































































![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)
![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)














![Foldable e-ink readers are a thing now [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/mooink-v-foldable-e-ink-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)















































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































![Building a tree(s) by combining XML, XSD, EXP files [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)













































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)




























































OpenAI Introduces the Evals API: Streamlined Model Evaluation for Developers
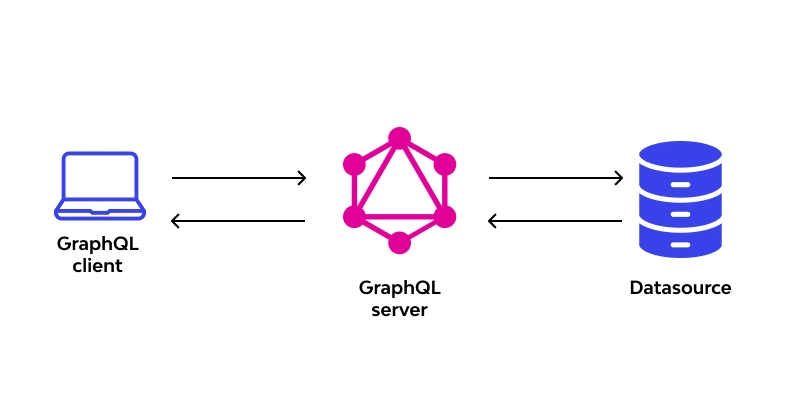
In a significant move to empower developers and teams working with large language models (LLMs), OpenAI has introduced the Evals API, a new toolset that brings programmatic evaluation capabilities to the forefront. While evaluations were previously accessible via the OpenAI dashboard, the new API allows developers to define tests, automate evaluation runs, and iterate on […] The post OpenAI Introduces the Evals API: Streamlined Model Evaluation for Developers appeared first on MarkTechPost.

In a significant move to empower developers and teams working with large language models (LLMs), OpenAI has introduced the Evals API, a new toolset that brings programmatic evaluation capabilities to the forefront. While evaluations were previously accessible via the OpenAI dashboard, the new API allows developers to define tests, automate evaluation runs, and iterate on prompts directly from their workflows.
Why the Evals API Matters
Evaluating LLM performance has often been a manual, time-consuming process, especially for teams scaling applications across diverse domains. With the Evals API, OpenAI provides a systematic approach to:
- Assess model performance on custom test cases
- Measure improvements across prompt iterations
- Automate quality assurance in development pipelines
Now, every developer can treat evaluation as a first-class citizen in the development cycle—similar to how unit tests are treated in traditional software engineering.
Core Features of the Evals API
- Custom Eval Definitions: Developers can write their own evaluation logic by extending base classes.
- Test Data Integration: Seamlessly integrate evaluation datasets to test specific scenarios.
- Parameter Configuration: Configure model, temperature, max tokens, and other generation parameters.
- Automated Runs: Trigger evaluations via code, and retrieve results programmatically.
The Evals API supports a YAML-based configuration structure, allowing for both flexibility and reusability.
Getting Started with the Evals API
To use the Evals API, you first install the OpenAI Python package:
pip install openaiThen, you can run an evaluation using a built-in eval, such as factuality_qna
oai evals registry:evaluation:factuality_qna \
--completion_fns gpt-4 \
--record_path eval_results.jsonlOr define a custom eval in Python:
import openai.evals
class MyRegressionEval(openai.evals.Eval):
def run(self):
for example in self.get_examples():
result = self.completion_fn(example['input'])
score = self.compute_score(result, example['ideal'])
yield self.make_result(result=result, score=score)This example shows how you can define a custom evaluation logic—in this case, measuring regression accuracy.
Use Case: Regression Evaluation
OpenAI’s cookbook example walks through building a regression evaluator using the API. Here’s a simplified version:
from sklearn.metrics import mean_squared_error
class RegressionEval(openai.evals.Eval):
def run(self):
predictions, labels = [], []
for example in self.get_examples():
response = self.completion_fn(example['input'])
predictions.append(float(response.strip()))
labels.append(example['ideal'])
mse = mean_squared_error(labels, predictions)
yield self.make_result(result={"mse": mse}, score=-mse)This allows developers to benchmark numerical predictions from models and track changes over time.
Seamless Workflow Integration
Whether you’re building a chatbot, summarization engine, or classification system, evaluations can now be triggered as part of your CI/CD pipeline. This ensures that every prompt or model update maintains or improves performance before going live.
openai.evals.run(
eval_name="my_eval",
completion_fn="gpt-4",
eval_config={"path": "eval_config.yaml"}
)Conclusion
The launch of the Evals API marks a shift toward robust, automated evaluation standards in LLM development. By offering the ability to configure, run, and analyze evaluations programmatically, OpenAI is enabling teams to build with confidence and continuously improve the quality of their AI applications.
To explore further, check out the official OpenAI Evals documentation and the cookbook examples.
The post OpenAI Introduces the Evals API: Streamlined Model Evaluation for Developers appeared first on MarkTechPost.







