






































































![iOS 18 Adoption Reaches 82% [Chart]](https://www.iclarified.com/images/news/97512/97512/97512-640.jpg)
![Apple Shares Official Trailer for 'The Wild Ones' [Video]](https://www.iclarified.com/images/news/97515/97515/97515-1280.jpg)




























































































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)
















































































































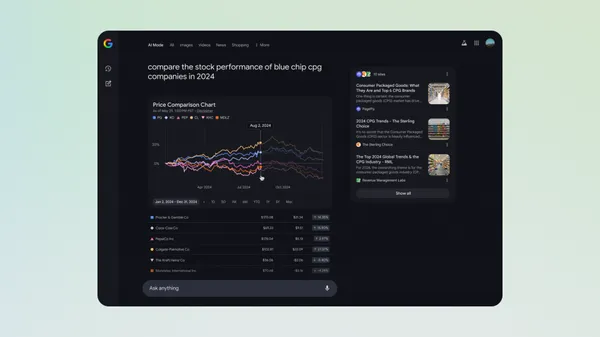


































































-0-8-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
































































Beyond the Notebook: Hire Data Scientists Who Get DevOps
Modern businesses need to hire data scientists who understand DevOps practices, not just analytics. This guide reveals why DevOps-savvy data scientists deliver better results and how to find talent that bridges the gap between data science and production-ready solutions.

