarantees. Protection was embedded in everything we built, without requiring every developer to be a privacy expert. |
| Organizational barriers (lack of a unified approach)
Meta’s data systems, with their bespoke schematization and practices, posed significant challenges in understanding data across the company. As we navigated complex interactions and with ever evolving privacy requirements, it became clear that fragmented approaches to data understanding hindered our ability to grasp data comprehensively. |
By collaborating with asset owners to develop intuitive tooling and improve coverage, we tackled adoption barriers such as poor developer experience and inaccurate classification. This effort laid the groundwork for a unified data understanding foundation, which was seamlessly integrated into the developer workflow. As a result, we drove a cultural shift towards reusable and efficient privacy practices, ultimately delivering value to product teams and fostering a more cohesive approach to data management. |
Walkthrough: Understanding user data for the “Beliefs” feature in Facebook Dating
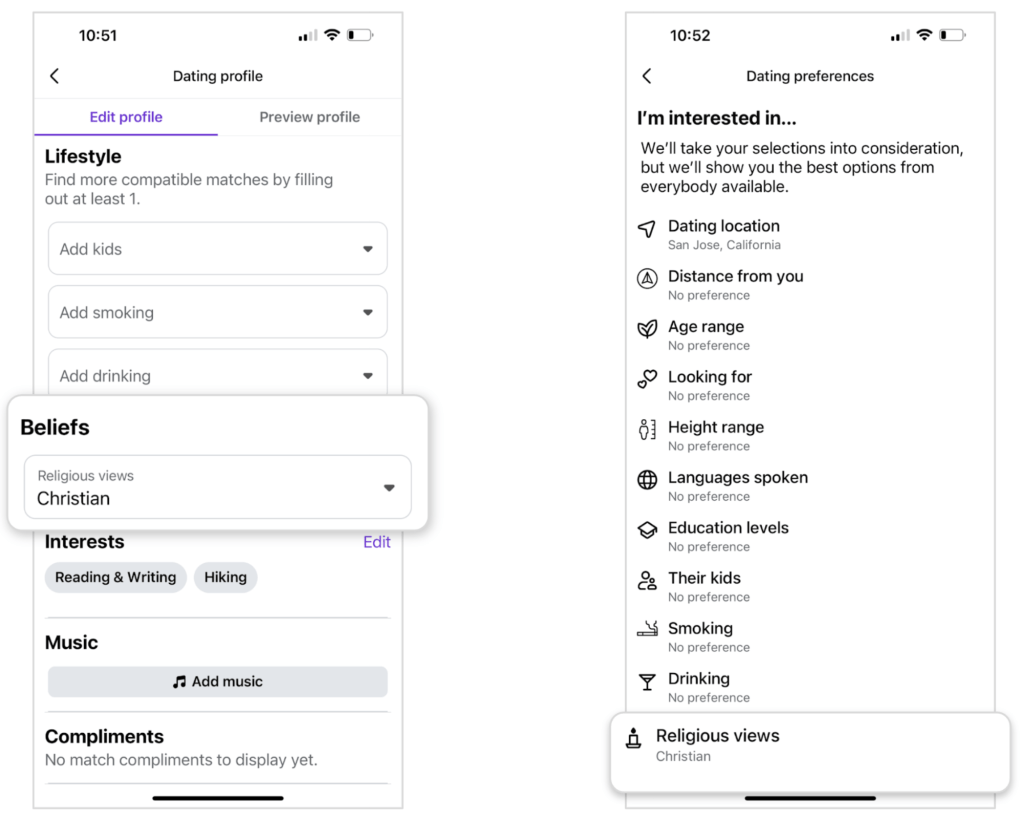
To illustrate our approach and dive into the technical solution, let’s consider a scenario involving structured user data. When creating a profile on the Facebook Dating app, users have the option to include their religious views to help match with others who share similar values.
