


































































![Apple Weighs Acquisition of AI Startup Perplexity in Internal Talks [Report]](https://www.iclarified.com/images/news/97674/97674/97674-640.jpg)

![Oakley and Meta Launch Smart Glasses for Athletes With AI, 3K Camera, More [Video]](https://www.iclarified.com/images/news/97665/97665/97665-640.jpg)


















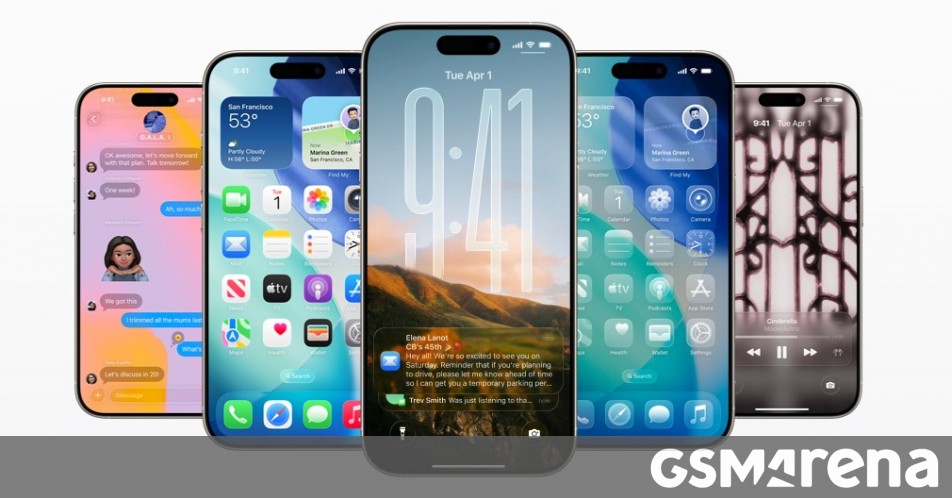
![Apple tells students ‘how to convince your parents to get you a Mac’ [Update: Removed]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/06/screenshot-2025-06-20-at-09.14.21.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)































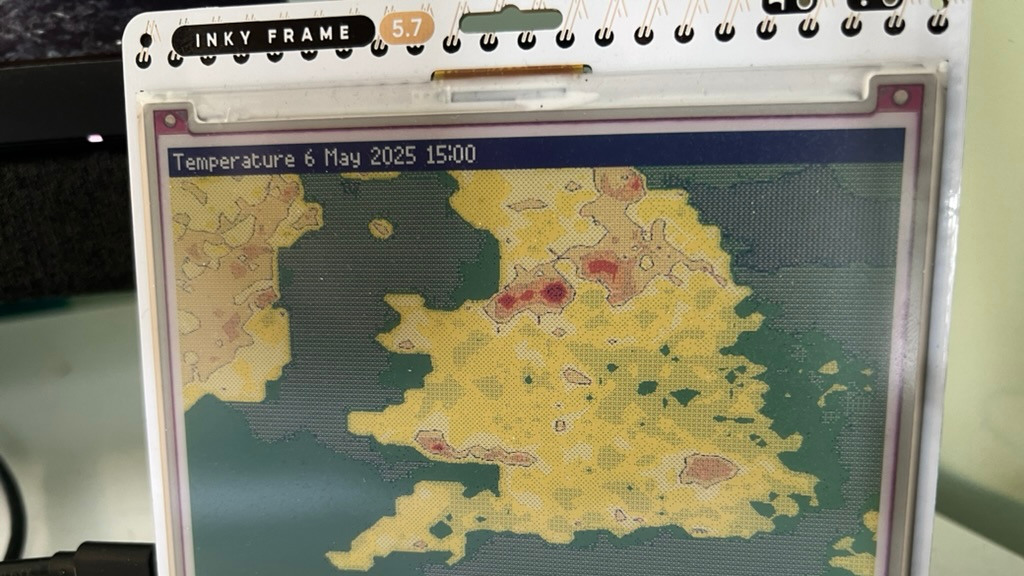
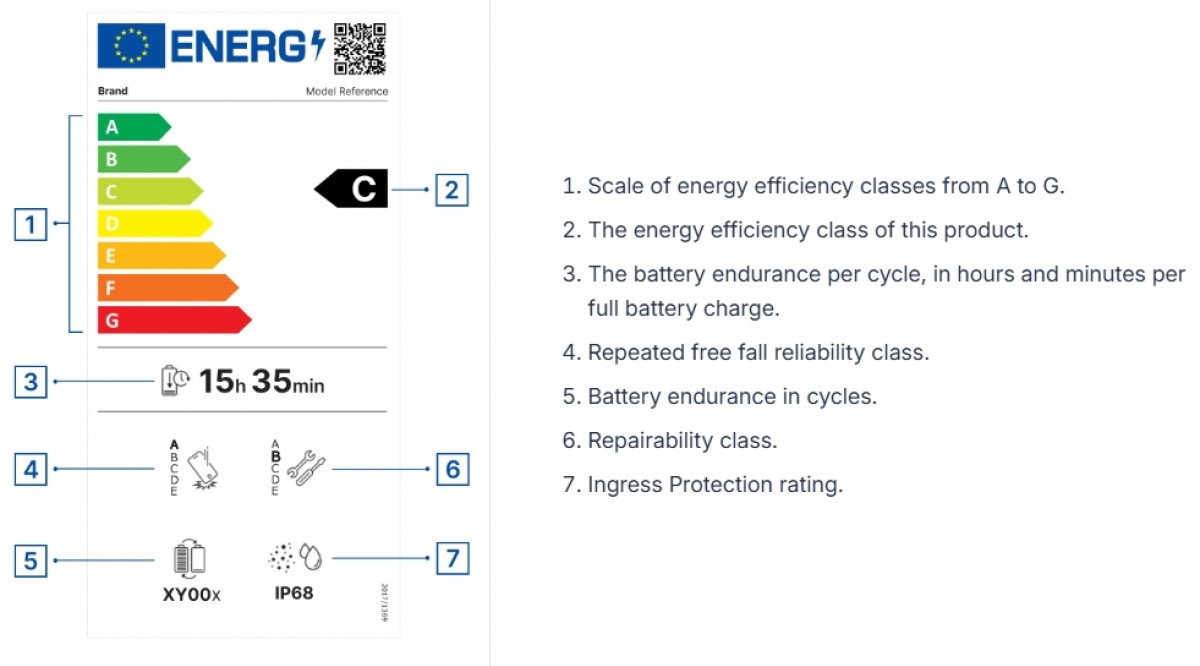
























































_Paul_Markillie_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


















































































































![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)
















































































































































































































































Kafka Fundamentals: kafka high availability
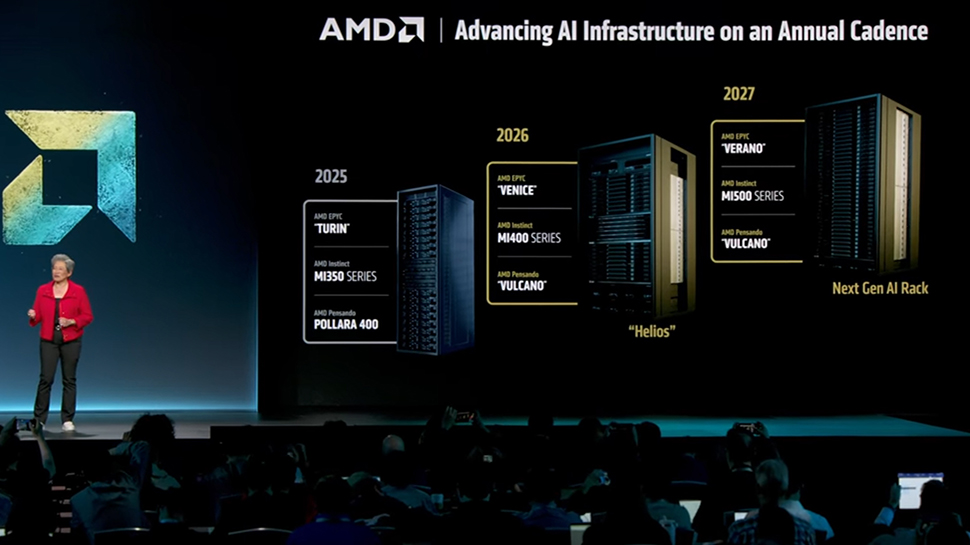
Kafka High Availability: A Deep Dive for Production Systems 1. Introduction Imagine a financial trading platform where every millisecond of downtime translates to significant revenue loss. Or a global logistics network relying on real-time tracking updates. In these scenarios, Kafka isn’t just a message queue; it’s the central nervous system. A critical challenge is ensuring that Kafka remains highly available – not just at the broker level, but end-to-end, guaranteeing message delivery and processing even during failures. This isn’t about simple replication; it’s about architecting for resilience in a complex, distributed environment of microservices, stream processing applications (like Kafka Streams or Flink), and potentially distributed transactions. Observability is paramount, as is strict adherence to data contracts enforced by a Schema Registry. The goal is to build a platform that can absorb failures gracefully without impacting critical business operations. 