
































































![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)















![Honor 400 series officially launching on May 22 as design is revealed [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/honor-400-series-announcement-1.png?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)































































































































































































































































To what extent does batch size affect the degree of overfitting in a dynamic dataset
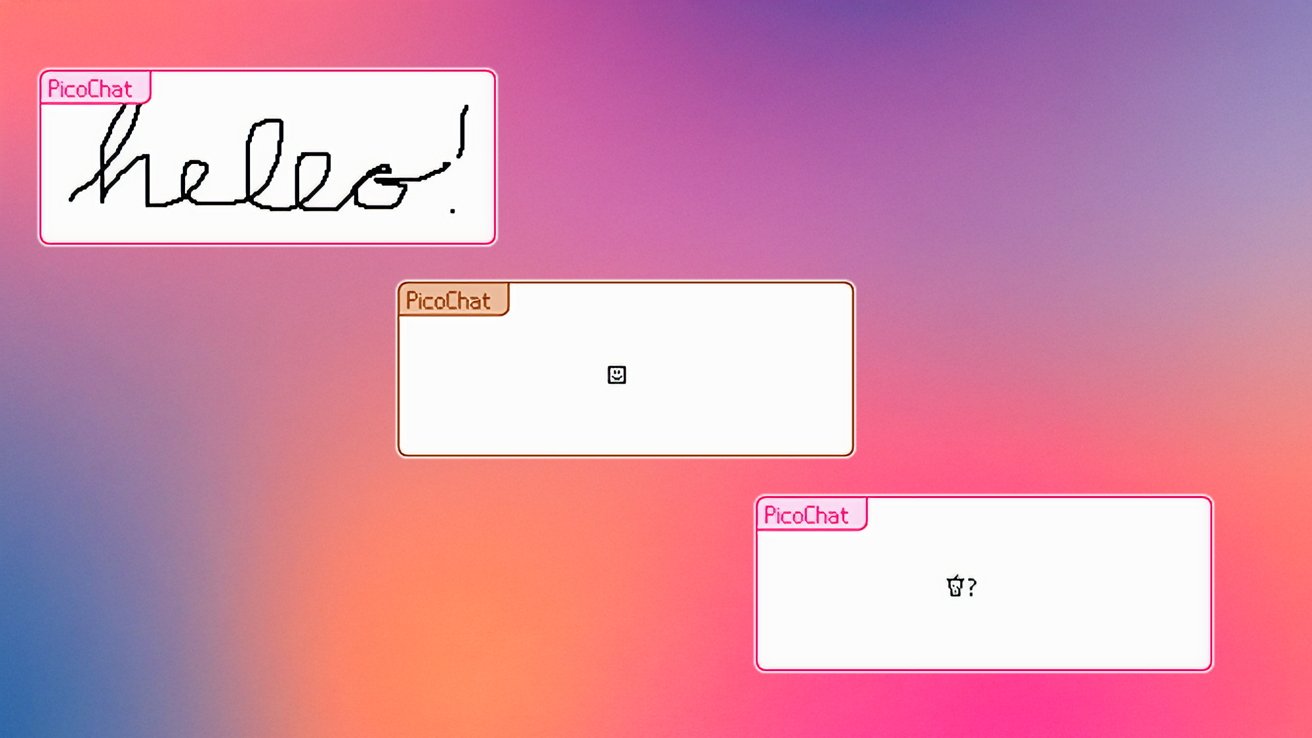
I'm currently testing out the effect that batch size has on overfitting by plotting the loss curves for the training and testing data that is being fed into a multi-layer peceptron The data is being generated through this code Ntrain = 100 Nbatch = 20 Ntest = 500 x_train = torch.rand(Ntrain, ndims)*10.0 # Inputs from 0 to 10 y_train = func(x_train, ndims) # generate noisey y training data y_train = y_train.view(-1, 1) # reshape y data x_test = torch.rand(Ntest, ndims)*10.0 # Inputs from 0 to 10 y_test = func(x_test, ndims) # generate noisey y test data y_test = y_test.view(-1, 1) # reshape y data instead of using a fixed dataset with the optimiser being adam with the mse loss function being used. From doing some very light research, it appears that using larger batches increases the risk of overfitting however, the plotted loss curves for the sizes 15, 45, 60, 80, 200, and 2000 seem to indicate the opposite, in which overfitting seems to decrease the larger the dataset size becomes. I was just wondering if maybe there is an issue with my model, my values, whether large batch sizes only increase the risk of overfitting based on their proportions to a fixed dataset, or whether there are other factors that affect this.
I'm currently testing out the effect that batch size has on overfitting by plotting the loss curves for the training and testing data that is being fed into a multi-layer peceptron
The data is being generated through this code
Ntrain = 100
Nbatch = 20
Ntest = 500
x_train = torch.rand(Ntrain, ndims)*10.0 # Inputs from 0 to 10
y_train = func(x_train, ndims) # generate noisey y training data
y_train = y_train.view(-1, 1) # reshape y data
x_test = torch.rand(Ntest, ndims)*10.0 # Inputs from 0 to 10
y_test = func(x_test, ndims) # generate noisey y test data
y_test = y_test.view(-1, 1) # reshape y data
instead of using a fixed dataset with the optimiser being adam with the mse loss function being used.
From doing some very light research, it appears that using larger batches increases the risk of overfitting however, the plotted loss curves for the sizes 15, 45, 60, 80, 200, and 2000 seem to indicate the opposite, in which overfitting seems to decrease the larger the dataset size becomes.
I was just wondering if maybe there is an issue with my model, my values, whether large batch sizes only increase the risk of overfitting based on their proportions to a fixed dataset, or whether there are other factors that affect this.
![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
