




































![Beats Studio Pro Wireless Headphones Now Just $169.95 - Save 51%! [Deal]](https://www.iclarified.com/images/news/97258/97258/97258-640.jpg)















![Honor 400 series officially launching on May 22 as design is revealed [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/05/honor-400-series-announcement-1.png?resize=1200%2C628&quality=82&strip=all&ssl=1)




























































































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)































































































































































































































































Chaos Engineering in Kubernetes: 5 Real-World Experiments to Try Today
In today’s fast-paced digital world, distributed systems have become the backbone of modern applications. However, their complexity also makes them vulnerable to unpredictable failures. Chaos engineering provides a proactive approach to building resilience by intentionally injecting faults and observing how systems respond. This practice enables teams to uncover hidden weaknesses and prepare for real-world disruptions before they escalate into critical incidents. It’s important to note that chaos engineering is different from traditional software testing. While testing verifies that a system works as expected under normal conditions, chaos engineering deliberately introduces failure to evaluate how resilient the system is under stress. In this article, I’ll be using Chaos Mesh—a Kubernetes-native chaos engineering tool—to demonstrate how faults can be injected into a Kubernetes ecosystem to improve its resilience. I’ll walk through its architecture and highlight common chaos experiments you can perform using Chaos Mesh. Chaos Mesh: Bringing Chaos Engineering to Kubernetes Chaos Mesh is a CNCF open-source project that implements chaos engineering concepts specifically for Kubernetes environments. It achieves this by injecting faults and abnormalities into a Kubernetes cluster or a physical node to analyze how workloads and the environment perform under different failure scenarios. Chaos Mesh Architecture Chaos Mesh leverages Kubernetes Custom Resource Definitions (CRDs) to perform chaos engineering in a Kubernetes environment. Different CRD types are used based on the specific fault being injected, and various controllers manage these CRD objects. Chaos Mesh consists of three primary components: Chaos Dashboard: A major component that provides a user-friendly interface for visualizing and experimenting with different types of chaos. The dashboard leverages CRDs and enables users to select and induce chaos experiments into the system. Additionally, it supports Role-Based Access Control (RBAC) to grant users specific permissions. Chaos Controller Manager: This component is responsible for scheduling and monitoring chaos experiments. It injects faults into the system through the Kubernetes API and monitors system responses. It includes different controllers such as the workflow controller, scheduler controller, and controllers for various fault types. Chaos Daemon: The main execution component of Chaos Mesh. Running in DaemonSet mode with privileged permissions (which can be disabled), Chaos Daemon interacts with network devices, file systems, and kernels by modifying the target Pod Namespace. Chaos Mesh Architecture With Chaos Mesh, we can perform different types of chaos simulations on both nodes and Kubernetes environments. Chaos Experiments in Kubernetes Pod Fault Simulation: This involves injecting pod crashes, deletions, or restarts using PodChaos in Chaos Mesh. Network Fault Simulation: This experiment simulates network outages within a cluster, packet drops, and bandwidth limitations between nodes. This is done using NetworkChaos. Resource Stress Simulation: This experiment stresses CPU, memory, or disk resources in the cluster. It is implemented using StressChaos. HTTP Fault Simulation: This experiment introduces HTTP faults such as aborting or delaying HTTP connections, modifying HTTP request parameters, or altering response content. It is implemented using HTTPChaos. Additionally, several other chaos experiments can be performed in Kubernetes. Chaos Experiments on Physical Nodes For physical nodes, Chaos Mesh provides Chaosd, a tool that enables experimentation with different failure scenarios, including: Process Fault Simulation: Killing or stopping a process to observe its impact on the environment. Resource Pressure Simulation: Applying stress to CPU, memory, and disk resources on each node. Host-Level Injection: Shutting down or restarting a node within a cluster to simulate failures. Instrumentation with Chaos Mesh Using Kubernetes Chaos Mesh is a powerful chaos engineering tool designed for Kubernetes environments. It can be used across different Kubernetes setups, whether you're running on cloud platforms like EKS, GKE or AKS, or using local solutions like Minikube, kubeadm or kind (local-setup-guide). Step 1: Install Chaos Mesh Install via curl: curl -sSL https://mirrors.chaos-mesh.org/v2.7.1/install.sh | bash Or use helm (Recommended for production) Step 2: Verify the Installation kubectl get po -n chaos-mesh This confirms that the core components—dashboard, controller-manager, and chaos-daemon—are running. Step 3: Access the Chaos Mesh Dashboard kubectl port-forward -n chaos-mesh svc/chaos-dashboard 2333:2333 Step 4: Deploy a simple application on the cluster for chaos experiment To conduct chaos experiments, we will deplo
