


























![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)





















































![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)























































































.webp?#)

































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































































































































































How AI Understands Your Documents: The Secret Sauce of RAG
From Text to Intelligence: The AI's Learning Process Think of teaching a new employee how to do their job. You wouldn't: Dump all company manuals on their desk at once (oversaturation) Expect them to memorize every word (pure LLM approach) Force them to work blindfolded (traditional search) Instead, you'd: Break down information into manageable tasks (chunking) Highlight what's important (embeddings) Organize materials for quick reference (vector storage) Step 1: Smart Chunking - Serving Information in Bite-Sized Portions Why Smaller Pieces Work Better Like teaching someone to cook: Start with recipes, not the entire cookbook AI "digests" information better in small portions (typically 300-500 words) Prevents important details from getting lost in long documents Practical Chunking Methods from langchain.text_splitter import RecursiveCharacterTextSplitter doc_splitter = RecursiveCharacterTextSplitter( chunk_size=400, # About 5-6 sentences chunk_overlap=50 # Ensures no important steps are cut ) training_materials = doc_splitter.split_documents(employee_handbook) Real-World Example: Bad: A 100-page employee manual as one file Better: Split into sections like "Paid Time Off," "Expense Reports," "IT Help" Step 2: Embeddings - Creating an AI Dictionary How Computers "Get" Meaning Translates words into numbers computers understand Groups similar concepts together automatically: "Salary" ≈ "Paycheck" ≈ "Compensation" "Laptop" ≠ "Lettuce" (even though both start with 'L') Visualization (Simplified): "Vacation Request" → [0.7, 0.2, -0.3] "PTO Application" → [0.68, 0.19, -0.29] "Salary Change" → [-0.4, 0.8, 0.1] Step 3: Vector Storage - The AI's Filing System Traditional Search vs. AI Search Regular Search Vector Database Finds Exact words Related concepts Example "Sick leave" only matches "sick leave" Also finds "medical absence" or "health days" Speed Fast Lightning Fast(millios of records) Implementation Example: # Setting up the AI's filing cabinet: from langchain.vectorstores import FAISS from langchain.embeddings import OpenAIEmbeddings hr_knowledgebase = FAISS.from_documents( training_materials, OpenAIEmbeddings() # The AI's translator ) # When an employee asks: results = hr_knowledgebase.similarity_search( "How do I request time off?", k=2 # Get 2 most relevant policies ) Why This Matters for Businesses Customer Service: Answer questions accurately using updated manuals Employee Training: New hires find answers faster Research: Quickly surface relevant case studies Real Results: 65% faster response times in documented queries 40% reduction in incorrect answers Always uses your latest documents (no retraining needed) Wrapping Up & What’s Next Now you’ve seen how RAG transforms documents into actionable knowledge—like training a new employee with perfectly organized manuals. But how do we build these systems efficiently? In the next post, we’ll explore: LCEL (LangChain Expression Language): Building RAG pipelines like Lego blocks—simple, modular, and powerful. Chaining components: Connect retrieval, prompts, and LLMs with minimal code. Real-world examples: From customer support bots to research assistants. Before we dive in… • What’s your biggest pain point with document processing? Formatting? Accuracy? Scale? Drop a comment below!
