












































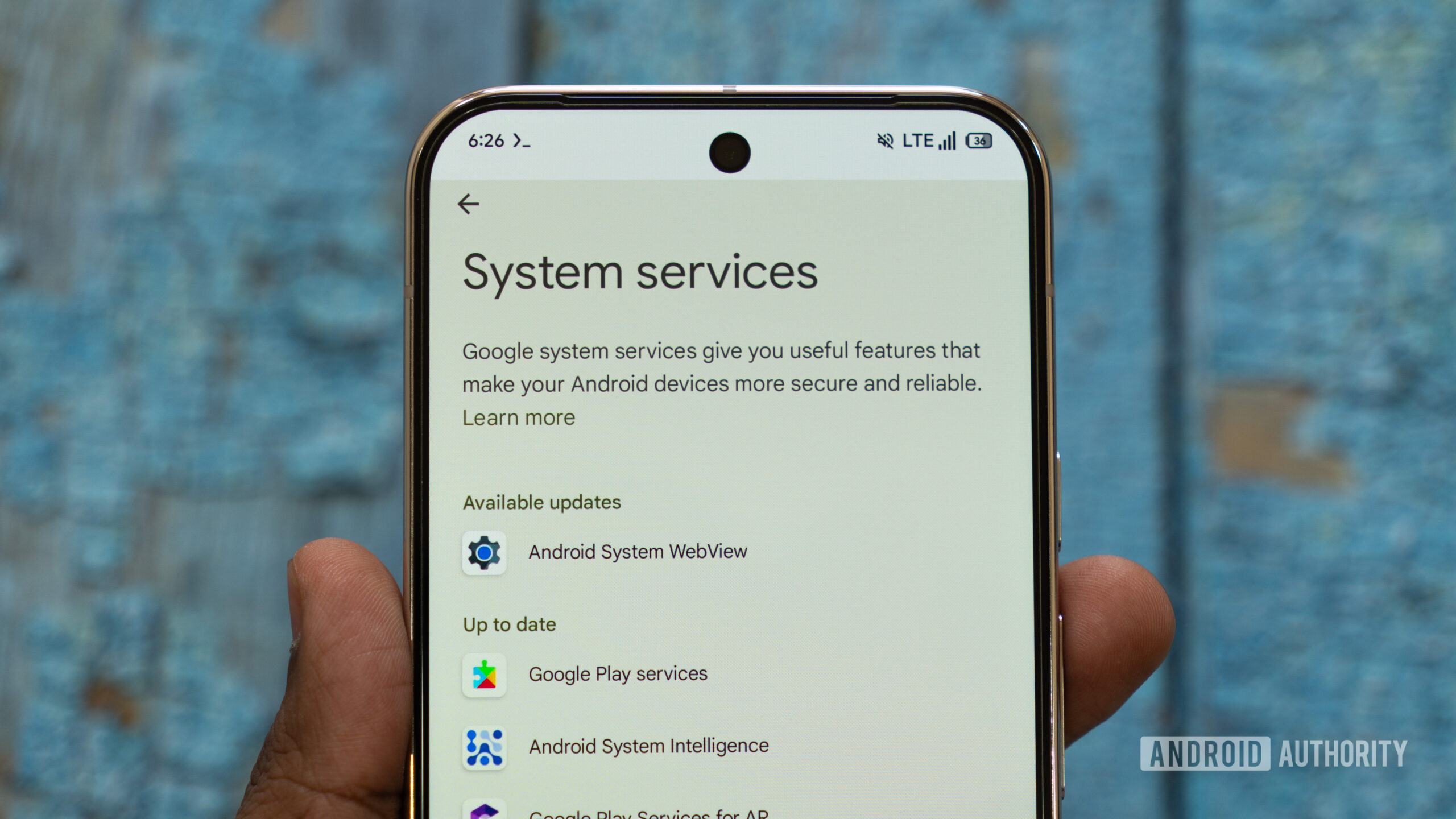
![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
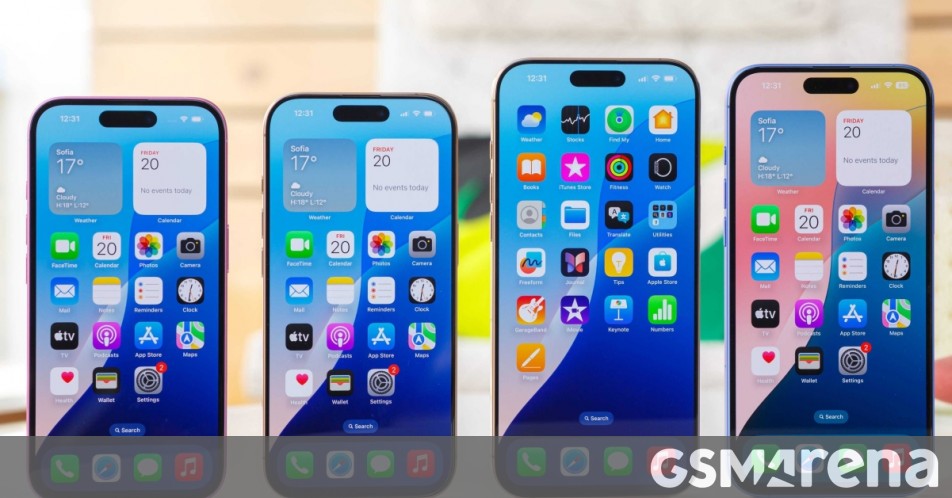
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)











![[Fixed] Chromecast (2nd gen) and Audio can’t Cast in ‘Untrusted’ outage](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/08/chromecast_audio_1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)























































































































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)








































































































































































































Beyond Words: Mastering Sentence Embeddings for Semantic NLP
So, we've already learned about word embeddings. You get Word2Vec, GloVe, and the contextual magic of BERT. You understand how individual words can be represented as vectors, capturing semantic relationships and context. Fantastic! But what if you need to understand the meaning of entire sentences? What if your NLP task isn't about individual words, but about comparing documents, finding similar questions, or classifying whole paragraphs? This is where Sentence Embeddings step into the spotlight. Why Sentence Embeddings? You already know that word embeddings, especially contextual ones, are powerful. But for many NLP tasks, focusing solely on words is like trying to understand a symphony by only listening to individual notes. You miss the melody, the harmony, the overall meaning. Here’s why sentence embeddings are crucial: 1. Capturing Holistic Meaning Sentences convey meaning that is more than just the sum of their words. Sentence embeddings aim to capture this holistic, compositional meaning. Think of idioms or sarcasm — word-level analysis often falls short. 2. Semantic Similarity at Scale Want to find similar documents, questions, or paragraphs? Sentence embeddings allow you to compare texts semantically, not just lexically (by words). This is essential for tasks like: Semantic Search: Finding relevant information even if keywords don't match exactly. Document Clustering: Grouping documents by topic, not just keyword overlap. Paraphrase Detection: Identifying sentences that mean the same thing, even with different wording. 