2. What is "kafka high availability" in Kafka Systems? Kafka high availability isn’t a single feature, but a combination of architectural choices and configurations designed to minimize downtime and data loss. It’s fundamentally about ensuring continuous operation despite broker failures, network partitions, or other disruptions. Prior to Kafka 2.8, ZooKeeper was the cornerstone of this, managing broker metadata and leader election. Now, with the introduction of KRaft (KIP-500), Kafka can operate without ZooKeeper, using a self-managed metadata quorum. High availability manifests across several layers: Brokers: Replication factor determines how many copies of each partition exist. A replication factor of 3 means each partition has a leader and two followers. Controllers: The controller manages partition leadership and broker membership. With KRaft, the controller role is distributed across the metadata quorum. Producers: Idempotent producers (introduced in Kafka 0.11.0) and transactional producers (Kafka 0.11.0+) guarantee exactly-once semantics, preventing data duplication or loss during failures. Consumers: Consumer groups enable parallel consumption. Rebalances, triggered by failures or new consumers, must be handled efficiently to minimize downtime. Control Plane: KRaft replaces ZooKeeper as the metadata store, improving scalability and reducing operational complexity. Key configuration flags include replication.factor, min.insync.replicas, transactional.id, enable.idempotence, and KRaft-specific settings like node.id and controller.quorum.voters. 3. Real-World Use Cases Financial Transaction Processing: Guaranteed delivery of every transaction is non-negotiable. Idempotent producers and transactional guarantees are essential. High availability ensures no transactions are lost during peak load or broker failures. Clickstream Analytics: Capturing every user interaction requires a resilient pipeline. Consumer lag must be minimized, and backpressure mechanisms implemented to handle surges in traffic. Change Data Capture (CDC): Replicating database changes to downstream systems demands high availability to avoid data inconsistencies. MirrorMaker 2.0 (or equivalent solutions) can replicate topics across datacenters for disaster recovery. Log Aggregation: Collecting logs from thousands of servers requires a highly scalable and fault-tolerant system. Partitioning and replication are crucial for handling the volume and ensuring no logs are lost. Real-time Fraud Detection: Low latency and high throughput are critical. High availability ensures the fraud detection system remains operational even during infrastructure outages. 