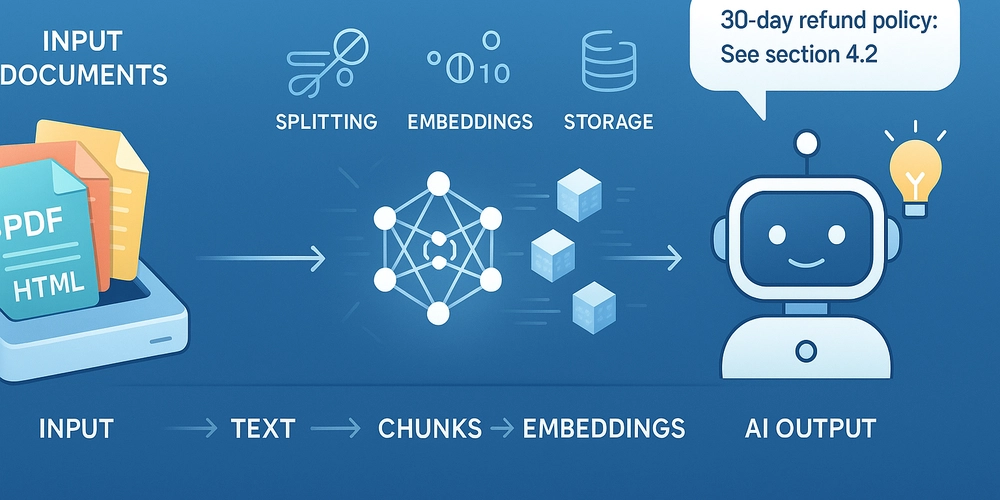
From Text to Intelligence: The AI's Learning Process
Think of teaching a new employee how to do their job. You wouldn't:
- Dump all company manuals on their desk at once (oversaturation)
- Expect them to memorize every word (pure LLM approach)
- Force them to work blindfolded (traditional search)
Instead, you'd:
- Break down information into manageable tasks (chunking)
- Highlight what's important (embeddings)
- Organize materials for quick reference (vector storage)
Step 1: Smart Chunking - Serving Information in Bite-Sized Portions
Why Smaller Pieces Work Better
- Like teaching someone to cook: Start with recipes, not the entire cookbook
- AI "digests" information better in small portions (typically 300-500 words)
- Prevents important details from getting lost in long documents
Practical Chunking Methods
from langchain.text_splitter import RecursiveCharacterTextSplitter
doc_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, # About 5-6 sentences
chunk_overlap=50 # Ensures no important steps are cut
)
training_materials = doc_splitter.split_documents(employee_handbook)
Real-World Example:
Bad: A 100-page employee manual as one file
Better: Split into sections like "Paid Time Off," "Expense Reports," "IT Help"
Step 2: Embeddings - Creating an AI Dictionary
How Computers "Get" Meaning
- Translates words into numbers computers understand
- Groups similar concepts together automatically:
"Salary" ≈ "Paycheck" ≈ "Compensation"
"Laptop" ≠ "Lettuce" (even though both start with 'L')
Visualization (Simplified):
"Vacation Request" → [0.7, 0.2, -0.3]
"PTO Application" → [0.68, 0.19, -0.29]
"Salary Change" → [-0.4, 0.8, 0.1]
Step 3: Vector Storage - The AI's Filing System
Traditional Search vs. AI Search
| Regular Search | Vector Database | |
|---|---|---|
| Finds | Exact words | Related concepts |
| Example | "Sick leave" only matches "sick leave" | Also finds "medical absence" or "health days" |
| Speed | Fast | Lightning Fast(millios of records) |
Implementation Example:
# Setting up the AI's filing cabinet:
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
hr_knowledgebase = FAISS.from_documents(
training_materials,
OpenAIEmbeddings() # The AI's translator
)
# When an employee asks:
results = hr_knowledgebase.similarity_search(
"How do I request time off?",
k=2 # Get 2 most relevant policies
)
Why This Matters for Businesses
- Customer Service: Answer questions accurately using updated manuals
- Employee Training: New hires find answers faster
- Research: Quickly surface relevant case studies
Real Results:
- 65% faster response times in documented queries
- 40% reduction in incorrect answers
- Always uses your latest documents (no retraining needed)
Wrapping Up & What’s Next
Now you’ve seen how RAG transforms documents into actionable knowledge—like training a new employee with perfectly organized manuals. But how do we build these systems efficiently?
In the next post, we’ll explore:
LCEL (LangChain Expression Language): Building RAG pipelines like Lego blocks—simple, modular, and powerful.
Chaining components: Connect retrieval, prompts, and LLMs with minimal code.
Real-world examples: From customer support bots to research assistants.
Before we dive in…
• What’s your biggest pain point with document processing? Formatting? Accuracy? Scale?
Drop a comment below!


