





































![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)
![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)




































































































.webp?#)





















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)





































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































Beyond Basic RAG: Measuring Embedding and Generation Performance with RAGAS
Introduction In the previous post, we looked at a basic Retrieval Augmented Generation (RAG) example using .Net for both retrieval and generation. This is built using out of the box components offered by Semantic Kernel and used an out of the box chunking approach. The barriers of entry to achieve this is low which helps to democratise access to Large Language Models (LLMs) in wider ecosystems and drive innovation. For instance; in .Net, it is possible to use Microsoft Semantic Kernel or Aspire.Azure.AI.OpenAI (OpenAI, Azure OpenAI as well as compatible local options such as Ollama). There is even an emerging open source .NET port of Langchain with JetBrains being an official supporter. For those who would like to run inference in process (CPU or GPU) without HTTP APIs, there is also LLamaSharp which is a .Net wrapper around llama.cpp supporting CPU and GPU inference. However, given that there are many parameters / tweaks to ingestion, retrieval and generation, how can we measure the quality and outcome when building such applications? The following Google Trends chart compares search terms LLM (Blue), RAG (green), RAG Evaluation (Red) and langchain (Yellow) between January 2023 and April 2025. We observe that: Earlier in 2023, RAG was a more popular search term. Around January 2024, LLMs started to takeover in popularity. langchain remained in a steady position during the time frame. RAG Evaluation has negligible existence in the trends. Given Google is a public and general purpose search engine, the results do not mean there is no interest in evaluation but the general public may not be thinking about these aspects yet. Another look from academic papers perspective comparing "RAG" and "RAG Evaluation" yields different results. The publications has grown from 14 papers on "RAG" / 3 papers on "RAG Evaluation" during 2022 to 1041 on "RAG" / 454 on "RAG Evaluation" in 2024 (Source: ArXiv Trends, 2025). As RAG topic becomes mainstream and popular, the evaluation methods also become a popular topic of research. This post will cover the following sections: RAG Evaluation System under Evaluation RAGAS Evaluation Approach Results Conclusion RAG Evaluation Evaluating Retrieval-Augmented Generation (RAG) systems is a crucial aspect of solutions that incorporate such technologies. Unlike traditional software where testing involves a deterministic process (given the input, we know the expected outcome), RAG outputs depend on two probabilistic / non deterministic components: Retrieval accuracy (finding relevant source data, rewriting user query, and similar approaches) Generation quality (producing coherent, factual responses) Variation in ingestion and generation: Chunking strategies, using metadata or not, tweaking / versioning prompts or inference parameters. Without systematic evaluation: How can we tell the difference in results from random noise? Hallucinations and irrelevant answers can go undetected. Optimisation by guesswork: Let me change this parameter and see. How do we deal with regressions? Cost / benefits. Given runtime costs include input / output tokens, if these are not included in or evaluation /. comparison, we could build a well performing system that might be too expensive to run. There are established data sets and benchmarks for Retrieval Augmented Generation systems. These benchmarks typically include datasets for tests including the query, expected answer, expected context. These are then used against the RAG system under test to evaluate the results using various metrics as defined below. Google Frames Benchmark is one example that provides dataset based on Wikipedia Articles to evaluate. metrics such as factuality, retrieval accuracy, and reasoning. These approaches introduce some challenges as following: Such datasets are generic and do not necessarily factor domain specific nuances in the target use case. It is possible that the test data might have been included in the training data set. There can be bias agains specific metrics. In this post, we will focus on how to measure both retrieval performance (e.g., Context Precision) and generation quality (e.g., faithfulness, semantic similarity) using RAGAS evaluation framework. We will be utilising RAGAS and LLM as judge approach to generate evaluation data from our documents and then run evaluation using Jupyter Notebooks running on Aspire to see the results. System under Evaluation We are ingesting Markdown documentation from official Microsoft .NET Aspire repository. Using Semantic Kernel for ingestion and a very simple chunking approach. Using Semantic Kernel for search. We register a dedicated Qdrant Vector store for each embedding model we use for evaluation. We also register an embedding model with semantic kernel for each model we will evaluate. Lastly we also register chat completion models for each LLM we are evaluating using model name as key. Thi
Introduction
In the previous post, we looked at a basic Retrieval Augmented Generation (RAG) example using .Net for both retrieval and generation. This is built using out of the box components offered by Semantic Kernel and used an out of the box chunking approach.