4. Architecture & Internal Mechanics Kafka’s high availability relies on a distributed architecture. Each topic is divided into partitions, and each partition is replicated across multiple brokers. The leader broker for a partition handles all read and write requests. Follower brokers replicate the data from the leader. graph LR A[Producer] --> B(Kafka Broker 1 - Leader); B --> C{Partition 1}; C --> D(Kafka Broker 2 - Follower); C --> E(Kafka Broker 3 - Follower); B --> F{Partition 2}; F --> G(Kafka Broker 4 - Follower); F --> H(Kafka Broker 5 - Follower); I[Consumer Group 1] --> C; J[Consumer Group 2] --> F; K[Schema Registry] --> A; subgraph Kafka Cluster B D E F G H end The controller (or KRaft metadata quorum) monitors broker health and automatically elects new leaders if a broker fails. The in-sync replicas (ISRs) are the replicas that are currently caught up with the leader. The min.insync.replicas configuration determines the minimum number of ISRs that must acknowledge a write before it is considered successful. This prevents data loss in the event of a broker failure. Log segments are the fundamental unit of storage, and r

Kafka High Availability: A Deep Dive for Production Systems
1. Introduction
Imagine a financial trading platform where every millisecond of downtime translates to significant revenue loss. Or a global logistics network relying on real-time tracking updates. In these scenarios, Kafka isn’t just a message queue; it’s the central nervous system. A critical challenge is ensuring that Kafka remains highly available – not just at the broker level, but end-to-end, guaranteeing message delivery and processing even during failures. This isn’t about simple replication; it’s about architecting for resilience in a complex, distributed environment of microservices, stream processing applications (like Kafka Streams or Flink), and potentially distributed transactions. Observability is paramount, as is strict adherence to data contracts enforced by a Schema Registry. The goal is to build a platform that can absorb failures gracefully without impacting critical business operations.
