








































![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)












![[Fixed] Chromecast (2nd gen) and Audio can’t Cast in ‘Untrusted’ outage](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/08/chromecast_audio_1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)





















































































































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)





































































































![Is XMPP a good option for a messaging system in an app? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
































































































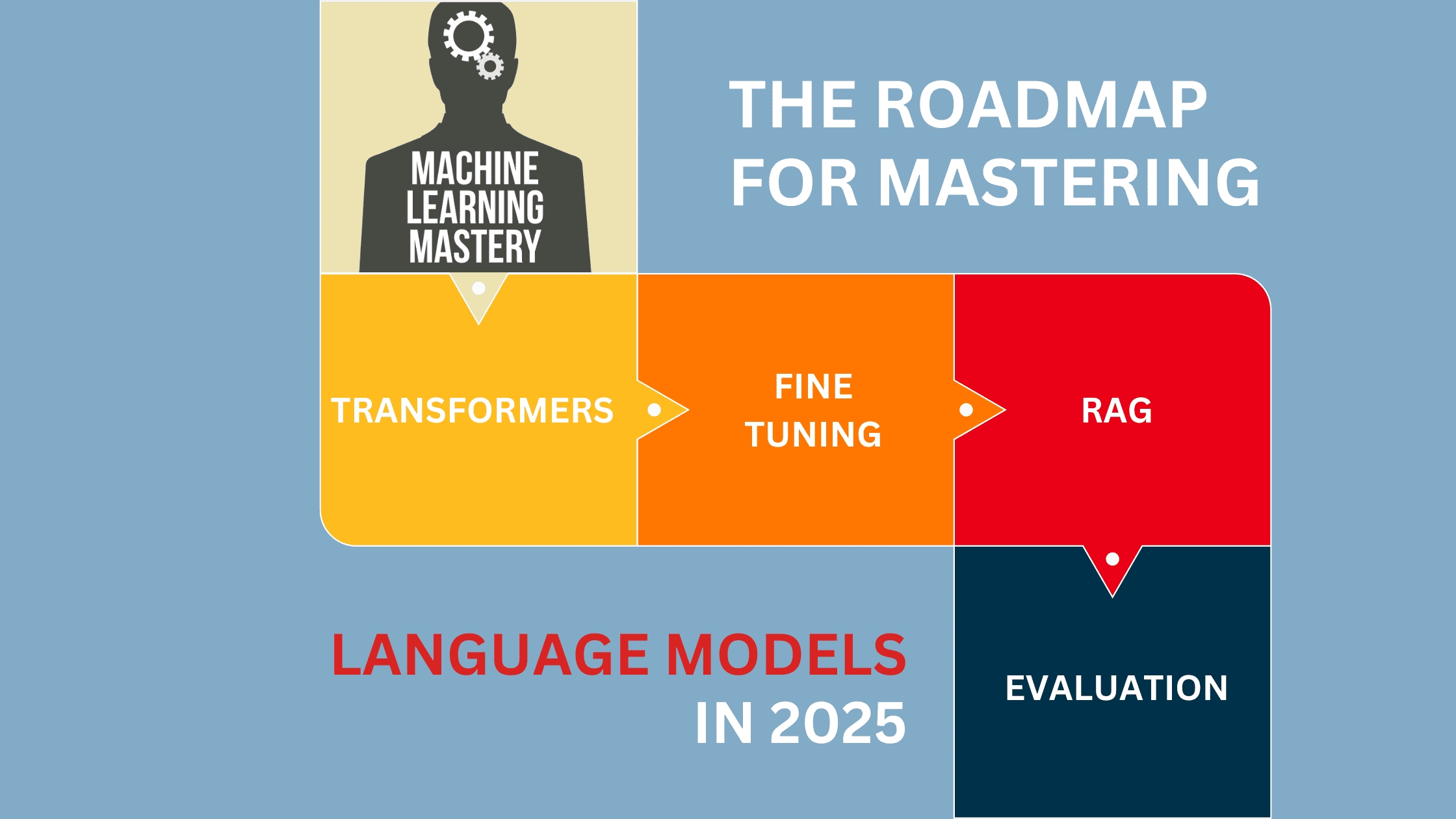
How to Crater Your Database, Part Two - Aggregations
Part One Plot spoiler As I mentioned in the introductory article to this series, the secret to cratering your database is to do things that don't scale and then try to scale. In this article, we'll discuss aggregations, one of the most common non-scalable actions you can perform with your database. The operations count, avg, min, and max are all aggregation functions. Most SQL (and many NoSQL) databases support aggregations. Some databases, like AWS DynamoDB, do not. I routinely hear engineers complain1 about DynamoDB's lack of built-in aggregations. This article stresses, "It's on purpose." Or, to put it more colloquially, "It's a feature, not a bug." Further, the two are mutually exclusive. DynamoDB scales because it doesn't support operations like aggregations. If it did, it couldn't scale. The same works in reverse; your SQL (and many NoSQL) databases will scale more predictably if you don't use aggregations. Don't use them. Aggregations are bear traps for the unwary, ready to take down your database right when you hit scale. - Alex DeBrie Why does count (and avg/sum/min/max) hurt? All database aggregation functions share the same input: all items in the set. None of them can operate on a partial result set. For example, if you ask the database, "How many User records do you have where the User lives in Maryland?" it first has to find all the records WHERE user.state = 'MD' and then iterate over that set to determine the count. If you have an index on user.state, this will be faster than if you didn't. In both cases, the number of matching users impacts the response time. The larger your dataset, the slower it will respond. Count (and its aggregate cousins) almost always deliver excellent performance during development when data sets are small. But as the number of items increases (which is what you want in Production, right? Millions of happy, paying customers), performance will suffer accordingly. Aggregate functions are time bombs that a future engineer (possibly you) must defuse. You already guard against this in your code Let's say you are reviewing some code, and you come across the following block in a colleague's change: for (let i = 0; i