3. Task-Specific Applications Many advanced NLP applications inherently operate at the sentence or document level: Question Answering: Matching questions to relevant passages. Text Classification (Topic, Sentiment): Classifying entire documents based on their overall content. Natural Language Inference (NLI): Understanding relationships between sentences (entailment, contradiction, neutrality). Word embeddings are the atoms of language; sentence embeddings are the molecules. To understand complex semantic structures, we need to work at the sentence level, and sentence embeddings provide the tools to do just that. Constructing Sentence Embeddings: From Context to Sentence Vectors You’re familiar with contextual embeddings from models like BERT. Now, let's see how we build upon that foundation to create sentence embeddings. Building on Contextual Embeddings: We start with contextual word embeddings (like those from BERT). The core challenge is how to aggregate these word-level vectors into a single vector that represents the entire sentence. This aggregation process is called pooling. Pooling Strategies: The Key to Sentence Vectors Simple Pooling (Baselines — Often Less Effective): Average Pooling (Mean Pooling): The most straightforward approach. Average all the contextual word embeddings in a sentence. Easy to compute but can lose crucial information about word order and importance. Max Pooling: Take the element-wise maximum across all word embeddings. Can highlight salient features but may miss contextual nuances. Transformer-Specific Pooling (Leveraging Model Architecture): [CLS] Token Pooling (BERT-style models): The special [CLS] token in BERT is the final hidden state designed to represent the entire input sequence. Using the [CLS] token's output vector as the sentence embedding is a common and often effective technique, especially for models pre-trained with tasks like next sentence prediction. The pooler_output (a processed version of the [CLS] token embedding) is often preferred over the raw [CLS] embedding itself. Sentence Transformer Pooling (Optimized for Sentence Semantics): Mean Pooling with Sentence Transformers: Sentence Transformer models, like all-MiniLM-L6-v2, often employ mean pooling of all token embeddings (excluding special tokens) combined with normalization. This