On Facebook Dating, religious views are subject to purpose limitation requirements. Our five-step approach to data understanding provides a precise, end-to-end view of how we track and protect sensitive data assets, including those related to religious views:

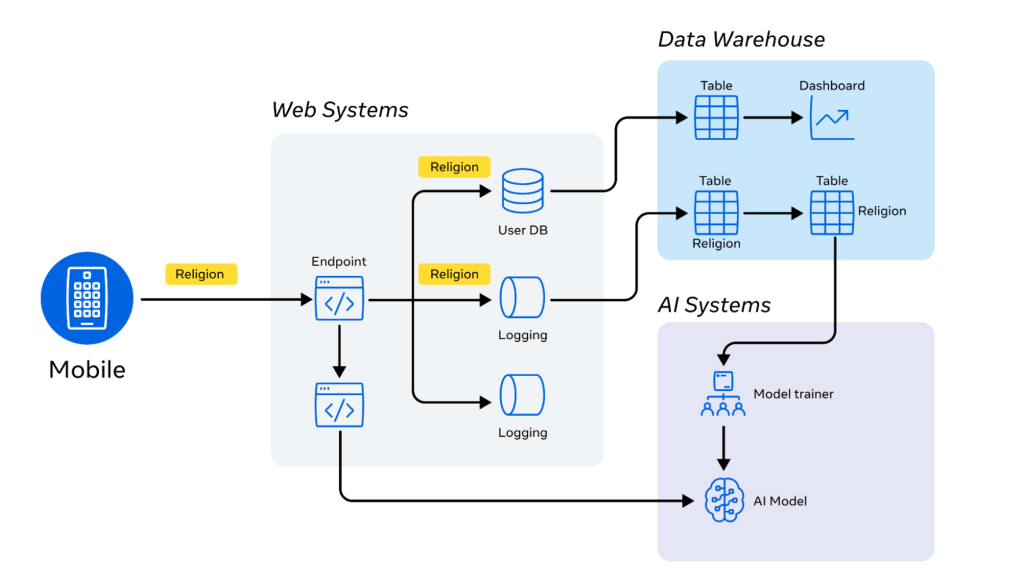
Even a simple feature can involve data being processed by dozens of heterogenous systems, making end-to-end data protection critical. To ensure comprehensive protection, it is essential to apply the necessary steps to all systems that store or process data, including distributed systems (web systems, chat, mobile and backend services) and data warehouses.
Consider the data flow from online systems to the data warehouse, as shown in the diagram below. To ensure that religious belief data is identified across all these systems, we have implemented measures to prevent its use for any purpose other than the stated one.
Step 1 – Schematizing
As part of the PAI initiative, Meta developed DataSchema, a standard format that is used to capture the structure and relationships of all data assets, independent of system implementation. Creating a canonical representation for compliance tools. Understanding DataSchema requires grasping schematization, which defines the logical structure and relationships of data assets, specifying field names, types, metadata, and policies.
Implemented using the Thrift Interface Description Language, DataSchema is compatible with Meta systems and languages. It describes over 100 million schemas across more than 100 data systems, covering granular data units like database tables, key-value stores, data streams from distributed systems (such as those used for logging), processing pipelines, and AI models. Essentially, a data asset is like a class with annotated attributes.
Let’s examine the source of truth (SoT) for a user’s dating profile schema, modeled in DataSchema. This schema includes the names and types of fields and subfields:
- user_id (uint)
- name (string)
- age (uint)
- religious_views (enum)
- photos (array):
- url (url)
- photo (blob)
- caption (string)
- uploaded_date (timestamp)
Dating profile DataSchemaThe canonical SoT schema serves as the foundation for all downstream representations of the dating profile data. In practice, this schema is often translated into system-specific schemas (source of record – “SoR”), optimized for developer experience and system implementation in each environment.
Step 2 – Predicting metadata at scale
Building on this schematization foundation, we used annotations to describe data, enabling us to quickly and reliably locate user data, such as religious beliefs, across Meta’s vast data landscape. This is achieved through a universal privacy taxonomy, a framework that provides a common semantic vocabulary for data privacy management across Meta’s apps. It offers a consistent language for data description and understanding, independent of specific programming languages or technologies.
The universal privacy taxonomy works alongside data classification, which scans systems across Meta’s product family to ensure compliance with privacy policies. These systems use taxonomy labels to identify and classify data elements, ensuring privacy commitments are met and data is handled appropriately according to its classification.
Privacy annotations are represented by taxonomy facets and their values. For example, an asset might pertain to an Actor.Employee, with data classified as SemanticType.Email and originating from DataOrigin.onsite, not a third party. The SemanticType annotation is our standard facet for describing the meaning, interpretation, or context of data, such as user names, email addresses, phone numbers, dates, or locations.