The barriers of entry to achieve this is low which helps to democratise access to Large Language Models (LLMs) in wider ecosystems and drive innovation. For instance; in .Net, it is possible to use Microsoft Semantic Kernel or Aspire.Azure.AI.OpenAI (OpenAI, Azure OpenAI as well as compatible local options such as Ollama). There is even an emerging open source .NET port of Langchain with JetBrains being an official supporter. For those who would like to run inference in process (CPU or GPU) without HTTP APIs, there is also LLamaSharp which is a .Net wrapper around llama.cpp supporting CPU and GPU inference.
However, given that there are many parameters / tweaks to ingestion, retrieval and generation, how can we measure the quality and outcome when building such applications?
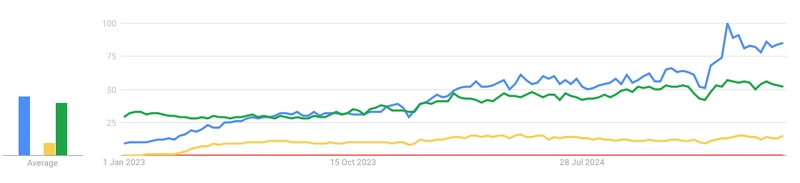
The following Google Trends chart compares search terms LLM (Blue), RAG (green), RAG Evaluation (Red) and langchain (Yellow) between January 2023 and April 2025.
We observe that:
- Earlier in 2023, RAG was a more popular search term.
- Around January 2024, LLMs started to takeover in popularity.
- langchain remained in a steady position during the time frame.
- RAG Evaluation has negligible existence in the trends.
Given Google is a public and general purpose search engine, the results do not mean there is no interest in evaluation but the general public may not be thinking about these aspects yet.
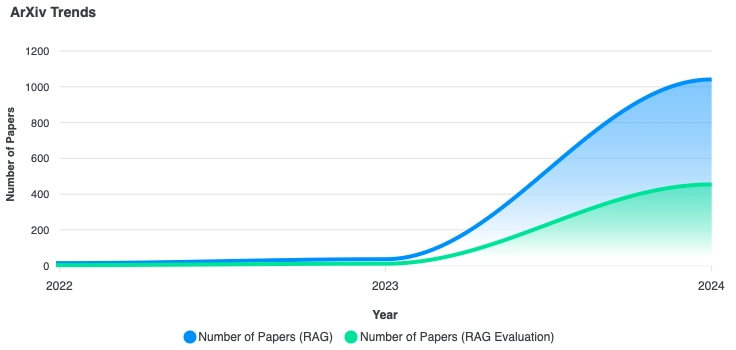
Another look from academic papers perspective comparing "RAG" and "RAG Evaluation" yields different results. The publications has grown from 14 papers on "RAG" / 3 papers on "RAG Evaluation" during 2022 to 1041 on "RAG" / 454 on "RAG Evaluation" in 2024 (Source: ArXiv Trends, 2025). As RAG topic becomes mainstream and popular, the evaluation methods also become a popular topic of research.
This post will cover the following sections:
- RAG Evaluation
- System under Evaluation
- RAGAS
- Evaluation Approach
- Results
- Conclusion
RAG Evaluation
Evaluating Retrieval-Augmented Generation (RAG) systems is a crucial aspect of solutions that incorporate such technologies.
Unlike traditional software where testing involves a deterministic process (given the input, we know the expected outcome), RAG outputs depend on two probabilistic / non deterministic components:
- Retrieval accuracy (finding relevant source data, rewriting user query, and similar approaches)
- Generation quality (producing coherent, factual responses)
- Variation in ingestion and generation: Chunking strategies, using metadata or not, tweaking / versioning prompts or inference parameters.
Without systematic evaluation:
- How can we tell the difference in results from random noise?
- Hallucinations and irrelevant answers can go undetected.
- Optimisation by guesswork: Let me change this parameter and see.
- How do we deal with regressions?
- Cost / benefits.