strategy is highly effective for generating general-purpose sentence embeddings. Sentence Transformers are specifically trained to create semantically meaningful sentence vectors using techniques like Siamese and Triplet networks with loss functions designed to bring embeddings of similar sentences closer together and embeddings of dissimilar sentences further apart. Sentence Transformers: Models Designed for Sentence Embeddings The Sentence Transformers library is a game-changer for sentence embeddings. It provides pre-trained models and tools specifically designed to produce high-quality sentence vectors efficiently. Instead of just taking a general-purpose transformer model like BERT and applying pooling, Sentence Transformers are trained using Siamese or Triplet network architectures with objectives that directly optimize for semantic similarity. They are fine-tuned on sentence pair datasets (like Natural Language Inference datasets) to learn represen
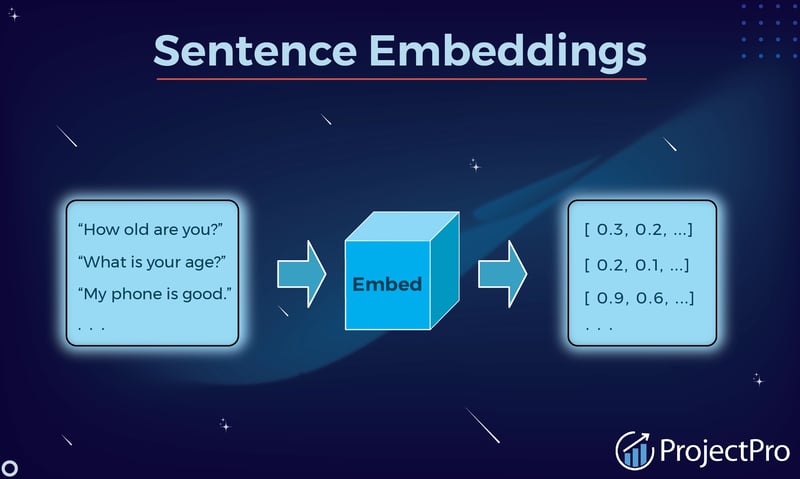
So, we've already learned about word embeddings. You get Word2Vec, GloVe, and the contextual magic of BERT. You understand how individual words can be represented as vectors, capturing semantic relationships and context. Fantastic!
But what if you need to understand the meaning of entire sentences? What if your NLP task isn't about individual words, but about comparing documents, finding similar questions, or classifying whole paragraphs?
This is where Sentence Embeddings step into the spotlight.
Why Sentence Embeddings?
You already know that word embeddings, especially contextual ones, are powerful. But for many NLP tasks, focusing solely on words is like trying to understand a symphony by only listening to individual notes. You miss the melody, the harmony, the overall meaning.
Here’s why sentence embeddings are crucial:
1. Capturing Holistic Meaning
Sentences convey meaning that is more than just the sum of their words. Sentence embeddings aim to capture this holistic, compositional meaning. Think of idioms or sarcasm — word-level analysis often falls short.
2. Semantic Similarity at Scale
Want to find similar documents, questions, or paragraphs? Sentence embeddings allow you to compare texts semantically, not just lexically (by words). This is essential for tasks like:
- Semantic Search: Finding relevant information even if keywords don't match exactly.
