

























































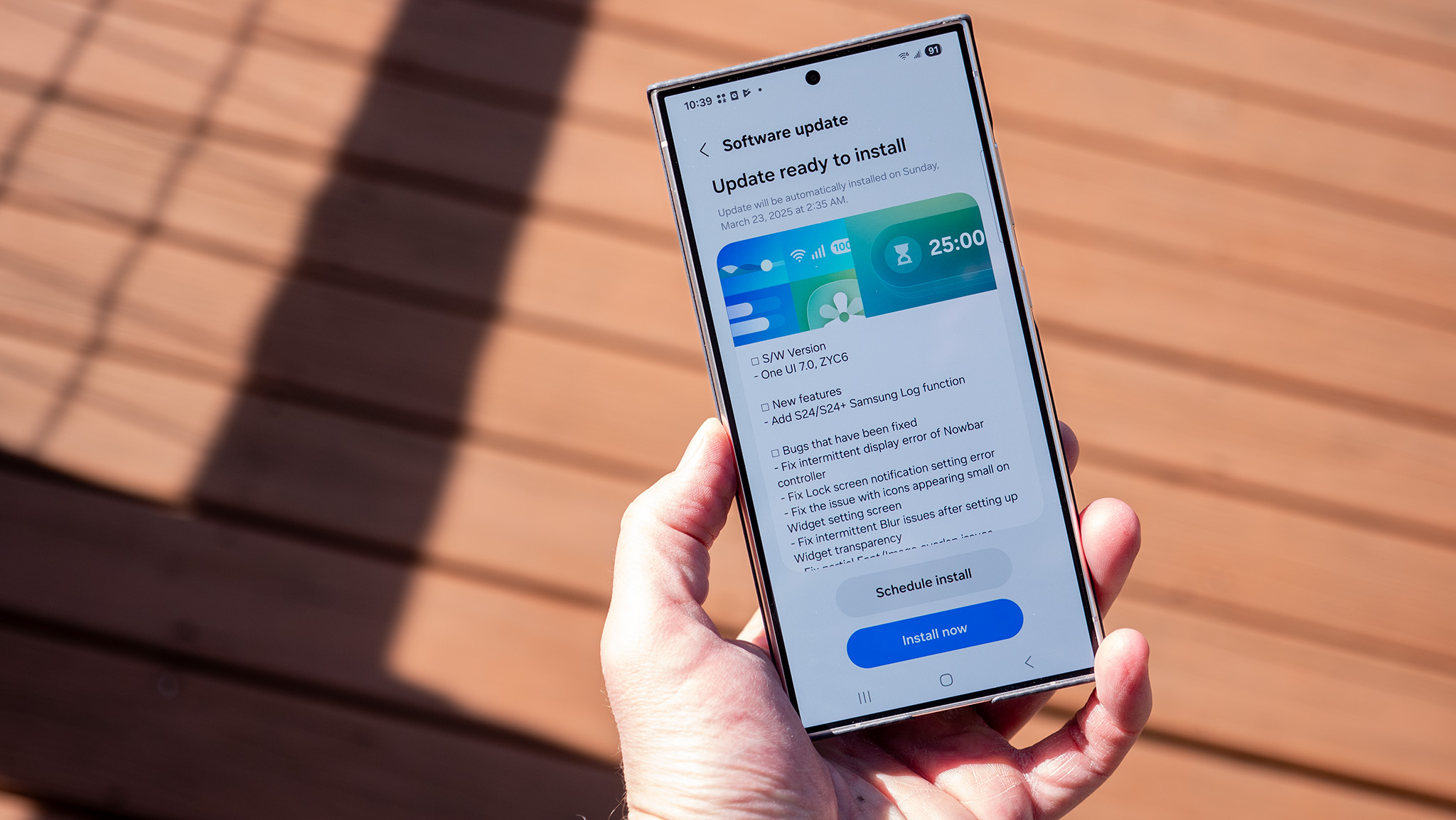
![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)
![Alleged Case for Rumored iPhone 17 Air Surfaces Online [Image]](https://www.iclarified.com/images/news/96763/96763/96763-640.jpg)