- Given runtime costs include input / output tokens, if these are not included in or evaluation /. comparison, we could build a well performing system that might be too expensive to run.
There are established data sets and benchmarks for Retrieval Augmented Generation systems. These benchmarks typically include datasets for tests including the query, expected answer, expected context. These are then used against the RAG system under test to evaluate the results using various metrics as defined below. Google Frames Benchmark is one example that provides dataset based on Wikipedia Articles to evaluate. metrics such as factuality, retrieval accuracy, and reasoning.
These approaches introduce some challenges as following:
- Such datasets are generic and do not necessarily factor domain specific nuances in the target use case.
- It is possible that the test data might have been included in the training data set.
- There can be bias agains specific metrics.
In this post, we will focus on how to measure both retrieval performance (e.g., Context Precision) and generation quality (e.g., faithfulness, semantic similarity) using RAGAS evaluation framework.
We will be utilising RAGAS and LLM as judge approach to generate evaluation data from our documents and then run evaluation using Jupyter Notebooks running on Aspire to see the results.
System under Evaluation
- We are ingesting Markdown documentation from official Microsoft .NET Aspire repository.
- Using Semantic Kernel for ingestion and a very simple chunking approach.
- Using Semantic Kernel for search.
- We register a dedicated Qdrant Vector store for each embedding model we use for evaluation. We also register an embedding model with semantic kernel for each model we will evaluate.
- Lastly we also register chat completion models for each LLM we are evaluating using model name as key.
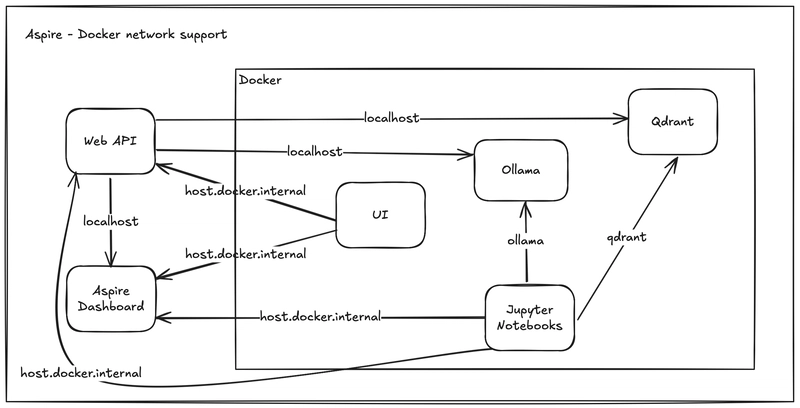
This approach allows us to use correct vector store at runtime for ingestion and retrieval depending on the request parameters used. This also ensures the request can select the LLMs for generation aspect when we are running evaluation.
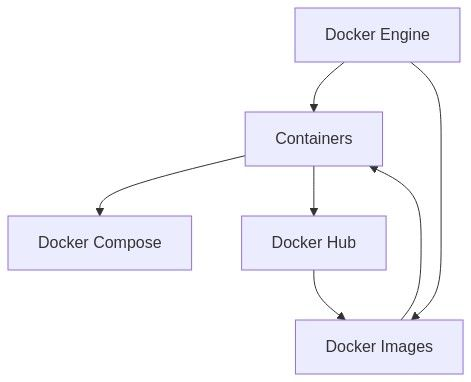
System Overview
Ingestion and Query
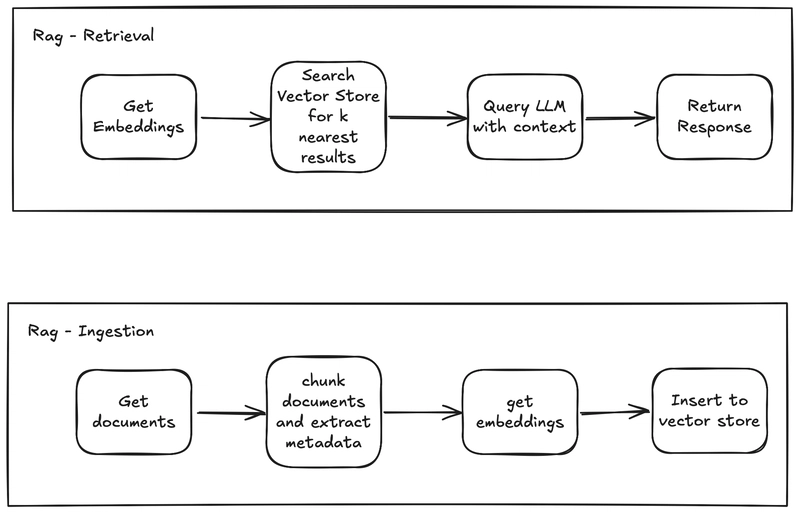
RAGAS
Ragas is one of the libraries that simplify the evaluation of Large Language Model (LLM) applications. It provides the necessary tools to generate test data as well as evaluate the results using various approaches and metrics.