In today’s fast-paced digital world, distributed systems have become the backbone of modern applications. However, their complexity also makes them vulnerable to unpredictable failures. Chaos engineering provides a proactive approach to building resilience by intentionally injecting faults and observing how systems respond. This practice enables teams to uncover hidden weaknesses and prepare for real-world disruptions before they escalate into critical incidents. It’s important to note that chaos engineering is different from traditional software testing. While testing verifies that a system works as expected under normal conditions, chaos engineering deliberately introduces failure to evaluate how resilient the system is under stress.
In this article, I’ll be using Chaos Mesh—a Kubernetes-native chaos engineering tool—to demonstrate how faults can be injected into a Kubernetes ecosystem to improve its resilience. I’ll walk through its architecture and highlight common chaos experiments you can perform using Chaos Mesh.
Chaos Mesh: Bringing Chaos Engineering to Kubernetes
Chaos Mesh is a CNCF open-source project that implements chaos engineering concepts specifically for Kubernetes environments. It achieves this by injecting faults and abnormalities into a Kubernetes cluster or a physical node to analyze how workloads and the environment perform under different failure scenarios.
Chaos Mesh Architecture
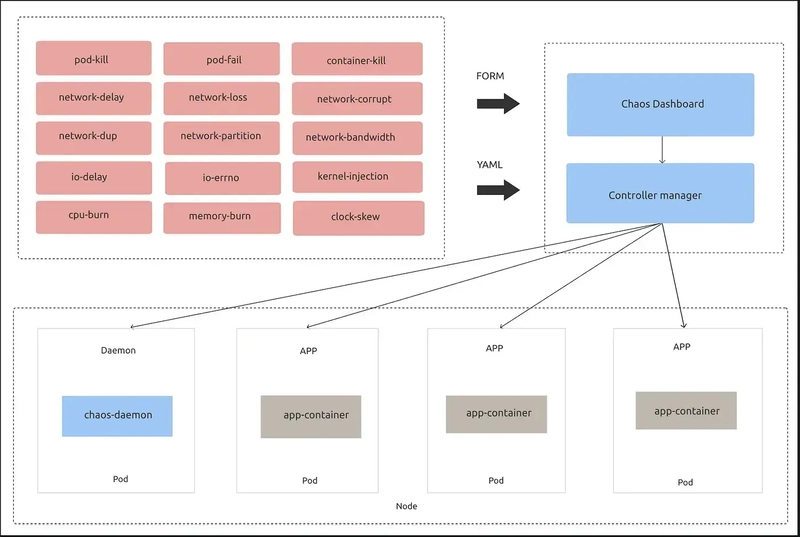
Chaos Mesh leverages Kubernetes Custom Resource Definitions (CRDs) to perform chaos engineering in a Kubernetes environment. Different CRD types are used based on the specific fault being injected, and various controllers manage these CRD objects. Chaos Mesh consists of three primary components:
- Chaos Dashboard: A major component that provides a user-friendly interface for visualizing and experimenting with different types of chaos. The dashboard leverages CRDs and enables users to select and induce chaos experiments into the system. Additionally, it supports Role-Based Access Control (RBAC) to grant users specific permissions.
- Chaos Controller Manager: This component is responsible for scheduling and monitoring chaos experiments. It injects faults into the system through the Kubernetes API and monitors system responses. It includes different controllers such as the workflow controller, scheduler controller, and controllers for various fault types.
- Chaos Daemon: The main execution component of Chaos Mesh. Running in DaemonSet mode with privileged permissions (which can be disabled), Chaos Daemon interacts with network devices, file systems, and kernels by modifying the target Pod Namespace.
With Chaos Mesh, we can perform different types of chaos simulations on both nodes and Kubernetes environments.
Chaos Experiments in Kubernetes
- Pod Fault Simulation: This involves injecting pod crashes, deletions, or restarts using PodChaos in Chaos Mesh.
- Network Fault Simulation: This experiment simulates network outages within a cluster, packet drops, and bandwidth limitations between nodes. This is done using NetworkChaos.
- Resource Stress Simulation: This experiment stresses CPU, memory, or disk resources in the cluster. It is implemented using StressChaos.
- HTTP Fault Simulation: This experiment introduces HTTP faults such as aborting or delaying HTTP connections, modifying HTTP request parameters, or altering response content. It is implemented using HTTPChaos.
Additionally, several other chaos experiments can be performed in Kubernetes.
Chaos Experiments on Physical Nodes
For physical nodes, Chaos Mesh provides Chaosd, a tool that enables experimentation with different failure scenarios, including:
- Process Fault Simulation: Killing or stopping a process to observe its impact on the environment.
- Resource Pressure Simulation: Applying stress to CPU, memory, and disk resources on each node.
- Host-Level Injection: Shutting down or restarting a node within a cluster to simulate failures.
Instrumentation with Chaos Mesh Using Kubernetes
Chaos Mesh is a powerful chaos engineering tool designed for Kubernetes environments. It can be used across different Kubernetes setups, whether you're running on cloud platforms like EKS, GKE or AKS, or using local solutions like Minikube, kubeadm or kind (local-setup-guide).
Step 1: Install Chaos Mesh
Install via curl:
curl -sSL https://mirrors.chaos-mesh.org/v2.7.1/install.sh | bash
Or use helm (Recommended for production)
Step 2: Verify the Installation
kubectl get po -n chaos-mesh
This confirms that the core components—dashboard, controller-manager, and chaos-daemon—are running.

