






























































![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)












![[Fixed] Chromecast (2nd gen) and Audio can’t Cast in ‘Untrusted’ outage](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/08/chromecast_audio_1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



















































































































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)





















































































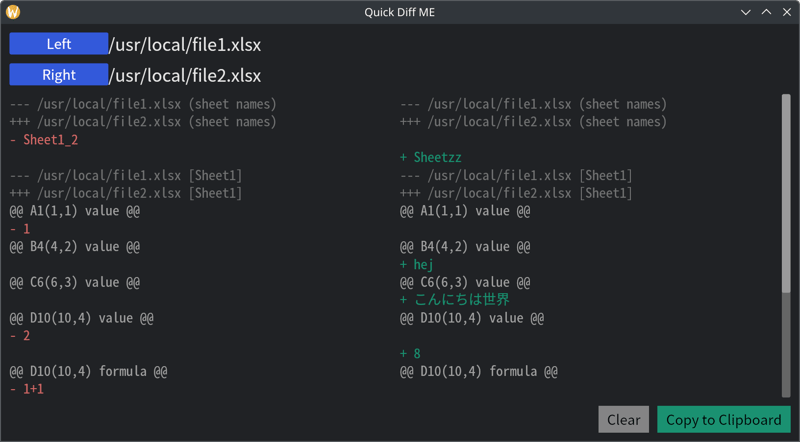

























































-《公式》スマートフォン向けアプリ『デジモンアリシオン』プロジェクト始動PV《Official》New-Digimon-Card-Game-app-DIGIMON-ALYSION-00-00-28.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


























































VisualWebInstruct: A Large-Scale Multimodal Reasoning Dataset for Enhancing Vision-Language Models
VLMs have shown notable progress in perception-driven tasks such as visual question answering (VQA) and document-based visual reasoning. However, their effectiveness in reasoning-intensive tasks remains limited due to the scarcity of high-quality, diverse training datasets. Existing multimodal reasoning datasets have several shortcomings: some focus too narrowly on specific scientific imagery, others rely on synthetic data […] The post VisualWebInstruct: A Large-Scale Multimodal Reasoning Dataset for Enhancing Vision-Language Models appeared first on MarkTechPost.



VLMs have shown notable progress in perception-driven tasks such as visual question answering (VQA) and document-based visual reasoning. However, their effectiveness in reasoning-intensive tasks remains limited due to the scarcity of high-quality, diverse training datasets. Existing multimodal reasoning datasets have several shortcomings: some focus too narrowly on specific scientific imagery, others rely on synthetic data lacking real-world generalization, and many are too small or simplistic to develop robust reasoning capabilities. Due to these constraints, VLMs struggle with multi-step reasoning tasks such as those evaluated in MMMU, MathVista, and MEGABench benchmarks. Given the challenges of manual annotation at scale, researchers have explored automated data mining approaches. Inspired by WebInstruct, a method for retrieving reasoning-focused text from the internet, efforts have been made to extend this approach to multimodal reasoning. However, the absence of large-scale multimodal datasets and the limitations of current retrieval models hinder its feasibility.
Researchers have explored various strategies to advance multimodal reasoning, including neural symbolic reasoning, optimized visual encoding, plan-based prompting, and structured reasoning frameworks. While proprietary models like GPT-4o and Gemini demonstrate state-of-the-art performance, their restricted access has led to the development of open-source alternatives such as LLaVA, MiniGPT-4, and Deepseek-VL. Many of these models utilize lightweight connector-based architectures to integrate visual and textual representations. A key technique that has significantly improved reasoning in LLMs is CoT prompting, which breaks down complex queries into sequential reasoning steps, enhancing logical inference. Models such as Prism and MSG have built upon this structured reasoning approach, refining perception-reasoning pipelines and optimizing prompt-based methodologies. Despite these advances, the limited availability of large-scale supervised datasets for multimodal reasoning remains a major bottleneck, impeding further improvements in VLM capabilities.
Researchers from the University of Waterloo, the University of Toronto, UC Santa Barbara, Carnegie Mellon University (CMU), the National University of Singapore (NUS), and Netmind.ai have introduced VisualWebInstruct, a large-scale multimodal reasoning dataset to enhance VLMs. Using Google Image Search, they collected 30,000 seed images from disciplines like math, physics, and finance, retrieving 700K+ web pages to extract 900K question-answer pairs (40% visual). Fine-tuning MAmmoTH-VL2 on this dataset led to state-of-the-art performance on benchmarks like MMMU-Pro-std and Dyna-Math, demonstrating its effectiveness in improving complex reasoning tasks for VLMs.
The data mining pipeline extracts image-rich QA pairs from the internet, starting with 30K scientific images across various disciplines. Using Google Image Search, it gathers 758,490 unique URLs, filtering out non-educational sources. Accessibility trees are constructed to extract relevant text and images. The Gemini 1.5 Flash model identifies and filters QA pairs based on quality criteria. Further refinement with GPT-4o ensures answer consistency, generating multiple responses and validating them against original web sources. The final dataset, VISUALWEBINSTRUCT, contains 1.04 million QA pairs, with 38% including images covering subjects like mathematics (62.5%), physics (14.5%), and finance (7.25%).
The study fine-tuned MAmmoTH-VL using the VISUALWEBINSTRUCT dataset, resulting in MAmmoTH-VL2. The architecture includes a Qwen2.5-7B-Instruct language model, a SigLip vision encoder, and a projector module. The training was performed with supervised fine-tuning, a batch size 256, and distinct learning rates for different components. The model was evaluated on seven multimodal reasoning benchmarks, where it outperformed similar open-source models, particularly in mathematical reasoning. An ablation study demonstrated that integrating VISUALWEBINSTRUCT with Llava-CoT produced the best results, highlighting the dataset’s effectiveness in improving multimodal reasoning performance across diverse tasks.

In conclusion, the study explores building large-scale multimodal reasoning datasets without human annotation. It is the first to use Google Image Search to mine high-quality visual reasoning data, achieving state-of-the-art results on five benchmarks. The proposed method, VisualWebInstruct, leverages search engines to create a diverse dataset across multiple disciplines. Processing over 700K URLs generates around 900K question-answer pairs. Models fine-tuned on this dataset show notable performance improvements, with MAmmoTH-VL2 achieving leading results among 10B-parameter models. These findings demonstrate the dataset’s effectiveness in enhancing vision-language models for complex reasoning tasks.
Check out the Paper, Project Page and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post VisualWebInstruct: A Large-Scale Multimodal Reasoning Dataset for Enhancing Vision-Language Models appeared first on MarkTechPost.