RAGAS Metrics
In this section a brief overview of the metrics used in this post will be provided. For more details, please refer to RAGA Metrics documentation.
The following metrics are summarised from official RAGAS documentation metrics section.
Semantic Similarity
Measures the similarity between the answer from the LLM and the reference answer in the test dataset.
Starts with the answer embeddings and the reference embeddings. Then computes cosine similarity between the two vectors.
Answer Relevancy
Answer relevancy measures how relevant the response is to the user input. This is calculated as the following:
- Using an LLM, and the response under evaluation, generate a set of (3) artificial questions.
- Compute cosine similarity between the embedding of the user input and the embedding of the generated questions.
- Average of the scores will determine the Answer Relevancy.
Factual Correctness
Factual Correctness metric is used to evaluate the factual accuracy of the generated response against the reference. This metric uses the LLM to first break down the response and reference into claims and then uses natural language comparison to determine the factual overlap between the response and the reference. This overlap is quantified using precision, recall, and F1 score.
Precision: Measured number of positive predictions that were correct. This metric is higher when there are low false positive.
Recall: Measured how many of the actual positives were correctly identified. Recall is higher when false negatives are low.
F1: When the difference between Precision and Recall is large, F1 score can be used to balance. F1 score will be closer to the lower of two other metrics. F1 can only be high if both precision and recall are high.
Faithfulness
Faithfulness metric can be used to measure how factually consistent a response is with the retrieved context.
A faithful response is a response where all claims included in the response are consistent with the retrieved context from vector store.
This is a measure that addresses the hallucination detection. If the provided answer can be backed up by context, then it means there are no additions from the generative model.
Context Recall
Context recall measures the number of relevant documents retrieved from the vector store. If retrieval ensures that no important information is missed at this stage, then the Context Recall is considered high.
First, the reference from the evaluation dataset is broken down into claims. Then each claim in the reference answer is analysed to determine whether it can be attributed to the retrieved context or not. Ideally, all claims in the reference answer should be attributable to the retrieved context.
Evaluation Approach
Our evaluation approach involves using multiple embedding and generation models. So the process goes as following:
Configuration
For cost reasons initially the following combination is used for evaluation:
- 5 questions randomly selected.
- This is due to cost impact of OpenAPI API calls :)
- Embedding models:
-
nomic-embed-text(Ollama on local network) -
mxbai-embed-large(Ollama on local network) -
text-embedding-3-largeOpenAI
-
- For each embedding model, we evaluate using the following generative models:
phi3:3.8bphi4chatgpt-4o-latestdeepseek-r1llama3.2gemma
- We then save evaluation results a csv file.
Test Data Generation (RAGAS, GPT-4o, Jupyter Notebooks)
The selected approach is LLM As a judge and we use RAGAS to generate test dataset from our documents (.NET Aspire documentation)
We use TestsetGenerator class from RAGAS as documented in basic usage. The steps are:
- Load our documents.
- Define the personas to be used for generating queries (technical, novice, expert, ...)
- Declare the distribution for question types (simple, complex or reasoning)
- Generate test datasets.
We are using GPT-4o for generative model and text-embedding-ada-002 (default) for the embedding model. This is based on the assumption that using state of the art models will provider better quality test data generation.
# Initialise personas and generator
#https://docs.ragas.io/en/stable/howtos/customizations/testgenerator/_persona_generator/#personas-in-testset-generation
personas = [
Persona(
name="Technical Analyst",
role_description="Focuses on detailed system specifications and API documentation"
),
Persona(
name="Novice User",
role_description="Asks simple questions using layman terms and basic functionality"
),
Persona(
name="Security Auditor",
role_description="Focuses on compliance, data protection, and access control aspects"
),
Persona(
name="Docker expert",
role_description="Has in depth experience with Docker and DSocker compose and expert at cloud native concepts"
)
]
generator_llm = LangchainLLMWrapper(ChatOpenAI(model=openai_model, temperature=0.1))
generator_embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings())
generator = TestsetGenerator(
llm=generator_llm,
embedding_model=generator_embeddings,
persona_list=personas
)