Plot spoiler
As I mentioned in the introductory article to this series, the secret to cratering your database is to do things that don't scale and then try to scale. In this article, we'll discuss aggregations, one of the most common non-scalable actions you can perform with your database.
The operations count, avg, min, and max are all aggregation functions. Most SQL (and many NoSQL) databases support aggregations. Some databases, like AWS DynamoDB, do not.
I routinely hear engineers complain1 about DynamoDB's lack of built-in aggregations. This article stresses, "It's on purpose." Or, to put it more colloquially, "It's a feature, not a bug."
Further, the two are mutually exclusive. DynamoDB scales because it doesn't support operations like aggregations. If it did, it couldn't scale. The same works in reverse; your SQL (and many NoSQL) databases will scale more predictably if you don't use aggregations. Don't use them.
Aggregations are bear traps for the unwary, ready to take down your database right when you hit scale. - Alex DeBrie
Why does count (and avg/sum/min/max) hurt?
All database aggregation functions share the same input: all items in the set. None of them can operate on a partial result set. For example, if you ask the database, "How many User records do you have where the User lives in Maryland?" it first has to find all the records WHERE user.state = 'MD' and then iterate over that set to determine the count.
If you have an index on user.state, this will be faster than if you didn't. In both cases, the number of matching users impacts the response time. The larger your dataset, the slower it will respond.
Count (and its aggregate cousins) almost always deliver excellent performance during development when data sets are small. But as the number of items increases (which is what you want in Production, right? Millions of happy, paying customers), performance will suffer accordingly. Aggregate functions are time bombs that a future engineer (possibly you) must defuse.
You already guard against this in your code
Let's say you are reviewing some code, and you come across the following block in a colleague's change:
for (let i = 0; i < input.length; i++) {
for (let j = 0; j < input.length - i - 1; j++) {
if (input[j] > input[j+1]) {
let temp = input[j];
input[j] = input[j+1];
input[j+1] = temp;
};
}
}
What would come to mind (other than "Why did you re-write a bubble sort?") when you see this? My attention is immediately drawn toward the nested for loops. This has a quadratic, or O(n^2), complexity. Given a sufficiently large input, this will perform poorly. It does not scale well.
During my computer science education, this ability to spot nested for loops was drilled into me by professor after professor. Today, I hold this pattern as something to generally2 avoid. Unfortunately, we are rarely trained to avoid similar complexity traps in SQL.
Can you spot it here?
SELECT product,
SUM(revenue) AS Total_Revenue
FROM sales
GROUP BY product;
Both GROUP BY and SUM are linear, O(n) operations. As the sales table grows, these aggregations will perform slower and slower over time.
Why should anyone care?
I advocate, "You build it, you run it." If you're running a system, you want it to behave consistently at your expected loads—that is, you want it to scale predictably. If you use aggregate functions, you have relinquished a predictability variable to the user: volume. With aggregations, your system will behave differently for two customers depending on how much data each has in the database.
For example, a customer with a small online store could have dozens of orders a month. Any aggregate function over that data set will perform decently well. However, a customer with a booming online store could have thousands (or even millions) of monthly orders. For that customer, a lurking count() will become less and less performant. As the e-commerce engineer who inserts an aggregate function into your code, you optimize for your least valuable customer. How do you explain that to your CTO or your board of directors?
Worse, you are now running a system that could crater at any moment (remember, it's now customer-determined when your DB overheats). This turns on-call rotation into Russian roulette. Strive to keep your systems predictable and your on-call engineer unaffected (and well-rested).
Then, I'll use NoSQL!
You might now think, "Well, if all these SQL aggregate functions are so bad, I'll just use NoSQL." Unfortunately, with one notable exception (more on this below), this won’t let you escape the problem.
Let's take our friend count(). Popular NoSQL databases like ElasticSearch, Cassandra, MongoDB, Couchbase, and Neo4J all support it. However, each system has the same "bear trap" penalty. You don't escape the problem by just moving to NoSQL unless...
DynamoDB is different
If you pick DynamoDB as your NoSQL database, you are immune from these aggregate function time bombs precisely because it doesn't allow them. I (and many others) have written about this before. Please look at the links below in References.
DynamoDB is designed to perform consistent OLTP3 interactions whether the data set has 10 or 10,000,000,000 items. DynamoDB can scale predictably, with no "gotchas" from data volumes.
Summary
If you want to scale, aggregations are bear traps. Avoid them. Just because you can use count() doesn't mean you should. If you use SQL (or MongoDB or ElasticSearch or ...), be vigilant that aggregations don't sneak into your code base. Or you can use DynamoDB and focus on creating your company's next big hit.
Happy building!
References
Ownership Matters: Why DynamoDB Is (Still) My First Pick for Serverless
Alex DeBrie: The DynamoDB Book
Alex DeBrie: SQL, NoSQL, and Scale: How DynamoDB scales where relational databases don't
Clint Fontanella: What are Aggregate SQL Functions?
Plamen Ratchev: Ten Common SQL Programming Mistakes
-
Don't use DynamoDB as a production database, 5 reasons NOT to use DynamoDB, DynamoDB and the Art of Knowing Your Limits: When Database Bites Back ↩
-
If you know your inputs are constrained to a small size, a nested loop may well be fine ↩