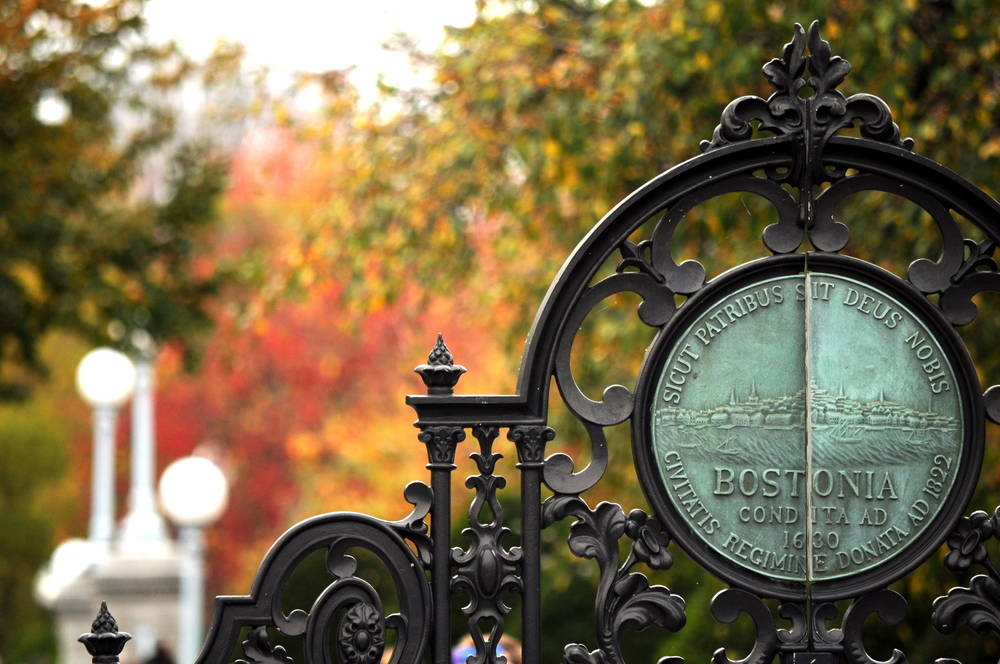































































































_Kjetil_Kolbjørnsrud_Alamy.jpg?#)































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)










































































































































-I-Interviewed-Niantic-about-Selling-Pokémon-GO-to-Scopely-00-14-13.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)























































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)




AI Code Completion: Less Is More
If you’ve been following our journey, you might’ve read our recent blog post on the Complete the Un-Completable: The State of AI Completion in JetBrains IDEs. From that post, you might remember this cool chart on code completions. In April, something exciting happened: our acceptance rate went up while the explicit cancel rate dropped. In […]

If you’ve been following our journey, you might’ve read our recent blog post on the Complete the Un-Completable: The State of AI Completion in JetBrains IDEs. From that post, you might remember this cool chart on code completions. In April, something exciting happened: our acceptance rate went up while the explicit cancel rate dropped.

In this blog post, we’ll break down why and how we got the results without retraining our generation model.
Man shall not live on LLM alone
The LLM that provides your code suggestions is the heart of AI-powered code completion, but it’s not the whole show. There’s a ton happening behind the scenes, in particular on the plugin side, like deciding:
- When to show a suggestion.
- If a suggestion should be single-line or multi-line.
- Which suggestions to show or conceal – for instance, a suggestion could be semantically incorrect, score too low, or use offensive or inappropriate language.
But sometimes, defining the filtering rules is not that straightforward.
What we are trying to achieve
Simply put, we want to show you only the suggestions you’ll actually use. That means fewer unwanted suggestions – ones you’ll cancel, edit, or delete – without losing the power of our code completion feature. In terms of metrics, we’re working to:
- Increase the acceptance rate.
- Cut down the explicit cancel rate and the percentage of edited/deleted suggestions.
- Maintain or increase the ratio of completed code.
All you need is logs
So, how do we achieve all of this? The obvious answer is to improve the completion model.
However, it’s not that simple:
- It’s expensive and time-consuming. Training a better model takes a lot of resources.
- We can’t see where things go wrong. We don’t store users’ code, so we can’t analyze bad suggestions.
- Context alone isn’t enough – things like user behavior and how a suggestion fits with nearby lines also matter.
Lightweight local filter model
Instead of going down that long road of improving the completion LLM, we took a different approach: a lightweight local filter model.
This model runs on top of the completion LLM and is trained using anonymized logs.
The model helps decide whether a suggestion should be shown by analyzing:
- Context: The file/project context (like the language used as well as the number and type of imports) and the completion context (like features that describe a caret location).
- User behavior: The typing speed and the time spent since last typing.
- The suggestion itself: Whether references are resolved, if the suggestion repeats itself or is similar to surrounding lines, and additional model outputs like token scores and token entropy.

The job of the lightweight local filter model is simple: it decides whether to accept or reject a suggestion based on your actions. However, we’ve guided the model a bit during training. We gave extra weight to explicit user actions, like when you explicitly accept or cancel a suggestion. If you edit or delete a suggestion after accepting it, we treat it as less of a win – the more you change, the less weight it gets.
Technically speaking, the model is built with CatBoost, which is efficient and doesn’t need tons of data. The model is specifically designed to be lightweight – once trained, it becomes a compact 2.5 MB file and runs directly in Kotlin on users’ machines, making predictions in 1–2 milliseconds.
What we have achieved
Our A/B tests in the EAP showed great results, and they’re getting even better. The filter model boosted the acceptance rate by ~50% and cut the explicit cancel rate by ~40%, all while keeping the ratio of completed code steady.
We officially rolled out the filter model in version 2024.1 of JetBrains IDEs for a range of languages, including Java, Kotlin, Python, PHP, JavaScript/TypeScript, Go, CSS, and Ruby. In later versions we also covered C#, C++, Rust, and HCL, plus the local filter model for cloud completion with Mellum in Python, Java, and Kotlin. We plan to cover even more languages soon.
Meanwhile, both the local code completion model and the lightweight local filter model continue to evolve and improve together.

What we have learned
Even if your LLM is already doing a great job, there’s always room for improvement. You don’t always need massive, complex models to make a difference. Sometimes, the smart use of extra data like logs can do the trick. So, what’s next for AI-powered code completion? How far can we push it?
Share your thoughts and ideas in the comments below!