Below, we illustrate the semantic type taxonomy node for our scenario, Faith Spirituality:

As data models and collected data evolve, annotations can become outdated or incorrect. Moreover, new assets may lack annotations altogether. To address this, PAI utilizes various techniques to continuously verify our understanding of data elements and maintain accurate, up-to-date annotations:
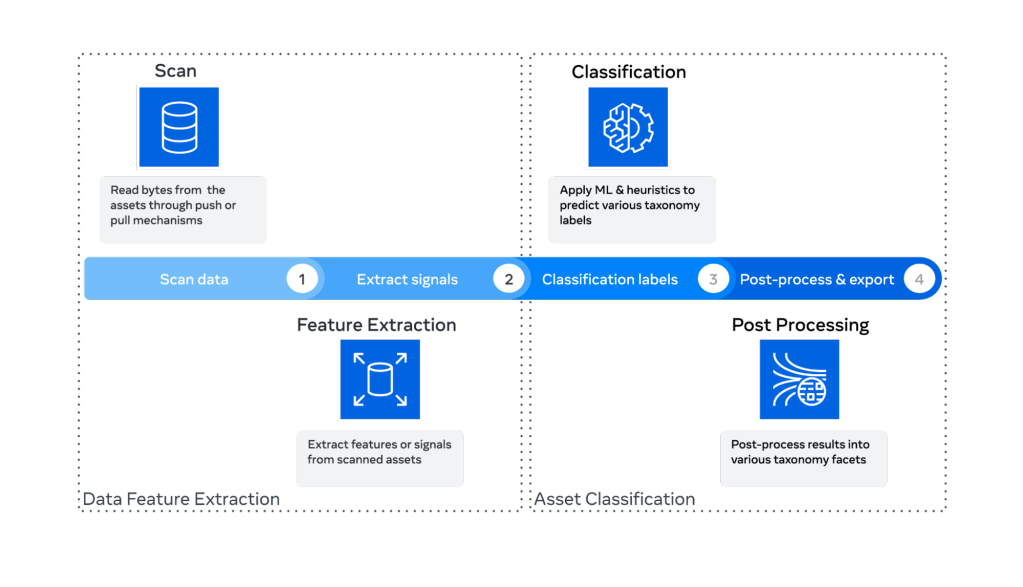
Our classification system leverages machine learning models and heuristics to predict data types by sampling data, extracting features, and inferring annotation values. Efficient data sampling, such as Bernoulli sampling, and processing techniques enable scaling to billions of data elements with low-latency classifications.
Key components include:
- Scheduling component: manages the set of data assets to scan, accommodating different data system architectures by either pulling data via APIs or receiving data pushed directly into the scanning service.
- Scanning service: processes and analyzes data from various sources by accumulating samples in memory, deserializing rows (e.g., JSON) into fields and sub-fields, and extracting features using APIs available in multiple languages (C++, Python, Hack). It ensures comprehensive data capture, even for ephemeral data.
- Classification service: utilizes heuristic rules and machine learning models to classify data types with high accuracy.
- Heuristic rules: handle straightforward, deterministic cases by identifying specific data formats like dates, phone numbers, and user IDs.
- Machine learning models: trained on labeled datasets using supervised learning and improved through unsupervised learning to identify patterns and anomalies in unlabeled data.
- Ground truth calibration and verification: ensures system accuracy and reliability, allowing for model fine-tuning and improved classification performance.
- Lineage and propagation: We integrate classification rules with high-confidence lineage signals to ensure accurate data tracking and management. Our propagation mechanism enables the seamless annotation of data as needed, ensuring that exact copies of data across systems receive equivalent classification. This approach not only maintains data integrity but also optimizes the developer experience by streamlining the process of managing data classifications across our diverse systems.
Step 3 – Annotating
The integration of metadata predictions and developer input creates a comprehensive picture of a data asset’s structure (schema) and its meaning (annotation). This is achieved by attaching these elements to individual fields in data assets, providing a thorough understanding of the data.
Building on the predicting data at scale initiative (step 2), where we utilize the universal privacy taxonomy and classification systems to identify and classify data elements, the generated metadata predictions are then used to help developers annotate their data assets efficiently and correctly.
Portable annotation APIs: seamlessly integrate into developer workflows ensuring:
- Consistent representation of data across all systems at Meta.
- Accurate understanding of data, enabling the application of privacy safeguards at scale.