- Document Clustering: Grouping documents by topic, not just keyword overlap.
- Paraphrase Detection: Identifying sentences that mean the same thing, even with different wording.
3. Task-Specific Applications
Many advanced NLP applications inherently operate at the sentence or document level:
- Question Answering: Matching questions to relevant passages.
- Text Classification (Topic, Sentiment): Classifying entire documents based on their overall content.
- Natural Language Inference (NLI): Understanding relationships between sentences (entailment, contradiction, neutrality).
Word embeddings are the atoms of language; sentence embeddings are the molecules. To understand complex semantic structures, we need to work at the sentence level, and sentence embeddings provide the tools to do just that.
Constructing Sentence Embeddings: From Context to Sentence Vectors
You’re familiar with contextual embeddings from models like BERT. Now, let's see how we build upon that foundation to create sentence embeddings.
Building on Contextual Embeddings:
We start with contextual word embeddings (like those from BERT). The core challenge is how to aggregate these word-level vectors into a single vector that represents the entire sentence. This aggregation process is called pooling.
Pooling Strategies: The Key to Sentence Vectors
Simple Pooling (Baselines — Often Less Effective):
- Average Pooling (Mean Pooling): The most straightforward approach. Average all the contextual word embeddings in a sentence. Easy to compute but can lose crucial information about word order and importance.
- Max Pooling: Take the element-wise maximum across all word embeddings. Can highlight salient features but may miss contextual nuances.
Transformer-Specific Pooling (Leveraging Model Architecture):
[CLS] Token Pooling (BERT-style models): The special
[CLS]token in BERT is the final hidden state designed to represent the entire input sequence. Using the[CLS]token's output vector as the sentence embedding is a common and often effective technique, especially for models pre-trained with tasks like next sentence prediction. The pooler_output (a processed version of the[CLS]token embedding) is often preferred over the raw[CLS]embedding itself.Sentence Transformer Pooling (Optimized for Sentence Semantics):
Mean Pooling with Sentence Transformers: Sentence Transformer models, likeall-MiniLM-L6-v2, often employ mean pooling of all token embeddings (excluding special tokens) combined with normalization. This strategy is highly effective for generating general-purpose sentence embeddings. Sentence Transformers are specifically trained to create semantically meaningful sentence vectors using techniques like Siamese and Triplet networks with loss functions designed to bring embeddings of similar sentences closer together and embeddings of dissimilar sentences further apart.
Sentence Transformers: Models Designed for Sentence Embeddings
The Sentence Transformers library is a game-changer for sentence embeddings. It provides pre-trained models and tools specifically designed to produce high-quality sentence vectors efficiently.
Instead of just taking a general-purpose transformer model like BERT and applying pooling, Sentence Transformers are trained using Siamese or Triplet network architectures with objectives that directly optimize for semantic similarity. They are fine-tuned on sentence pair datasets (like Natural Language Inference datasets) to learn representations that are excellent for tasks like semantic search and clustering.
Why Sentence Transformers Are Often Preferred:
- Optimized for Semantic Similarity: Trained explicitly to produce embeddings that are semantically meaningful for sentence comparison.
- Efficiency: Often faster and more efficient for generating sentence embeddings compared to using raw transformer models and manual pooling.
- Ease of Use: The sentence-transformers library makes it incredibly easy to load pre-trained models and generate sentence embeddings with just a few lines of code.
Evaluating Sentence Embedding Quality: Are They Really Semantic?
Creating sentence embeddings is only half the battle. How do we ensure they are actually good at capturing semantic meaning? Rigorous evaluation is crucial.
Evaluation Methods — Beyond Word-Level Metrics
Intrinsic Evaluation (Directly Assessing Embeddings):
- Semantic Textual Similarity (STS) Benchmarks: Measure how well the cosine similarity (or other distance metrics) between sentence embeddings correlates with human judgments of semantic similarity. Higher correlation = better semantic representation.
Extrinsic Evaluation (Task-Based Validation — The Gold Standard):
Evaluate embeddings on downstream NLP tasks that rely on semantic understanding:
- Semantic Search & Information Retrieval: Do embeddings improve the relevance of search results compared to keyword-based methods? Metrics: Precision, Recall, NDCG.
- Paraphrase Detection: How accurately do embeddings help identify paraphrases? Metrics: Accuracy, F1-score.