Step 3: Access the Chaos Mesh Dashboard
kubectl port-forward -n chaos-mesh svc/chaos-dashboard 2333:2333

Step 4: Deploy a simple application on the cluster for chaos experiment
To conduct chaos experiments, we will deploy a simple React application using Kubernetes manifest.
Now we can access the application

Chaos Experiments
Experiment 1: PodChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: custom-pod-failure-experiment
namespace: chaos-mesh
spec:
action: pod-kill
mode: all
selector:
namespaces:
- chaos-experiment
labelSelectors:
'app': 'react-app'
duration: '30s'
gracePeriod: 10
What it does:
Simulates a scenario where all matching pods are forcefully killed. This helps test the resilience and auto-recovery behavior of deployments.
Effect:
- All pods with the label app: react-app in the chaos-experiment namespace were terminated and restarted.
- The application was briefly unavailable for 30 seconds.


Experiement 2: HTTPChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: HTTPChaos
metadata:
name: custom-http-failure-experiment
spec:
mode: all
selector:
namespaces:
- chaos-experiment
labelSelectors:
app: react-app
target: Request
port: 80
method: GET
path: /
abort: true
duration: 10m
What it does:
Intercepts and aborts incoming HTTP GET requests to simulate upstream service failures or gateway crashes.
Effect:
- All HTTP GET requests to / on port 80 were blocked for 10 minutes, making the app appear down.


Experiement 3: NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: custom-network-bandwidth-failure-experiment
spec:
action: bandwidth
mode: all
selector:
namespaces:
- chaos-experiment
labelSelectors:
'app': 'react-app'
bandwidth:
rate: '2mbps'
limit: 20971520
buffer: 10000
What it does:
Limits the network bandwidth to simulate slow network conditions.
Effect:
The application’s outgoing bandwidth was restricted to 2 Mbps, with a buffer and rate limit applied.
Useful for testing frontend responsiveness or service timeouts under constrained network speeds.


Experiement 4: StressChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: custom-cpu-stress-test-experiment
spec:
mode: all # Apply chaos to all matching pods
selector:
namespaces:
- chaos-experiment
labelSelectors:
app: react-app
stressors:
cpu:
workers: 4
load: 80 # 80% CPU load on each worker
duration: 10m # Stress for 10 minutes
What it does:
Applies CPU pressure by generating artificial load on the container.
Effect:
Each matching pod experienced 80% CPU usage across 4 workers for 10 minutes.
This can uncover performance bottlenecks or autoscaling issues.


Experiement 5: TimeChaos
apiVersion: chaos-mesh.org/v1alpha1
kind: TimeChaos
metadata:
name: custom-time-shift-example-experiment
namespace: chaos-mesh
spec:
mode: all
selector:
namespaces:
- chaos-experiment
labelSelectors:
app: react-app
timeOffset: '-10m100ns'
What it does:
Shifts the system clock on the container to simulate clock skew or time drift.
Effect:
System time on each pod was shifted 10 minutes backward.
Helps test the behavior of time-sensitive features like cron jobs, auth tokens, and expiry mechanisms.

⚠ Note: TimeChaos only affects the main container process (PID 1) and its child processes. It does not impact processes launched externally using kubectl exec. Therefore, to test TimeChaos effectively, you need to observe the application’s internal behavior (logs, API responses, or time-based operations) rather than relying on external exec-based checks.
Conclusion
Chaos engineering with Chaos Mesh transforms failure into resilience by proactively testing systems under stress. By simulating real world disruptions like pod crashes and network delays you uncover weaknesses before they cause outages. This practice ensures your Kubernetes applications don’t just survive chaos but emerge stronger. In distributed systems, resilience isn’t luck, it’s engineered.