- Efficient evidencing of compliance with regulatory requirements.
Metadata predictions and developer input: Two key components work together to create a comprehensive data asset picture:
- Metadata predictions: Classifiers generate predictions to aid developers in annotating data assets efficiently and correctly. If the confidence score exceeds a certain threshold, assignment can be automated, saving developer time.
- Developer input: Developers manually refine and verify annotations, ensuring that the data’s context and privacy requirements are accurately captured. Human oversight guarantees the accuracy and reliability of the data asset picture.
- user_id (enum) → SemanticType::id_userID
- name (string) → SemanticType::identity_name
- age (uint) → SemanticType::age
- religious_views (enum) → SemanticType::faithSpirituality
- photos (array):
- url (url) → SemanticType::electronicID_uri_mediaURI_imageURL
- photo (blob) → SemanticType::media_image
- caption (string) → SemanticType::media_text_naturalLanguageText
- uploaded_date (timestamp) → SemanticType::uploadedTime
Ensuring complete schemas with annotations: To maintain a high standard of data understanding, we have integrated data understanding into our data model lifecycle. This includes auto-generating code to represent the schema of newly created assets when missing, ensuring that no new assets are created without a proper schema.
For example, in the context of our religious beliefs in Facebook Dating, we have defined its structure, including fields like ‘Name,’ ‘EmailAddress,’ and ‘Religion.’ Furthermore, we have annotated the asset with Actor::user(), signifying that the data pertains to a user of our products. This level of detail enables us to readily identify fields containing privacy-related data and implement appropriate protective measures, such as applying the applicable purpose limitation policy.
In the case of the “dating profile” data asset, we have defined its structure, including fields like ‘Name’:
final class DatingProfileSchema extends DataSchemaDefinition {
<<__Override>>
public function configure(ISchemaConfig $config): void {
$config->metadataConfig()->description('Represents a dating profile);
$config->annotationsConfig()->annotations(Actor::user());
}
<<__Override>>
public function getFields(): dict {
return dict[
'Name' => StringField::create("name")
->annotations(SemanticType::identity_name())
->example('John Doe'),
'Age' => StringInt::create('age')
->description(“The age of the user.”)
->annotations(SemanticType::age())
->example('24'),
'ReligiousViews' => EnumStringField::create('religious_views')
->annotations(SemanticType::faithSpirituality())
->example('Atheist'),
];
}
}
In order to optimize for developer experience, the details of the schema representation differ in each environment. For example, in the data warehouse, it’s represented as a Dataset – an in-code Python class capturing the asset’s schema and metadata. Datasets provide a native API for creating data pipelines.
Here is an example of such a schema:
@hive_dataset(
"dim_all_dating_users", // table name
"dating", // namespace
oncall="dating_analytics",
description="This is the primary Dating user dimension table containing one row per Dating user per day along with their profile, visitation, and key usage information.",
metadata=Metadata(Actor.User),
)
class dim_all_dating_users(DataSet):
ds: Varchar = Partition("datestamp")
userid: DatingUserID = Column("User id of the profile")
email: EmailAddress = Column("User's email address"),
age: PersonAge = Column("User's stated age on date ds")
religious_views: ReligionOptions = Column("User's provided religious views")
Our warehouse schema incorporates rich types, a privacy-aware type system designed to enhance data understanding and facilitate effective data protection. Rich types, such as DatingUserID, EmailAddress, PersonAge, and ReligionOptions, are integrated into the schema, offering a comprehensive approach to data management while encoding privacy metadata. They provide a developer-friendly way to annotate data and enable the enforcement of data quality rules and constraints at the type level, ensuring data consistency and accuracy across the warehouse. For instance, they can detect issues like joining columns with different types of user IDs or mismatched enums before code execution.
Here is an example definition:
ReligionOptions = enum_from_items(
"ReligionOptions",
items=[
EnumItem("Atheist", "Atheist"),
EnumItem("Buddhist", "Buddhist"),
EnumItem("Christian", "Christian"),
EnumItem("Hindu", "Hindu"),
EnumItem("Jewish", "Jewish"),
EnumItem("Muslim", "Muslim"),
...
