
_sleepyfellow_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























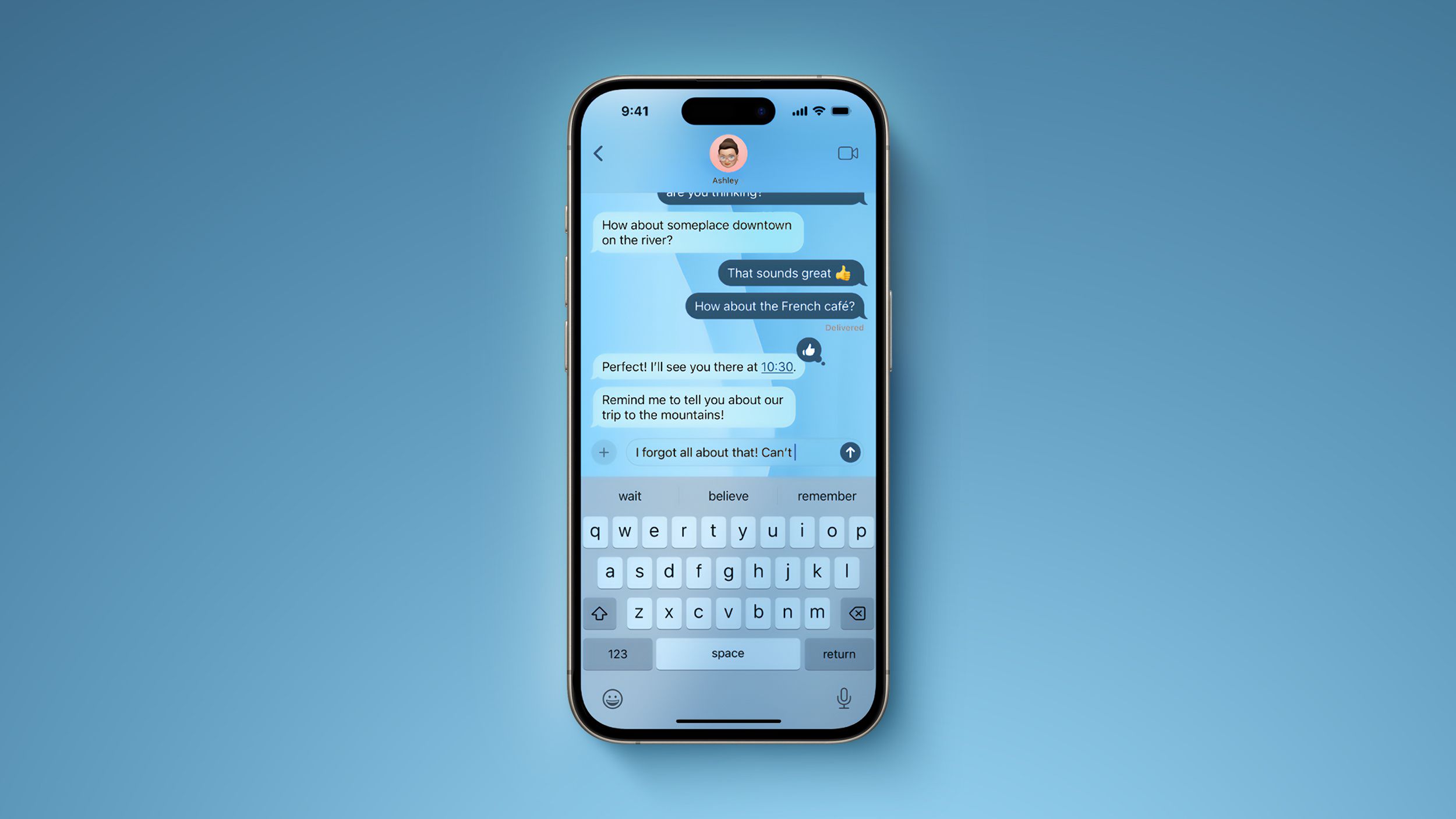






































![watchOS 26 May Bring Third-Party Widgets to Control Center [Report]](https://www.iclarified.com/images/news/97520/97520/97520-640.jpg)

![AirPods Pro 2 On Sale for $169 — Save $80! [Deal]](https://www.iclarified.com/images/news/97526/97526/97526-640.jpg)










































































































_Michael_Vi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


















































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)

























































































































































![From electrical engineering student to CTO with Hitesh Choudhary [Podcast #175]](https://cdn.hashnode.com/res/hashnode/image/upload/v1749158756824/3996a2ad-53e5-4a8f-ab97-2c77a6f66ba3.png?#)
























































































Ny studie avslöjar att vissa LLM kan ge vilseledande förklaringar
Forskare från Microsoft och MIT har utvecklat en metod för att avgöra när AI-system ljuger eller ger vilseledande förklaringar. Den nya tekniken, som kallas ”causal concept faithfulness” kan avslöja när stora språkmodeller (LLM) ger plausibla men opålitliga förklaringar för sina beslut. Problemet med AI:s förklaringar AI-system som ChatGPT och GPT-4 kan ge svar som låter […] The post Ny studie avslöjar att vissa LLM kan ge vilseledande förklaringar first appeared on AI nyheter.

Forskare från Microsoft och MIT har utvecklat en metod för att avgöra när AI-system ljuger eller ger vilseledande förklaringar. Den nya tekniken, som kallas ”causal concept faithfulness” kan avslöja när stora språkmodeller (LLM) ger plausibla men opålitliga förklaringar för sina beslut. Problemet med AI:s förklaringar AI-system som ChatGPT och GPT-4 kan ge svar som låter […]
The post Ny studie avslöjar att vissa LLM kan ge vilseledande förklaringar first appeared on AI nyheter.