2. What is "kafka high availability" in Kafka Systems?
Kafka high availability isn’t a single feature, but a combination of architectural choices and configurations designed to minimize downtime and data loss. It’s fundamentally about ensuring continuous operation despite broker failures, network partitions, or other disruptions. Prior to Kafka 2.8, ZooKeeper was the cornerstone of this, managing broker metadata and leader election. Now, with the introduction of KRaft (KIP-500), Kafka can operate without ZooKeeper, using a self-managed metadata quorum.
High availability manifests across several layers:
- Brokers: Replication factor determines how many copies of each partition exist. A replication factor of 3 means each partition has a leader and two followers.
- Controllers: The controller manages partition leadership and broker membership. With KRaft, the controller role is distributed across the metadata quorum.
- Producers: Idempotent producers (introduced in Kafka 0.11.0) and transactional producers (Kafka 0.11.0+) guarantee exactly-once semantics, preventing data duplication or loss during failures.
- Consumers: Consumer groups enable parallel consumption. Rebalances, triggered by failures or new consumers, must be handled efficiently to minimize downtime.
- Control Plane: KRaft replaces ZooKeeper as the metadata store, improving scalability and reducing operational complexity.
Key configuration flags include replication.factor, min.insync.replicas, transactional.id, enable.idempotence, and KRaft-specific settings like node.id and controller.quorum.voters.
3. Real-World Use Cases
- Financial Transaction Processing: Guaranteed delivery of every transaction is non-negotiable. Idempotent producers and transactional guarantees are essential. High availability ensures no transactions are lost during peak load or broker failures.
- Clickstream Analytics: Capturing every user interaction requires a resilient pipeline. Consumer lag must be minimized, and backpressure mechanisms implemented to handle surges in traffic.
- Change Data Capture (CDC): Replicating database changes to downstream systems demands high availability to avoid data inconsistencies. MirrorMaker 2.0 (or equivalent solutions) can replicate topics across datacenters for disaster recovery.
- Log Aggregation: Collecting logs from thousands of servers requires a highly scalable and fault-tolerant system. Partitioning and replication are crucial for handling the volume and ensuring no logs are lost.
- Real-time Fraud Detection: Low latency and high throughput are critical. High availability ensures the fraud detection system remains operational even during infrastructure outages.
4. Architecture & Internal Mechanics
Kafka’s high availability relies on a distributed architecture. Each topic is divided into partitions, and each partition is replicated across multiple brokers. The leader broker for a partition handles all read and write requests. Follower brokers replicate the data from the leader.
graph LR
A[Producer] --> B(Kafka Broker 1 - Leader);
B --> C{Partition 1};
C --> D(Kafka Broker 2 - Follower);
C --> E(Kafka Broker 3 - Follower);
B --> F{Partition 2};
F --> G(Kafka Broker 4 - Follower);
F --> H(Kafka Broker 5 - Follower);
I[Consumer Group 1] --> C;
J[Consumer Group 2] --> F;
K[Schema Registry] --> A;
subgraph Kafka Cluster
B
D
E
F
G
H
end
The controller (or KRaft metadata quorum) monitors broker health and automatically elects new leaders if a broker fails. The in-sync replicas (ISRs) are the replicas that are currently caught up with the leader. The min.insync.replicas configuration determines the minimum number of ISRs that must acknowledge a write before it is considered successful. This prevents data loss in the event of a broker failure. Log segments are the fundamental unit of storage, and retention policies determine how long data is stored.
5. Configuration & Deployment Details
server.properties (Broker Configuration):
broker.id=1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://kafka-broker-1:9092
num.network.threads=4
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
log.dirs=/kafka/data
replication.factor=3
min.insync.replicas=2
default.replication.factor=3
transaction.state.log.replication.factor=3
controller.quorum.voters=1@kafka-broker-1:9092,2@kafka-broker-2:9092,3@kafka-broker-3:9092 # KRaft
process.roles=broker,controller # KRaft
consumer.properties (Consumer Configuration):
group.id=my-consumer-group
bootstrap.servers=kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer
enable.auto.commit=false
auto.offset.reset=earliest
max.poll.records=500
CLI Examples:
- Create a topic with replication factor 3:
kafka-topics.sh --create --topic my-topic --bootstrap-server kafka-broker-1:9092 --replication-factor 3 --partitions 10
- Describe topic configuration:
kafka-topics.sh --describe --topic my-topic --bootstrap-server kafka-broker-1:9092
- Check consumer group offsets:
kafka-consumer-groups.sh --bootstrap-server kafka-broker-1:9092 --group my-consumer-group --describe
6. Failure Modes & Recovery
- Broker Failure: The controller (or KRaft quorum) detects the failure and elects a new leader for the affected partitions. Consumers continue to read from the new leader.