],
annotations=(SemanticType.faithSpirituality,),
)
Step 4 – Inventorying assets and systems
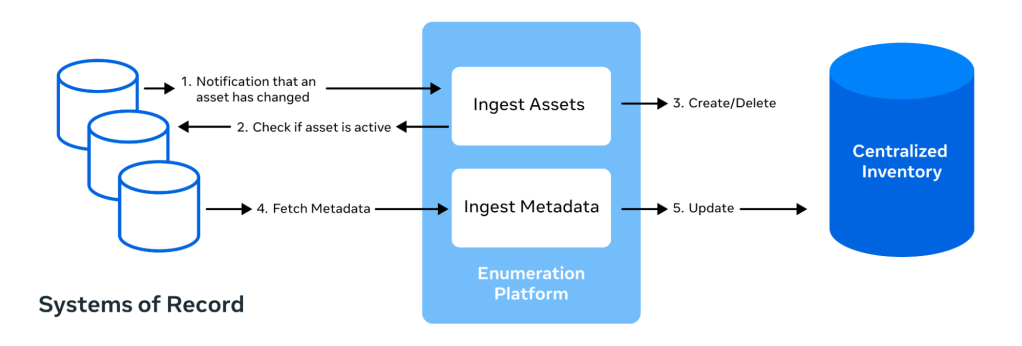
A central inventory system is crucial for managing data assets and their metadata, offering capabilities like search and compliance tracking. Meta’s OneCatalog is a comprehensive system that discovers, registers, and enumerates all data assets across Meta’s apps, providing inventory for easier management and tracking.
Key functions of OneCatalog:
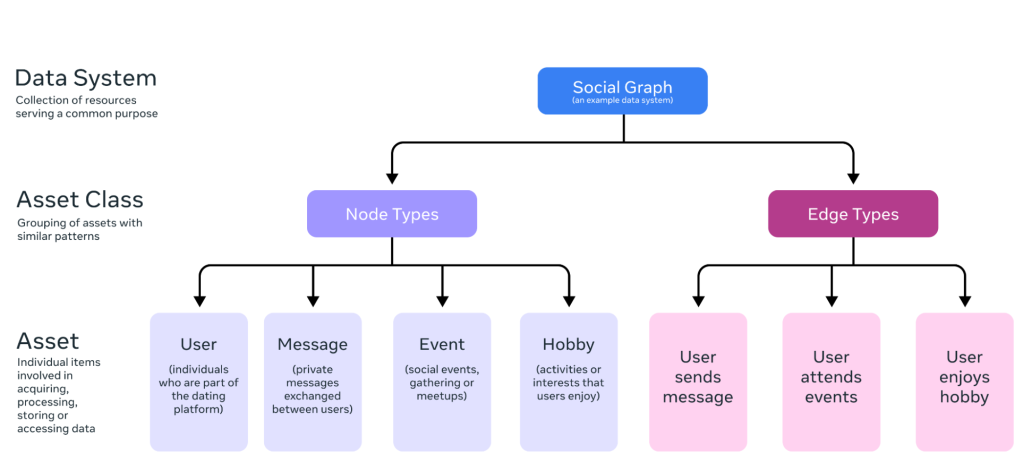
- Registering all data systems: OneCatalog defines a data system as a logical abstraction over resources that persist data for a common purpose. It exhaustively examines resources across Meta’s environments to discover and register all data systems hosting data assets.
- Enumerating all data assets: Eligible data systems must enumerate their assets through the asset enumeration platform, generating a comprehensive list of assets and their metadata in the central inventory. These assets are grouped by “asset classes” based on shared patterns, enabling efficient management and understanding of data assets.
Guarantees provided by OneCatalog:
Completeness: The system regularly checks for consistency between the data defined in its configuration and the actual data stored in the inventory. This ongoing comparison ensures that all relevant data assets are accurately accounted for and up-to-date.
Freshness: In addition to regularly scheduled pull-based enumeration, the system subscribes to changes in data systems and updates its inventory in real time.
Uniqueness of asset ID (XID): Each asset is assigned a globally unique identifier, similar to URLs, which facilitates coordination between multiple systems and the exchange of information about assets by providing a shared key. The globally unique identifier follows a human-readable structure, e.g., asset://[asset-class]/[asset-name].
Unified UI: On top of the inventory, OneCatalog provides a unified user interface that consolidates all asset metadata, serving as the central hub for asset information. This interface offers a single point of access to view and manage assets, streamlining the process of finding and understanding data.