The Evolution of Data Science: From Research to Production
The data science landscape has transformed dramatically over the past decade. Gone are the days when data scientists could work in isolation, crafting elegant models in Jupyter notebooks without considering how their work integrates into production systems. Today's competitive environment demands professionals who understand the entire data pipeline, from development to deployment and monitoring.
Companies that hire data scientists with traditional academic backgrounds often discover a significant gap between proof-of-concept models and scalable, production-ready solutions. The most successful organizations now prioritize candidates who combine analytical expertise with operational awareness, creating a new breed of data professionals who speak both Python and DevOps.
The Production Gap Challenge
Research from industry surveys indicates that over 87% of data science projects never make it to production. This startling statistic reflects the disconnect between model development and deployment capabilities. When you hire data scientists who understand DevOps principles, you dramatically increase the likelihood of successful project implementation and business value creation.
What makes a DevOps-ready data scientist valuable?
DevOps-ready data scientists understand containerization, CI/CD pipelines, version control, and infrastructure as code. They can deploy models, monitor performance, and collaborate effectively with engineering teams, ensuring data science projects reach production successfully rather than remaining isolated notebook experiments.
Understanding DevOps Culture in Data Science Context
DevOps culture emphasizes collaboration, automation, and continuous integration between development and operations teams. For data scientists, this means thinking beyond model accuracy to consider scalability, maintainability, and operational efficiency. The shift requires professionals who view their work as part of a larger system rather than standalone research projects.
Modern data teams operate with shared responsibility for the entire machine learning lifecycle. When you hire data scientists with DevOps mindset, you gain professionals who consider deployment challenges during model development, leading to more robust and maintainable solutions.
Key DevOps Principles for Data Scientists
Successful integration of DevOps practices in data science requires understanding of automated testing, continuous integration, and infrastructure management. These principles ensure that analytical work translates into reliable business solutions rather than experimental prototypes.
Essential DevOps Skills for Modern Data Scientists
The technical skill set for DevOps-enabled data scientists extends well beyond traditional statistical analysis and machine learning frameworks. These professionals must navigate containerization technologies, understand cloud infrastructure, and implement monitoring solutions that ensure model performance in production environments.
Version control systems like Git become crucial tools for managing not just code, but also data, models, and experimental configurations. When you hire data scientists with these capabilities, you ensure seamless collaboration between data and engineering teams, reducing friction in the development process.
Containerization and Orchestration
Docker and Kubernetes have become essential tools for deploying machine learning models at scale. Data scientists who understand containerization can package their work in reproducible environments, eliminating the common "it works on my machine" problem that plagues many data science projects.
CI/CD Pipeline Integration
Continuous integration and deployment pipelines automate the testing and deployment of machine learning models, ensuring consistent quality and reducing manual errors. Data scientists familiar with tools like Jenkins, GitLab CI, or GitHub Actions can integrate their work into broader development workflows seamlessly.
Building Cross-Functional Teams: Data Science Meets Engineering
The most successful data science initiatives emerge from close collaboration between analytical and engineering teams. Organizations that hire data scientists with appreciation for engineering practices create environments where innovation thrives alongside operational excellence. This collaboration reduces the time from model development to business impact.
Cross-functional teams eliminate traditional silos that often separate data science from production systems. When data scientists understand engineering constraints and engineers appreciate analytical requirements, projects move more efficiently from conception to deployment.
Communication and Collaboration Skills
Technical skills alone aren't sufficient for DevOps-enabled data scientists. These professionals must communicate effectively with diverse stakeholders, translate business requirements into technical solutions, and work collaboratively in agile development environments.
Evaluating DevOps Readiness in Data Science Candidates
When you hire data scientists, traditional interview processes often miss crucial DevOps competencies. Effective evaluation requires assessing both analytical capabilities and operational awareness through practical scenarios that mirror real-world deployment challenges.
Look for candidates who discuss model deployment considerations during technical interviews, demonstrate understanding of production constraints, and show experience with collaborative development practices. These indicators suggest professionals who can bridge the gap between research and implementation.
Practical Assessment Strategies
Design interview challenges that require candidates to consider the full machine learning lifecycle, from data ingestion to model monitoring. Ask about their experience with version control, automated testing, and deployment strategies to gauge their readiness for production environments.
Infrastructure as Code for Data Science Teams
Modern data science operations benefit significantly from infrastructure as code practices, allowing teams to version control and automate their computational environments. When you hire data scientists familiar with tools like Terraform or CloudFormation, you enable reproducible and scalable data operations.
Infrastructure as code eliminates environment inconsistencies that often cause models to behave differently between development and production systems. This approach ensures that analytical work remains consistent across different deployment scenarios.
Cloud-Native Data Science
Cloud platforms offer sophisticated services for machine learning deployment and monitoring. Data scientists who understand cloud-native architectures can leverage managed services, auto-scaling capabilities, and integrated monitoring tools to build more robust solutions.
Monitoring and Observability in Production ML Systems
Production machine learning systems require continuous monitoring to detect data drift, model degradation, and performance issues. Data scientists with DevOps awareness understand the importance of implementing comprehensive monitoring strategies from the project's inception rather than as an afterthought.
Effective monitoring encompasses model performance metrics, data quality checks, and system health indicators. When you hire data scientists who prioritize observability, you ensure that deployed models maintain their effectiveness over time and provide early warning of potential issues.
MLOps and Model Lifecycle Management
MLOps practices extend DevOps principles specifically to machine learning workflows, encompassing model versioning, automated retraining, and performance tracking. These practices ensure that machine learning systems remain valuable business assets rather than technical debt.
Salary Expectations and Market Trends for DevOps-Ready Data Scientists
The market premium for data scientists with DevOps skills reflects their increased value to organizations. According to recent industry surveys, professionals who combine analytical expertise with operational capabilities command salaries 15-25% higher than traditional data scientists.
This premium reflects the scarcity of professionals who bridge both domains effectively. When you hire data scientists with DevOps capabilities, the investment pays dividends through reduced time-to-production and increased project success rates.
Geographic and Industry Variations
Technology hubs like San Francisco, Seattle, and New York show the highest demand for DevOps-enabled data scientists, with average salaries ranging from $145,000 to $200,000 annually. Financial services and technology companies typically offer the most competitive compensation packages for these hybrid skill sets.
Building Internal DevOps Capabilities in Data Science Teams
Organizations can develop DevOps capabilities within existing data science teams through targeted training and cultural initiatives. This approach often proves more cost-effective than exclusively seeking external candidates with fully developed skill sets.
Successful capability building requires executive support, dedicated training resources, and opportunities for practical application. Teams that invest in developing these competencies internally often achieve better cultural integration and knowledge retention.
Training and Development Programs
Structured learning paths that combine technical training with hands-on projects help data scientists develop operational awareness. Partnerships with engineering teams provide valuable mentorship and real-world experience in production environments.
Conclusion: The Future of Data Science Talent
The data science profession continues evolving toward greater integration with engineering and operations practices. Organizations that hire data scientists with DevOps awareness position themselves for success in an increasingly competitive landscape where speed-to-market and operational excellence determine business outcomes.
As machine learning becomes more central to business operations, the distinction between research-focused and production-ready data scientists will only become more pronounced. Companies that recognize this shift and adapt their hiring strategies accordingly will build more effective, impactful data science capabilities that drive sustainable competitive advantage in the data-driven economy.