- Rebalance: When a consumer joins or leaves a group, a rebalance occurs. This can cause temporary downtime. Minimizing the number of partitions and using a stable consumer group ID can reduce rebalance frequency.
-
Message Loss: Enabled idempotent producers and transactional guarantees prevent message loss. If
min.insync.replicasis set correctly, data loss is minimized even if some replicas are unavailable. -
ISR Shrinkage: If the number of ISRs falls below
min.insync.replicas, writes are blocked until enough replicas become available.
Recovery strategies include:
- Idempotent Producers: Ensure exactly-once semantics.
- Transactional Producers: Provide atomic writes across multiple partitions.
- Offset Tracking: Consumers track their progress to avoid reprocessing messages.
- Dead Letter Queues (DLQs): Route failed messages to a separate topic for investigation.
7. Performance Tuning
- Throughput: Achieving high throughput requires careful tuning of producer and consumer configurations. Benchmark results vary based on hardware and workload, but a well-tuned Kafka cluster can easily handle hundreds of MB/s or millions of events/s.
-
linger.ms: Increase this value to batch more messages, improving throughput at the cost of increased latency. -
batch.size: Larger batch sizes improve throughput but increase memory usage. -
compression.type: Use compression (e.g.,gzip,snappy,lz4) to reduce network bandwidth and storage costs. -
fetch.min.bytes: Increase this value to reduce the number of fetch requests, improving throughput. -
replica.fetch.max.bytes: Control the maximum amount of data fetched from a follower replica.
High availability can slightly impact latency due to the overhead of replication and leader election. Tail log pressure can be mitigated by increasing the number of partitions and optimizing disk I/O.
8. Observability & Monitoring
- Prometheus: Expose Kafka JMX metrics to Prometheus for monitoring.
-
Kafka JMX Metrics: Monitor key metrics like
UnderReplicatedPartitions,OfflinePartitionsCount,ConsumerLag,RequestLatency, andQueueLength. - Grafana Dashboards: Create Grafana dashboards to visualize Kafka performance and health.
Alerting conditions:
-
UnderReplicatedPartitions > 0: Indicates a potential data loss risk. -
ConsumerLag > threshold: Indicates consumers are falling behind. -
RequestLatency > threshold: Indicates performance issues. -
QueueLength > threshold: Indicates broker overload.
9. Security and Access Control
- SASL/SSL: Use SASL/SSL to encrypt communication between clients and brokers.
- SCRAM: Use SCRAM for authentication.
- ACLs: Configure Access Control Lists (ACLs) to restrict access to topics and resources.
- Kerberos: Integrate with Kerberos for strong authentication.
- Audit Logging: Enable audit logging to track access and modifications to the Kafka cluster.
10. Testing & CI/CD Integration
- Testcontainers: Use Testcontainers to spin up temporary Kafka clusters for integration testing.
- Embedded Kafka: Use embedded Kafka for unit testing.
- Consumer Mock Frameworks: Mock consumer behavior to test producer logic.
- Schema Compatibility Tests: Ensure schema evolution is backward compatible.
- Throughput Tests: Measure Kafka throughput under various load conditions.
CI/CD pipelines should include automated tests to validate high availability configurations and ensure data integrity.
11. Common Pitfalls & Misconceptions
- Insufficient Replication Factor: A replication factor of 2 is often insufficient for production environments.
-
Incorrect
min.insync.replicas: Setting this value too low can lead to data loss. - Rebalancing Storms: Frequent rebalances can disrupt consumer performance.
- Ignoring Consumer Lag: Unmonitored consumer lag can lead to data backlogs.
- Misconfigured Idempotent Producers: Not configuring producers correctly can negate the benefits of idempotence.
Example: A consumer group stuck in a constant rebalance loop. Check the broker logs for errors related to group membership. The issue might be network instability or a misconfigured consumer.
12. Enterprise Patterns & Best Practices
- Shared vs. Dedicated Topics: Consider the trade-offs between shared and dedicated topics based on isolation and scalability requirements.
- Multi-Tenant Cluster Design: Use resource quotas and ACLs to isolate tenants.
- Retention vs. Compaction: Choose the appropriate retention policy based on data usage patterns.
- Schema Evolution: Use a Schema Registry to manage schema changes and ensure compatibility.
- Streaming Microservice Boundaries: Design microservices to consume and produce events from well-defined Kafka topics.
13. Conclusion
Kafka high availability is a complex topic that requires careful planning and execution. By understanding the underlying architecture, configuring the system correctly, and implementing robust monitoring and alerting, you can build a resilient and scalable Kafka-based platform. Next steps include implementing comprehensive observability, building internal tooling for managing the cluster, and continuously refactoring topic structure to optimize performance and scalability. A proactive approach to high availability is essential for any organization relying on Kafka for mission-critical applications.