For example, in the context of our “religious beliefs in the Dating app” scenario, we can use OneCatalog’s unified user interface to view the warehouse dating profile table asset, providing a comprehensive overview of its metadata and relationships.

Compliance and privacy assurance: OneCatalog’s central inventory is utilized by various privacy teams across Meta to ensure that data assets meet requirements. With its completeness and freshness guarantees, OneCatalog serves as a reliable source of truth for privacy and compliance efforts.
By providing a single view of all data assets, OneCatalog enables teams to efficiently identify and address potential risks or vulnerabilities, such as unsecured data or unauthorized access.
Step 5 – Maintaining data understanding
To maintain high coverage and quality of schemas and annotations across Meta’s diverse apps, we employed a robust process that involves measuring precision and recall for both predicted metadata and developer-provided annotations. This enables us to guide the implementation of our privacy and security controls and ensure their effectiveness.
By leveraging data understanding, tooling can quickly build end-to-end compliance solutions. With schema and annotations now front and center, we’ve achieved continuous understanding, enabling our engineers to easily track and protect user data, implement various security and privacy controls, and build new features at scale.
Our strategy for maintaining data understanding over time includes:
- Shifting left on creation time: We provided intuitive APIs for developers to provide metadata at asset creation time, ensuring that schemas and annotations were applied consistently in downstream use cases.
- Detecting and fixing annotation gaps: We surfaced prediction signals to detect coverage and quality gaps and evolved our prediction and annotation capabilities to ensure new systems and workflows were covered.
- Collecting ground truth: We established a baseline to measure automated systems against, with the help of subject matter experts, to continuously measure and improve them.
- Providing canonical consumption APIs: We developed canonical APIs for common compliance usage patterns, such as detecting user data, to ensure consistent interpretation of metadata and low entry barriers.
Putting it all together
Coming back to our scenario: As developers on the Facebook Dating team collect or generate new data, they utilize familiar APIs that help them schematize and annotate their data. These APIs provide a consistent and intuitive way to define the structure and meaning of the data.
When collecting data related to “Faith Spirituality,”the developers use a data classifier that confirms their semantic type annotations once the data is scanned during testing. This ensures that the data is accurately labeled and can be properly handled by downstream systems.
To ensure the quality of the classification system, ground truth created by subject matter experts is used to measure its accuracy. A feedback loop between the product and PAI teams keeps the unified taxonomy updated, ensuring that it remains relevant and effective.
By using canonical and catalogued metadata, teams across Meta can implement privacy controls that are consistent and effective. This enables the company to maintain user trust and meet requirements.
In this scenario, the developers on the Facebook Dating team are:
- Schematizing and annotating their data using familiar APIs.
- Using a data classifier to confirm semantic type annotations.
- Leveragig ground truth to measure the quality of the classification system.
- Utilizing a feedback loop to keep the unified taxonomy updated.
- Implementing privacy controls using canonical and catalogued metadata.
Learnings and takeaways
Building an understanding of all data at Meta was a monumental effort that not only required novel infrastructure but also the contribution of thousands of engineers across all teams at Meta, and years of investment.
- Canonical everything: Data understanding at scale relies on a canonical catalog of systems, asset classes, assets, and taxonomy labels, each with globally unique identifiers. This foundation enables an ecosystem of compliance tooling, separating the concerns of data understanding from consuming canonical metadata.
- Incremental and flexible approach: To tackle the challenge of onboarding hundreds of systems across Meta, we developed a platform that supports pulling schemas from existing implementations. We layered solutions to enhance existing untyped APIs, meeting developers where they are—whether in code, configuration, or a UI defining their use case and data model. This incremental and flexible approach delivers value at every step.
- Collaborating for data classification excellence: Building the platform was just the beginning. The infrastructure and privacy teams also collaborated with subject matter experts to develop best-in-class classifiers for our data, addressing some of the most challenging problems. These include detecting user-generated content, classifying data embedded in blobs, and creating a governed taxonomy that allows every developer to describe their data with the right level of detail.
- Community engagement with a tight feedback loop: Our success in backfilling schemas and integrating with the developer experience was made possible by a strong partnership with product teams. By co-building solutions and establishing an immediate feedback loop, we refined our approach, addressed misclassifications, and improved classification quality. This collaboration is crucial to our continued evolution and refinement of data understanding.