- Text Classification (Sentence/Document Level): Do embeddings improve classification accuracy for tasks like sentiment analysis, topic classification? Metrics: Accuracy, F1-score, AUC.
- Clustering: Do semantically similar sentences cluster together when using their embeddings? Metrics: Cluster purity, Silhouette score.
- Natural Language Inference (NLI): How well do embeddings help determine the relationship between sentence pairs (entailment, contradiction, neutrality)? Metrics: Accuracy.
MTEB (Massive Text Embedding Benchmark):
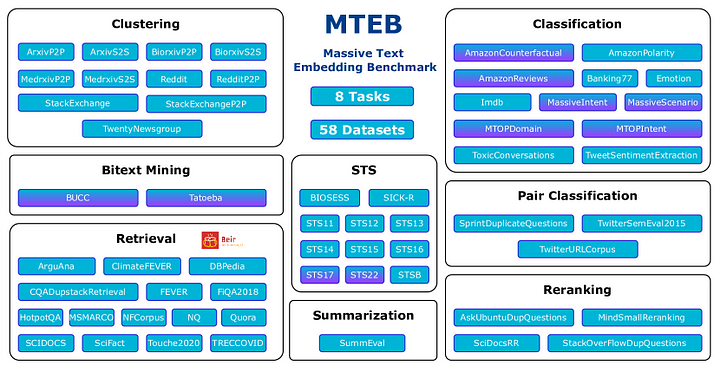
The most comprehensive and widely used benchmark for sentence embeddings. Provides a standardized and rigorous evaluation across a wide range of tasks and languages. Use the MTEB Leaderboard to compare different models objectively.
Key Evaluation Considerations:
- Task Alignment: Choose evaluation tasks that are relevant to your intended application.
- Benchmark Datasets: Use standard benchmark datasets (like STS, NLI datasets, MTEB datasets) for fair comparisons.
- Metrics: Select appropriate evaluation metrics that quantify performance on your chosen tasks.
- Ablation Studies: Experiment with different pooling strategies, model architectures, and fine-tuning approaches to understand what factors contribute most to embedding quality.
Sentence Embeddings in Action: Real-World Semantic Applications
Sentence embeddings are not just theoretical constructs — they are the workhorses behind a wide range of powerful semantic NLP applications.
Unleashing Semantic Understanding:
Semantic Search Engines: Imagine search that understands the meaning of your query, not just keywords. Sentence embeddings make this possible. Search engines can retrieve documents that are semantically related to your query, even if they don't contain the exact search terms. This leads to far more relevant and satisfying search experiences.
Document Similarity and Clustering: Need to organize large document collections? Sentence embeddings allow you to group documents based on semantic similarity, creating meaningful clusters by topic or theme. This is invaluable for topic modeling, document organization, and knowledge discovery. Imagine automatically grouping news articles by topic or clustering customer reviews to identify common themes.
Enhanced Recommendation Systems: Move beyond simple collaborative filtering or keyword-based recommendations. Sentence embeddings allow recommender systems to understand the semantic content of user preferences and item descriptions. Recommend movies based on plot similarity, suggest products based on semantic descriptions, leading to more personalized and relevant recommendations.
Paraphrase Detection and Plagiarism Checking: Easily identify sentences or passages that convey the same meaning, even if they use different words and sentence structures. Sentence embeddings are essential for paraphrase detection, duplicate content identification, and plagiarism detection systems. Clean up question-answer forums, identify redundant information, and ensure originality of text content.
Cross-lingual Applications: Multilingual sentence embeddings enable seamless cross-lingual applications. Search for information in one language and retrieve documents in another. Translate documents more effectively by understanding semantic relationships across languages. Break down language barriers and access information and knowledge across the globe.
These are just a few examples. Sentence embeddings are rapidly becoming a foundational technology in NLP, empowering a new generation of intelligent and semantically aware applications.
Level Up Your NLP Skills with Sentence Embeddings
Sentence embeddings are a cornerstone of modern semantic NLP. They empower machines to understand meaning at the sentence and document level, opening doors to a vast array of intelligent applications. By mastering sentence embeddings, you're equipping yourself with a powerful tool to tackle complex NLP challenges and build truly semantic-aware systems.
Go beyond words, embrace sentence embeddings, and unlock a deeper level of language understanding in your NLP projects! Let me know in the comments what amazing applications you build!