# Initialise query distribution and generate dataset.
# https://docs.ragas.io/en/stable/references/synthesizers/
from ragas.testset.synthesizers import (
SingleHopSpecificQuerySynthesizer,
MultiHopAbstractQuerySynthesizer,
MultiHopSpecificQuerySynthesizer
)
query_distribution = [
(SingleHopSpecificQuerySynthesizer(), 0.4), # Simple questions
(MultiHopSpecificQuerySynthesizer(), 0.4), # Complex questions
(MultiHopAbstractQuerySynthesizer(), 0.2) # Reasoning questions
]
dataset = generator.generate_with_langchain_docs(
docs,
testset_size=100,
query_distribution=query_distribution
)
Generated test dataset contains the following columns:
- user_input : The question we will pass to our RAG system.
- reference_contexts: The reference context that would be retrieved in the ideal case for the given question.
- reference: The ideal response to the user input.
- synthesizer_name: The type of synthesiser used to generate the row. (single hop, multiple hop abstract, multi hop specific.
SingleHopSpecificQuerySynthesizer
RAGAS uses a knowledge graph based approach to passing the documents to create test dataset. A single hop specific query synthesiser will use only one node from the graph(headlines or key phrases) to generate query. Single hop in this context means using a single node from a knowledge graph built from the input document.
Example question:
"How does .NET Aspire manage launch profiles for ASP.NET Core service projects?"
MultiHopSpecificQuerySynthesizer
Similar to previous synthesiser, this also uses specific properties. However this is achieved by using multiple chunks that overlap with each other. These would require the retrieval process to be able to retrieve multiple documents or sections to build the expected context.
Example question:
How does the Azure SDK impact the ability to run Azure services locally in containers and provision infrastructure using .NET Aspire?
MultiHopAbstractQuerySynthesizer
Intends to provide generalised (abstract) queries using multiple notes of the document.
Example question:
How can a custom command be created and tested in .NET Aspire to clear the cache of a Redis resource?

Generated test data available via Github Repository
The notebook to generate the test data is also accessible via GitHub Repository
RAG Pipeline (.NET)
- Ingestion:
- For each Embedding model:
- Create a vector store for persistence.
- Generate embeddings using the current Embedding model and add them to the given Vector store matching the embedding model name.
- Retrieval and Generation
- Request specifies embedding model and generation model
- Retrieve using the vector store named after the requested embedding model
- Use the contest with the desired Generative model from the request.
- Semantic Kernel simplified this by allowing keyed registration support multiple embedding and chat models via .NET Dependency Injection.
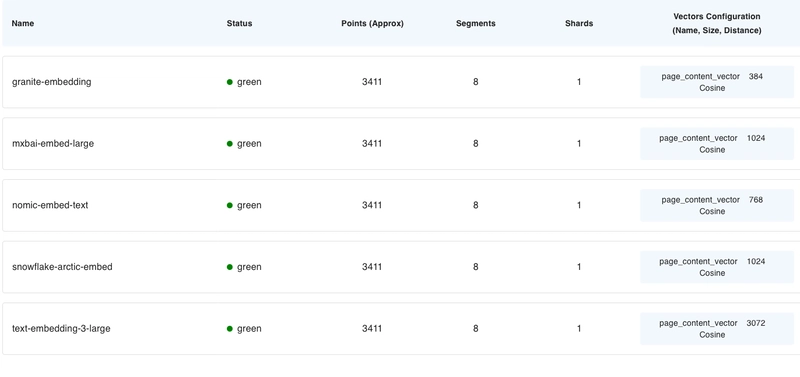
The vector stores for embedding models can be seen below:
Evaluation Run
This is achieved using Python as RAGAS is a Python library. Evaluation is performed as following:
- Pick n (5) random entries from eval dataset
- For each embedding model
- For each generative model
- Call our API to get embeddings (context) using vector search
- Call our API to run RAG query and return answer.
- Set the
retrieved_contextsandresponsein the eval dataset. - Generate the data and run evaluation.