The future of data understanding
Data understanding has become a crucial component of Meta’s PAI initiative, enabling us to protect user data in a sustainable and effective manner. By creating a comprehensive understanding of our data, we can address privacy challenges durably and more efficiently than traditional methods.
Our approach to data understanding aligns closely with the developer workflow, involving the creation of typed data models, collection of annotated data, and processing under relevant policies. At Meta’s scale, this approach has saved significant engineering effort by automating annotation on millions of assets (i.e., fields, columns, tables) with specific labels from an inventory that are deemed commitment-critical. This automation has greatly reduced the manual effort required for annotation, allowing teams to focus on higher-priority tasks.
As data understanding continues to evolve, it is expected to have a significant impact on various aspects of operations and product offerings. Here are some potential future use cases:
- Improved AI and machine learning: leveraging data understanding to improve the accuracy of AI-powered content moderation and recommendation systems.
- Streamlined developer workflows: integrating data understanding into Meta’s internal development tools to provide clear data context and reduce confusion.
- Operational and developer efficiency: By automating data classification and annotation for millions of assets across Meta’s platforms, we can significantly improve operational efficiency. This automation enables us to leverage metadata for various use cases, such as accelerating product innovation. For instance, we’re now utilizing this metadata to help developers efficiently find the right data assets, streamlining their workflow and reducing the time spent on manual searches.
- Product innovation: With a comprehensive understanding of data, Meta can drive product innovation by leveraging insights to create personalized and engaging user experiences.
While there is still more work to be done, such as evolving taxonomies to meet future compliance needs and developing novel ways to schematize data, we are excited about the potential of data understanding. By harnessing canonical metadata, we can deepen our shared understanding of data, unlocking unprecedented opportunities for innovation not only at Meta, but across the industry.
Acknowledgements
The authors would like to acknowledge the contributions of many current and former Meta employees who have played a crucial role in developing data understanding over the years. In particular, we would like to extend special thanks to (in alphabetical order) Adrian Zgorzalek, Alex Gorelik, Alex Uslontsev, Andras Belokosztolszki, Anthony O’Sullivan, Archit Jain, Aygun Aydin, Ayoade Adeniyi, Ben Warren, Bob Baldwin, Brani Stojkovic, Brian Romanko, Can Lin, Carrie (Danning) Jiang, Chao Yang, Chris Ventura, Daniel Ohayon, Danny Gagne, David Taieb, Dong Jia, Dong Zhao, Eero Neuenschwander, Fang Wang, Ferhat Sahinkaya, Ferdi Adeputra, Gayathri Aiyer, George Stasa, Guoqiang Jerry Chen, Haiyang Han, Ian Carmichael, Jerry Pan, Jiang Wu, Johnnie Ballentyne, Joanna Jiang, Jonathan Bergeron, Joseph Li, Jun Fang, Kaustubh Karkare, Komal Mangtani, Kuldeep Chaudhary, Matthieu Martin, Marc Celani, Max Mazzeo, Mital Mehta, Nevzat Sevim, Nick Gardner, Lei Zhang, Luiz Ribeiro, Oliver Dodd, Perry Stoll, Prashanth Bandaru, Piyush Khemka, Rahul Nambiar, Rajesh Nishtala, Rituraj Kirti, Roger (Wei) Li, Rujin Cao, Sahil Garg, Sean Wang, Satish Sampath, Seth Silverman, Shridhar Iyer, Sriguru Chakravarthi, Sushaant Mujoo, Susmit Biswas, Taha Bekir Eren, Tony Harper, Vineet Chaudhary, Vishal Jain, Vitali Haravy, Vlad Fedorov, Vlad Gorelik, Wolfram Schuttle, Xiaotian Guo, Yatu Zhang, Yi Huang, Yuxi Zhang, Zejun Zhang and Zhaohui Zhang. We would also like to express our gratitude to all reviewers of this post, including (in alphabetical order) Aleksandar Ilic, Avtar Brar, Brianna O’Steen, Chloe Lu, Chris Wiltz, Imogen Barnes, Jason Hendrickson, Rituraj Kirti, Xenia Habekoss and Yuri Claure. We would like to especially thank Jonathan Bergeron for overseeing the effort and providing all of the guidance and valuable feedback, and Ramnath Krishna Prasad for pulling required support together to make this blog post happen.
The post How Meta understands data at scale appeared first on Engineering at Meta.