RAG Evaluation Dataset Structure
| Column Name | Description |
|---|---|
| user_input | Generated question used to query the system |
| reference_contexts | Reference context documents generated prior to evaluation |
| retrieved_contexts | Actual context documents returned from the API during runtime |
| reference | Reference answer generated prior to evaluation (ground truth) |
| response | Actual response generated by the RAG system during evaluation |
| embedding_model | The embedding model used for retrieval (e.g., text-embedding-3-large) |
| chat_model | The generative model used to produce the final response (e.g., ChatGPT-4o) |
code example:
# Retrieve context for evaluation (vector search) using eval input from the current dataset row.
endpoint = f"{base_url}/vector-search"
params = {
"query": query,
"embeddingModel": embedding_model
}
# RAG query using the eval query, current embedding model and current generative model
endpoint = f"{base_url}/chat-with-context"
params = {
"query": query,
"embeddingModel": embedding_model,
"chatModel": chat_model
}
Full code available at GitHub Repository](https://github.com/syamaner/moonbeans/blob/bulk-performance_evaluation/src/AspireRagDemo.AppHost/Jupyter/Notebooks/evaluation.ipynb)
Results
Embedding and LLM Model Performance Comparison
In terms of faithfulness score, "mxbai-embed-large (335M params)" and chatgpt-4o-latest comes on top. On the third place, an open source and local combination nomic-embed-text 137m with llama3.2 3b provides 93.6 Semantic similarity and 84.3% non Faithfulness score. Given these are free and open source models running in quantised mode locally, these results are impressive.
Embedding and LLM Model Performance Comparison
Performance metrics ordered by faithfulness score
| Embedding Model | Chat Model | Faithfulness | Semantic Similarity |
|---|---|---|---|
| mxbai-embed-large 335m | chatgpt-4o-latest | 89.29% | 94.08% |
| text-embedding-3-large | llama3.2 3b | 84.56% | 93.49% |
| nomic-embed-text 137m | llama3.2 3b | 84.33% | 93.65% |
| nomic-embed-text 137m | phi3 3.8b | 82.97% | 93.81% |
| mxbai-embed-large 335m | llama3.2 3b | 81.59% | 94.33% |
| text-embedding-3-large | phi3 3.8b | 78.01% | 94.12% |
| mxbai-embed-large 335m | gemma 7b | 76.25% | 93.47% |
| text-embedding-3-large | deepseek-r1 7b | 76.03% | 95.77% |
| text-embedding-3-large | phi4 14b | 74.76% | 90.42% |
| nomic-embed-text 137m | gemma 7b | 74.17% | 93.99% |
| mxbai-embed-large 335m | phi3 3.8b | 73.84% | 93.22% |
| mxbai-embed-large 335m | phi4 14b | 73.68% | 94.64% |
| mxbai-embed-large 335m | deepseek-r1 7b | 68.70% | 89.88% |
| text-embedding-3-large | chatgpt-4o-latest | 68.53% | 95.70% |
| nomic-embed-text 137m | phi4 14b | 66.32% | 89.36% |
| text-embedding-3-large | gemma 7b | 64.29% | 94.74% |
| nomic-embed-text 137m | deepseek-r1 7b | 62.79% | 93.24% |
| nomic-embed-text 137m | chatgpt-4o-latest | 61.33% | 94.01% |
Note: Table shows embedding and LLM model combinations sorted by faithfulness score. Bold rows indicate top performers.
Key Takeaways
- Open source models can be competitive
mxbai-embed-large outperformed OpenAI's premium text-embedding-3-large in faithfulness metrics when paired with ChatGPT-4o.
- Small models can be mighty
Local 3B-parameter models like llama3.2 achieved 93.6% semantic similarity, proving even quantised and smaller models have recently become more powerful.
- The Hidden Cost of Accuracy
OpenAI's top-performing combination (text-embedding-3-large + ChatGPT-4o) had 68.53% faithfulness vs. open source alternatives 89.29% - a critical tradeoff between commercial API provider costs and local precision.
- Microsoft is investing on AI with .Net Platform
We can now build a RAG system and achieve decent performance using nearly out of the box implementation. .NET Aspire takes this even further giving a flexible local development environment where we can mix and match the hosts for local inference as a container, host machine or over local network.
Future
The results are based on out of the box code for ingestion, generation as well as test data generation and first step towards establishing a baseline.
Given the evaluation process uses OpenAI API, it is costly to perform evaluation on a large dataset for hobby purposes. The next steps I would ideally follow are:
- Use larger proportion of dataset (100 questions).
- Pick 2 embedding models and 3 generative models.
- Run the tests to establish baseline.
- Start experimenting with prompts and versioning.
- Run evaluation again.
- Consider further tests using different chunking, retrieval / reranking strategies and compare the results.
- If using a local llm as a judge proves effective, carry on the experiments using local models on a larger scale.